0%
URL
TL;DR
DeepSeek 系列是国内一家名叫深度求索的科技公司推出的一种混合专家语言模型,这家公司背后是幻方量化。DeepSeek-V2 的核心思想是 Multi-head Latent Attention (MLA) 和 DeepSeekMoE 两个模块,这两个模块分别替换了传统 Transformer 层的 Attention Module 和 FFN,是本博客想要探讨的重点。
Architecture
Multi-head Latent Attention (MLA)
MLA 总体计算流程
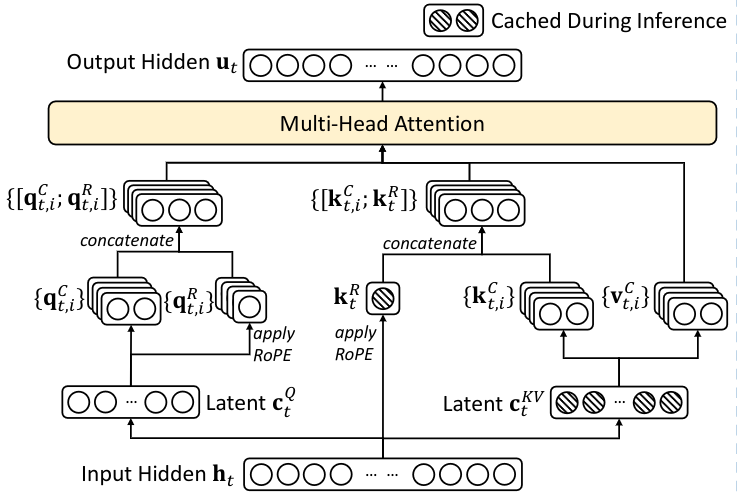
- 核心思想是将
hidden feature 通过 MLP 映射到 latent space,降低计算(attention)和存储(kv cache)的复杂度。
- 和主流的
kv cache 方案不同,MLA 只需要 cache ctKV 和 ktR 两部分。
MLA 详细计算流程
- 输入:ht∈Rd ,表示第
t 个 token 在某个 attention layer 层的输入特征
- 计算
key / value:
- ctKV=WDKVht ,其中 WDKV∈Rdc×d,
DKV 表示 down-projection key value
- ktC=WUKctKV ,其中 WUK∈Rdhnh×dc,
UK 表示 up-projection key,dc≪dhnh
- vtC=WUVctKV ,其中 WUV∈Rdhnh×dc,
UV 表示 up-projection value,dc≪dhnh
- 计算
query:
- ctQ=WDQht ,其中 WDQ∈Rdc′×d,
DQ 表示 down-projection query
- qtC=WUQctQ ,其中 WUQ∈Rdhnh×dc′,
UQ 表示 up-projection query,dc′≪dhnh
- 计算
RoPE:
RoPE 是一种在输入 attention layer 之前,对 query 和 key 做 position encoding 的方法RoPE 和 MLA 在设计上是冲突的,因此 MLA 对 RoPE 做了一些修改,主要是:额外计算 multi-head query rotary 和 shared key rotary- [qt,1R,qt,2R,...,qt,nhR]=qtR=RoPE(WQRctQ) ,其中 WQR∈RdhRnh×dc′,QR 表示
query rotary
- ktR=RoPE(WKRktC) ,其中 WKR∈RdhR×d,KR 表示
key rotary
- qt,i=[qt,iC,qt,iR] ,将
query 和 query rotary 拼接,得到正式的 query
- kt,i=[kt,iC,ktR] ,将
key 和 key rotary 拼接,得到正式的 key
- 计算
attention:
- ot,i=∑j=1tSoftmaxj(dh+dhRqt,iTkj,i)vj,iC
- 计算
output:
- ut=WO[ot,1,ot,2,...,ot,nh] ,其中 WO∈Rd×dhnh
MLA 优势
- 大幅降低了
kv cache 的存储空间

DeepSeekMoE
Thoughts
MLA 算是对 self-attention 比较深度的改进,兼顾了 kv cache 和 RoPE 的设计,比 MQA 和 GQA 设计看上去更用心。DeepSeekMoE 感觉在 GShard 上的改进并不大,主要是在 Expert 的基础上加入了 Sub-Expert 的概念,以及常开的 Isolated Shared Expert 设计。- 这二者结合,给了
DeepSeek-V2 一个很好的性能提升,可以在相同计算复杂度下,塞下更多的参数量,提高模型表现。