TL;DR
- 本文是大模型RAG的入门教程,不是来自某一篇
paper / survey,目的是用尽可能简单的方式介绍大模型RAG的基本概念和原理,不涉及过多实现细节。
什么是 RAG
RAG是Retrieval-Augmented Generation (检索增强生成)的缩写,目的是在生成任务中引入检索模块,将检索到的信息通过prompt模板的方式传递给生成模块,以提高生成模型的性能。
RAG 想要解决的问题
- 通常来说,
RAG想要解决的问题可以概括为三点:- 大模型知识的局限性:大模型在训练过程中只能学习到非实时的、公开的知识,对于实时的、私有的知识无法获取。
- 幻觉问题:大模型无法记住所有的信息细节,即使这些信息曾在训练数据中出现过。
- 数据安全问题:敏感私域数据用于训练大模型可能导致数据泄露,而
RAG可以通过检索模块实现数据的隔离。
RAG 的基本实现原理
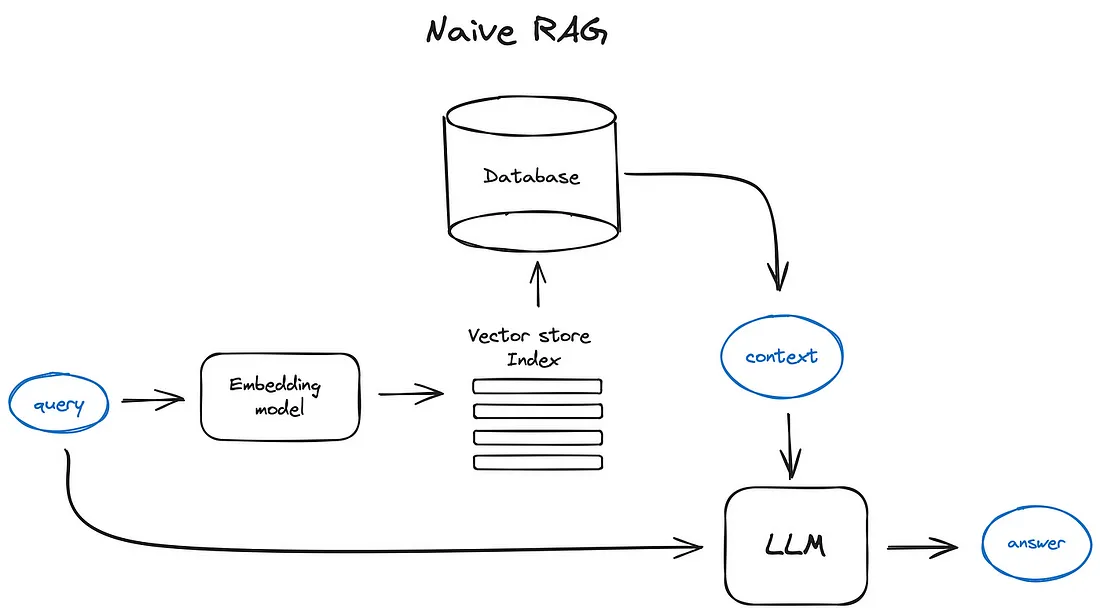
RAG要分为两步:- 数据准备阶段:
- 数据提取
- 文本切分
- 向量化
- 数据入库
- 应用阶段:
- 用户提问
- 数据检索(召回)
- 注入
prompt LLM生成答案
- 数据准备阶段:
1. 数据提取
- 数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式
- 数据处理:包括数据过滤、压缩、格式化等
- 元数据获取:提取数据中关键信息,例如文件名、
Title、时间等
2. 文本切分
- 文本切分主要考虑两个因素:
embedding模型的sequence length限制情况- 语义完整性对整体的检索效果的影响
- 一些常见的文本分割方式包括:
- 句分割:以 “句” 的粒度进行切分,保留一个句子的完整语义,常见切分符包括:句号、感叹号、问号、换行符等
- 固定长度分割:根据
embedding模型的sequence length长度限制,将文本分割为固定长度(例如256 / 512个token),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解
3. 向量化
- 向量化是将文本转换为向量的过程,目的是将不同长度的文本转换为固定长度的向量,有许多开源的
embedding模型可以使用,例如:
| 模型名称 | 描述 | 获取地址 |
|---|---|---|
| ChatGPT-Embedding | ChatGPT-Embedding由OpenAI公司提供,以接口形式调用。 | https://platform.openai.com/docs/guides/embeddings/what-are-embeddings |
| ERNIE-Embedding V1 | ERNIE-Embedding V1由百度公司提供,依赖于文心大模型能力,以接口形式调用。 | https://cloud.baidu.com/doc/WENXINWORKSHOP/s/alj562vvu |
| M3E | M3E是一款功能强大的开源Embedding模型,包含m3e-small、m3e-base、m3e-large等多个版本,支持微调和本地部署。 | https://huggingface.co/moka-ai/m3e-base |
| BGE | BGE由北京智源人工智能研究院发布,同样是一款功能强大的开源Embedding模型,包含了支持中文和英文的多个版本,同样支持微调和本地部署。 | https://huggingface.co/BAAI/bge-base-en-v1.5 |
Transformer base的模型天然可以将不同长度的文本转换为固定长度的向量,因此在向量化模型本质就是一个去掉projection头的LLM(当然训练阶段的目标设置也不同)
4. 数据入库
- 数据向量化之后,作为索引存储到专用的向量检索数据库中,常用的向量检索数据库包括:
Faiss:Facebook开源的高性能相似向量检索库,支持多种索引结构(如IVF、HNSW、PQ),不支持分布式存储和检索Milvus:Zilliz开源的分布式高性能相似向量检索库,较Faiss更为复杂,支持分布式存储和检索Chroma:Chroma AI开源的轻量化相似向量检索库ES:ElasticSearch是一款全文搜索引擎,支持文本检索,不原生支持向量检索,但可以通过插件实现
5. 用户提问
graph TD
A[User Query]
B[Generate Similar Queries By LLM]
C1[Vector Search Query 1]
C2[Vector Search Query 2]
C3[Vector Search Query 3]
C4[Vector Search Query 4]
C5[Vector Search Original Query]
D[Reciprocal Rank Fusion]
E[Re-ranked Results]
F[Generative Output]
A --> B
B --> C1
B --> C2
B --> C3
B --> C4
A --> C5
C1 --> D
C2 --> D
C3 --> D
C4 --> D
C5 --> D
D --> E
E --> F
- 大模型首先会根据用户的提问生成一系列相似的查询(或拆分查询内容等),得到一系列的检索查询,这样做的目的是为了提高检索的召回率。
6. 数据检索(召回)
- 常见的数据检索方法包括:相似性检索、全文检索等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。
- (向量)相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
- 全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过 关键词 构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录。
7. 注入 prompt
prompt是一种模板化的文本,用于将检索到的信息传递给生成模块,prompt的构建需要考虑以下几点:prompt的内容应该尽可能简洁,不应该包含过多冗余信息prompt的内容应该尽可能完整,包含检索到的信息的核心内容prompt的内容应该尽可能通用,适用于多种检索结果
- 以下是一个
prompt的示例:
1 | 【任务描述】 |
一些高级 RAG 技巧
1. 检索
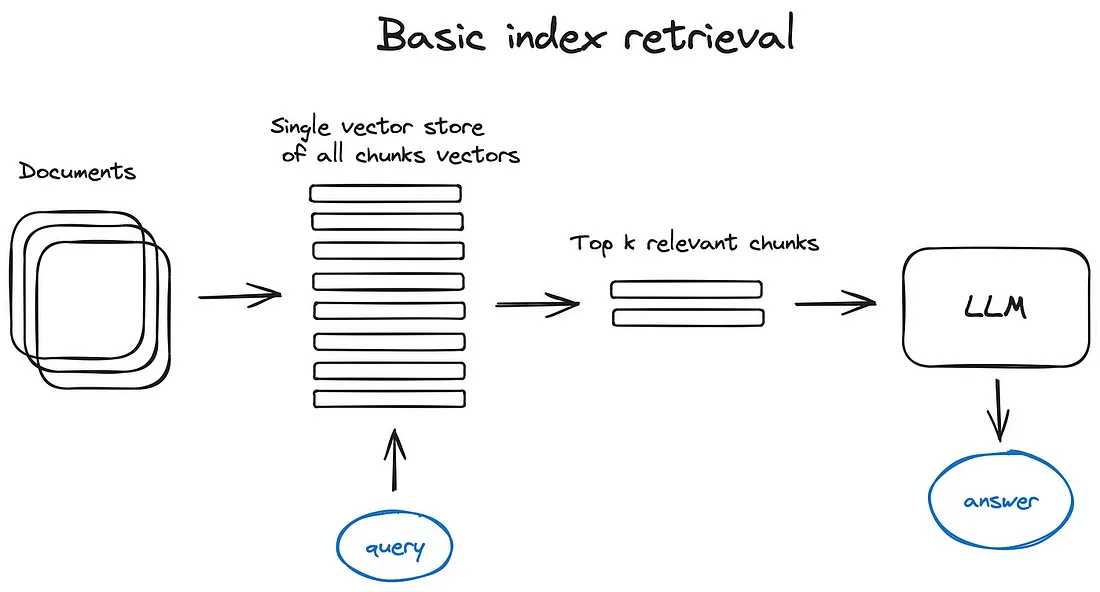
1.1 向量存储索引
- 最简答的索引方式是向量存储索引,即一段文本对应一个向量,通过向量相似性检索得到相似文本,如下图所示:
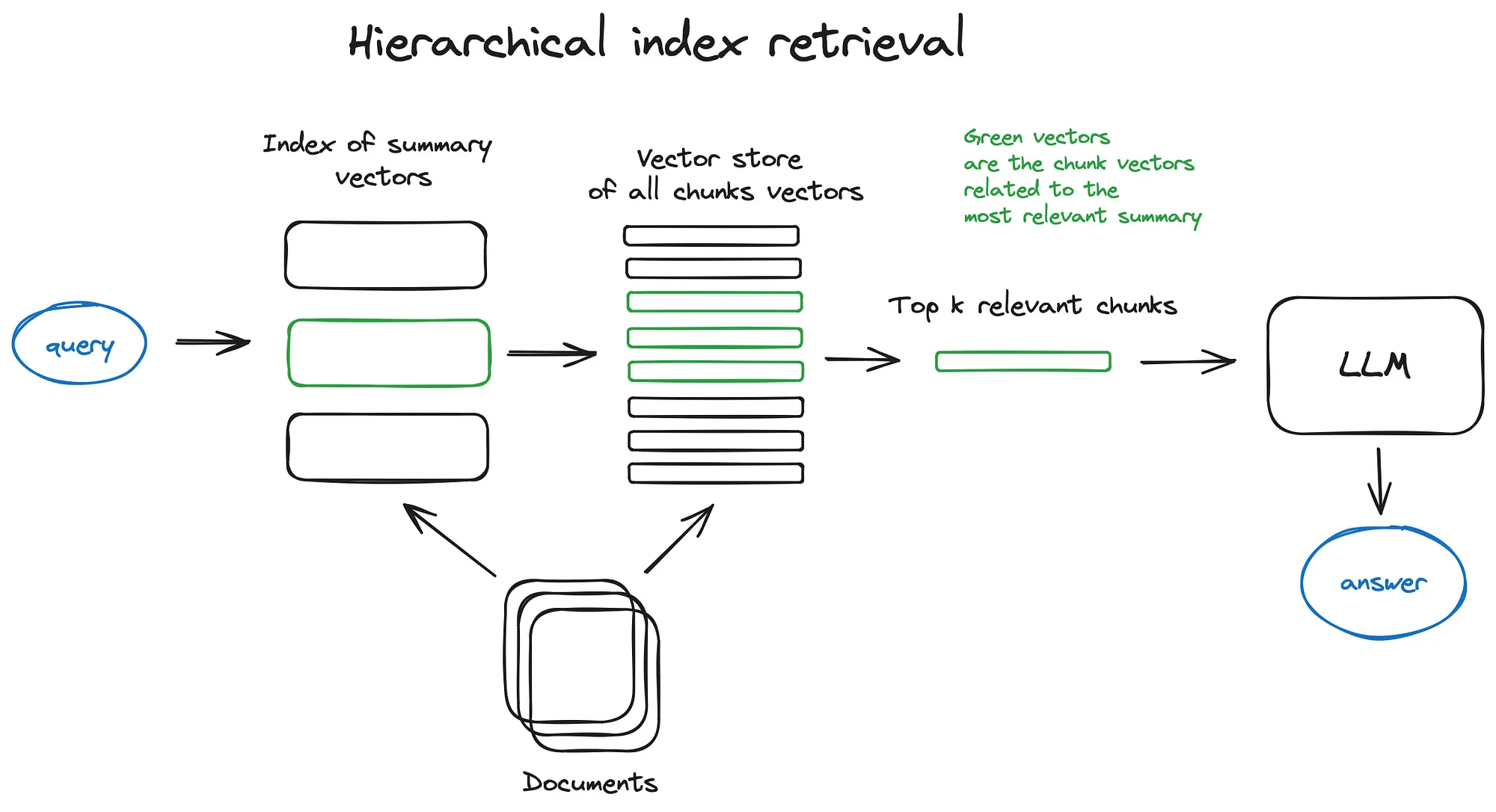
1.2 分层索引
- 分层索引是对向量存储索引的一种优化,通过对文本经过不同等级的抽象,得到不同层次的向量,从而提高检索效率,如下图所示:
1.3 假设性问题和假设性回答
- 假设性问题是让
LLM提前给每一段知识库中的文本生成一个假设性问题,当用户提问时,可以直接通过假设性问题进行检索,从而提高检索效率。 - 假设性回答也被称为
Hypothetical Document Embeddings(假设性文本嵌入),是用LLM给用户的query生成一个假设性回答,用假设性回答去检索,从而提高检索效率。
1.4 内容增强索引
- 内容增强索引原理非常简单,即在检索时,将检索到的文本内容相关的其他文本(例如这段文本前后内容等)内容也一并返回,从而提高检索召回率。
1.5 融合索引
- 将向量索引和关键词索引融合,提高召回
2. 重排和过滤
- 重排和过滤是在检索结果返回后,对检索结果进行进一步处理,提高生成效果的一种方法。
- 过滤/重排的常用方法包括:
- 通过元数据过滤/重排:例如只保留某个时间段的数据
- 通过相似性分数过滤/重排
- 使用其他
LLM进行过滤/重排
3. 查询转换
- 查询转换是指在用户提问时,将用户的提问转换为更适合检索的形式,提高检索效率。
- 例如,用户提问为:“在
Github上,Langchain和LlamaIndex这两个框架哪个更受欢迎?”,则可以转换为:- “Langchain 在 Github 上有多少星?”
- “Llamaindex 在 Github 上有多少星?”
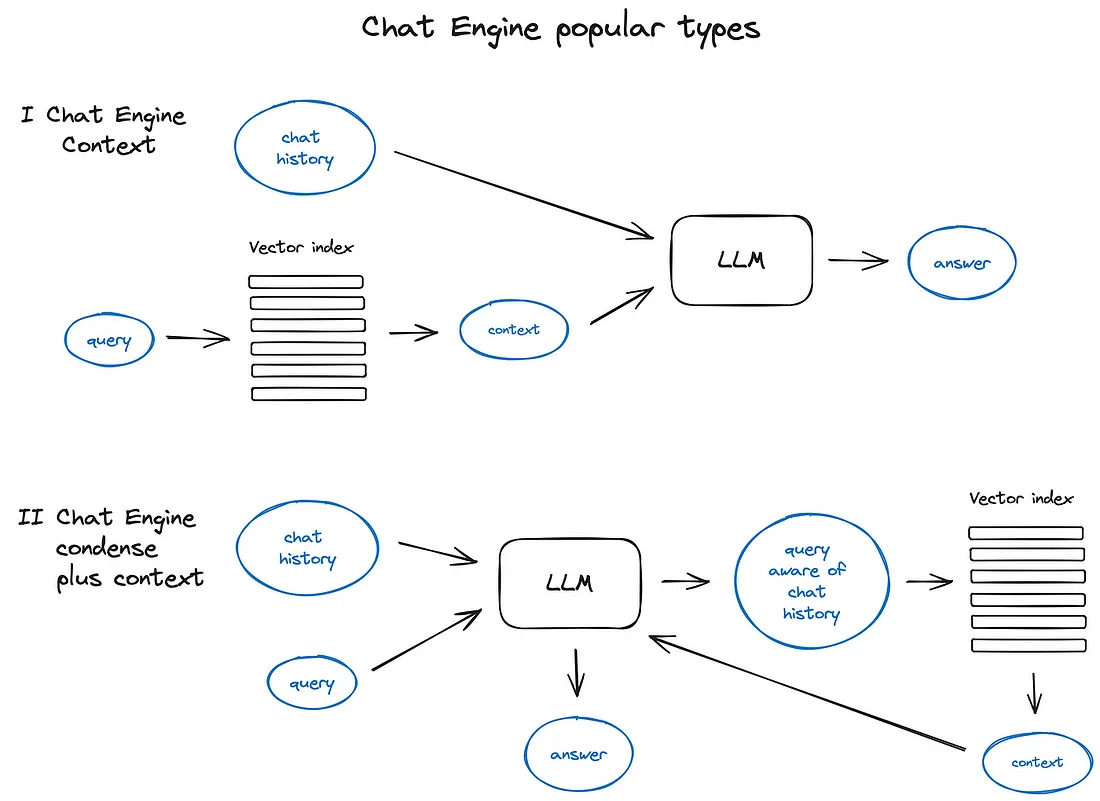
4. 结合 RAG 的聊天引擎
- 总体上,结合 RAG 的聊天引擎可以分成两种范式,如下图所示:
5. 智能体(Agent)
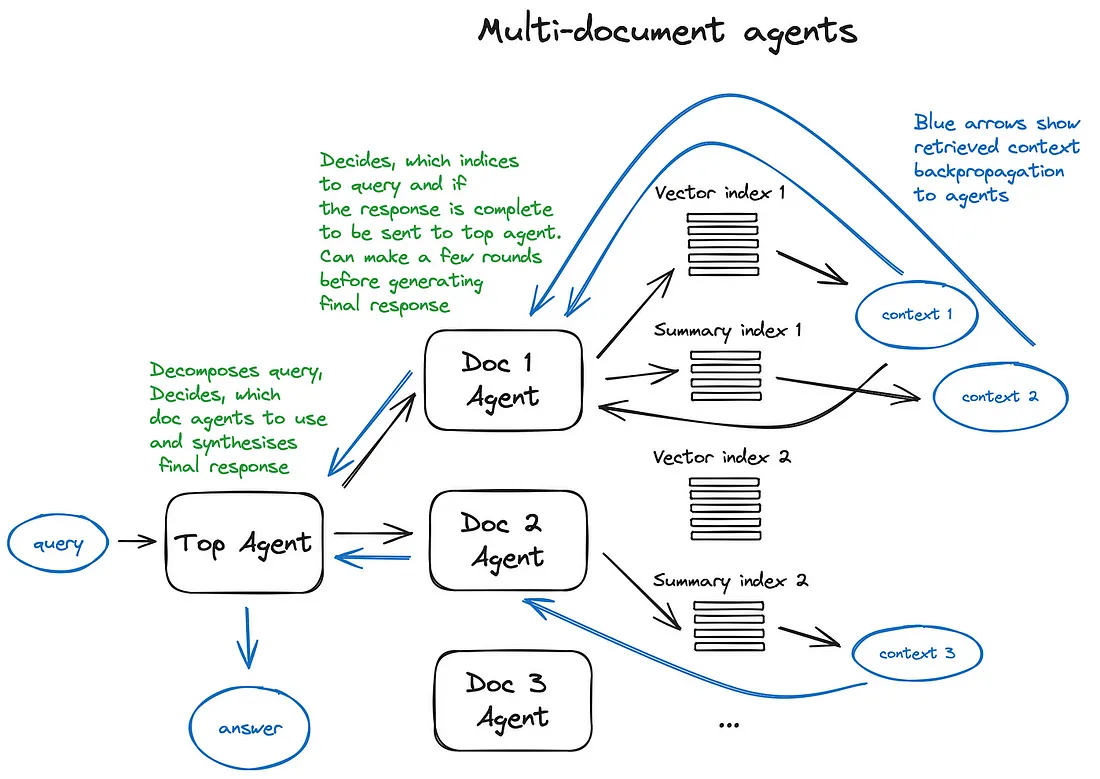
- 例如多文档智能体,就是给每个文档初始化一个智能体,该智能体能进行文档摘要制作和传统问答机制的操作,还有一个顶层智能体,负责将查询分配到各个文档智能体,并综合形成最终的答案。总体流程如下图所示:
6. 响应合成
- 这是任何 RAG 管道的最后一步——根据检索的所有上下文和初始用户查询生成答案。响应合成的主要方法有:
- 通过将检索到的上下文逐块发送到 LLM 来优化答案
- 概括检索到的上下文,以适应提示
- 根据不同的上下文块生成多个答案,然后将它们连接或概括起来
Thoughts
- 看起来
RAG是一种自由度很高的范式,可以根据具体的任务需求,设计出不同的检索和生成策略,但是也正是因为这种自由度,RAG的实现难度也相对较高,需要综合考虑检索和生成的各种因素,才能设计出一个高效的RAG系统。