0%
URL
TL;DR
BLIP 是 Salesforce 提出的一种图文多模态对齐算法,全称是 Bootstrapping Language-Image Pre-training,是一种自举的图文多模态预训练算法- 相较于
CLIP 只能对齐图像和文本表征,BLIP 将任务范式进行了扩展,基本已经有了多模态大模型的雏形
Algorithm
BLIP 整体架构
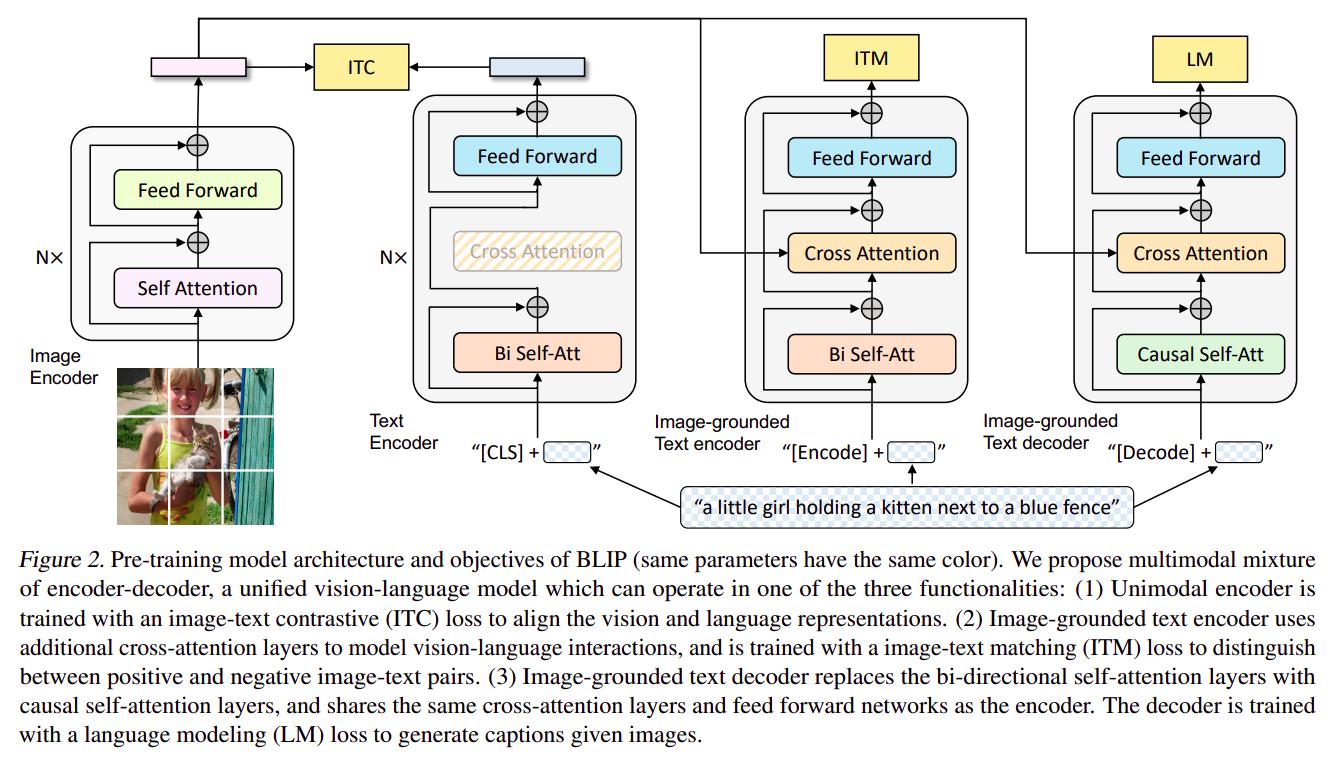
BLIP 在预训练阶段,包含三种损失函数
Image-Text Contrastive Loss:对齐图像和文本表征,和 CLIP 的对齐方式类似,不同的是 BLIP 引入了 Momentum Model,可以使得训练更加稳定Image-Text Macthing Loss:图像和文本匹配损失,输出 True 或 False,本质是交叉熵损失Language Modeling Loss:语言建模损失,预测下一个词(大模型范式),用于文本内容生成
- 从上图可以看出,模型实际包含四个部分:
Image Encoder:图像编码器,将图像编码为 Image EmbeddingText Encoder:文本编码器,将文本编码为 Text EmbeddingImage-grounded Text Eecoder:图像驱动文本编码器,用文本特征 Cross-Modal Attention 去索引图像特征,输出文本图像特征是否匹配(True / False)Image-grounded Text Decoder:图像驱动文本解码器,用文本特征 Cross-Modal Attention 去索引图像特征,用逐个 Token 预测的方式生成文本,回答文本对应的问题
- 从实现代码看,
Text Encoder / Image-grounded Text Eecoder / Image-grounded Text Decoder 实际上共用了一个 Bert 预训练模型的一组参数(仅仅在部分位置不共享参数)
Text Encoder:
- 原生
Bert 模型,用于文本编码
- 不做
Cross-Modal Attention,只做 Self-Attention
- 最后输出层为表征层
- 用特殊的
[CLS] 作为任务标识符
Image-grounded Text Eecoder:
- 魔改
Bert 模型,加入 Cross-Modal Attention
- 这种状态处于
encoder 和 decoder 之间,比 encoder 多了 Cross-Modal Attention,比 decoder 少了 Causal Self-Attention
- 用文本特征去索引图像特征
- 最后输出层为二分类层
- 用特殊的
[Encoder] 作为任务标识符
Image-grounded Text Decoder:
- 魔改
Bert 模型,将其转化成一个完全的 decoder 形态,主要包括两点:
- 加入
Cross-Modal Attention,用文本特征去索引图像特征
- 由于是生成任务,所以需要用
Causal Self-Attention 取代 Bert 默认的 Bidirection Self-Attention
- 最后输出层为
vocab prob 层,用于生成文本(下一个文本在词表中的概率)
- 用特殊的
[Decoder] 作为任务标识符
- 三个模型仅仅在
Head 层和 Attention 层参数上有所不同,其余参数共享
Bootstrapping 策略
BLIP 中的 B 就是 Bootstrapping 的意思,即自举,表示此算法有一种自我增强的方式- 自我增强的方式主要是通过
CapFilt 方法实现的:
Captioner:用于为图像生成高质量的文本描述Filter:用于过滤掉低质量的图像-文本对,保留高质量的对用于训练
CapFilt 工作流程:
- 生成伪标签:使用
Captioner 为无标签或弱标签图像生成文本描述,形成伪标签
- 过滤伪标签:使用
Filter 评估生成的伪标签的质量,保留高质量的伪标签
- 更新训练数据集:将过滤后的高质量伪标签与原始训练数据集合并,形成新的训练数据集
- 重新训练模型:使用更新后的训练数据集重新训练模型,从而改进模型的性能
Thoughts
- 在某种程度上,
BLIP 统一了几乎所有的图文多模态任务,除了无法做图像生成任务外,其他任务都可以通过 BLIP 的不同模块组合实现
BLIP 的 Bootstrapping 策略是一种自我增强的方式,可以使得模型在无监督的情况下不断提升性能,如今这几乎是多模态预训练算法的标配- 从实验的角度告诉我们,
encoder 和 decoder 做充分的参数共享是可行的,仅仅在少量的位置上不共享参数,就可以实现完全不同任务的模型