0%
URL
TL;DR
- 谷歌提出了一种新的模型分布策略
GShard,通过 条件计算 和 自动分片 的方式,提高了模型的训练效率和推理速度,算是大模型 MOE 的开山之作。
- 本质就是传统
MoE 替换掉 Transformer 中的 FFN 层
Architecture
总体架构
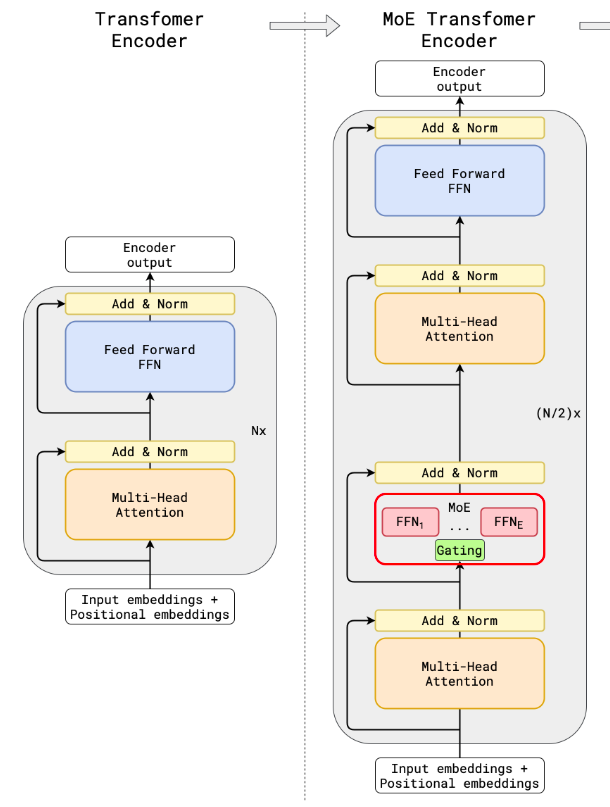
GShard 将传统 LLM 的 Transformer 层的 FFN 替换成 MOE 模块,每个 token 只激活固定数量的 expert,大幅降低了计算复杂度。GShard 的 MOE 模块分为 routing 和 expert 两部分
routing 负责选择激活的 expertexpert 负责计算 FFN 的输出。
详细计算流程
- 输入:h∈Rseq_len×dim,表示
token 序列的输入特征,seq_len 表示序列长度,dim 表示特征维度
- 经过
self-attention + norm,这一步和传统 Transformer 模型一致,输出 h′∈Rseq_len×dim
- 计算
routing:
- 计算每个
token 的 routing 分数,表示每一个 token 和每一个专家的相关程度,s=h′×Wg,其中 Wg∈Rdim×num_experts, s∈Rseq_len×num_experts
- 每个
token 取固定数量的 expert,k 表示激活的 expert 数量,k 在本文中取 2,其它非激活的 expert 的 routing 分数设为 −∞
- 将
routing 分数归一化变成概率,g=Softmax(s),g 表示 gate,表示每个 token 激活的 expert 的输出采纳程度
- 计算
expert:
- 计算当前
token 已激活的 expert 的输出,hexpert=FFN(hexpert′)
- 将
expert 的输出按照 gate 加权求和,hfinal=∑i=1kgi⋅hexperti
- 本文中
MoE Transformer layer 和标准 Transformer layer 是交替出现的
Thoughts
GShard 确实在不减小模型参数量的情况下,大幅减小计算复杂度,对于推理速度的提升有很大帮助,带动了一波 LLM-MoE 的发展。- 其中
MoE 的部分并不新颖,重点在于 MoE 放置到 Transformer Block 中确实比较有创新。