URL
TL;DR
- 本文提出了一种新的混合专家语言模型
DeepSeek-V3,共计 671B 总参数,对于每个 token 仅仅激活 37B 个参数,可以说又强又快。
- 主要的改进点包括:
Multi-head Latent Attention (MLA):MLA 是 DeepSeek 系列的核心模块(Deepseek v2 就有了),通过 MLP 将 hidden state 映射到 latent space,降低计算和存储复杂度。可参考 Deepseek v2 MLA 详解。Deepseek MOE:一种比 Gshard 更优的 MoE 架构,可参考 Deepseek MoE 详解。Multi-token predicition (MTP):一种新的 token 预测方式,与传统的 predict next token 自回归预训练方式不同,MTP 通过一次预测多个 token(例如一次预测 next token 和 next2 token 和 next3 token),仅在训练阶段使用 MTP,推理阶段只使用 next token 的预测结果,即可大幅提高模型在 benchmark 上的综合表现。auxiliary-loss-free strategy for load balancing:一种新的 MoE 间负载均衡策略,无需额外的辅助损失,简化了训练过程,提高了训练效率。
- 性能与稳定性:
- 性能:
DeepSeek-V3 的表现超过了其他开源模型,其性能已经可以与一些领先的闭源模型相媲美。
- 稳定性:尽管性能卓越,模型全程训练仅花费了
278.8 万 H800 GPU 小时,而且在整个训练过程中表现出极高的稳定性,没有出现不可恢复的损失暴增或需要回滚的情况。
Algorithm
总体流程
Pre-TrainingContext ExtensionPost-Training

Multi-token predicition (MTP)
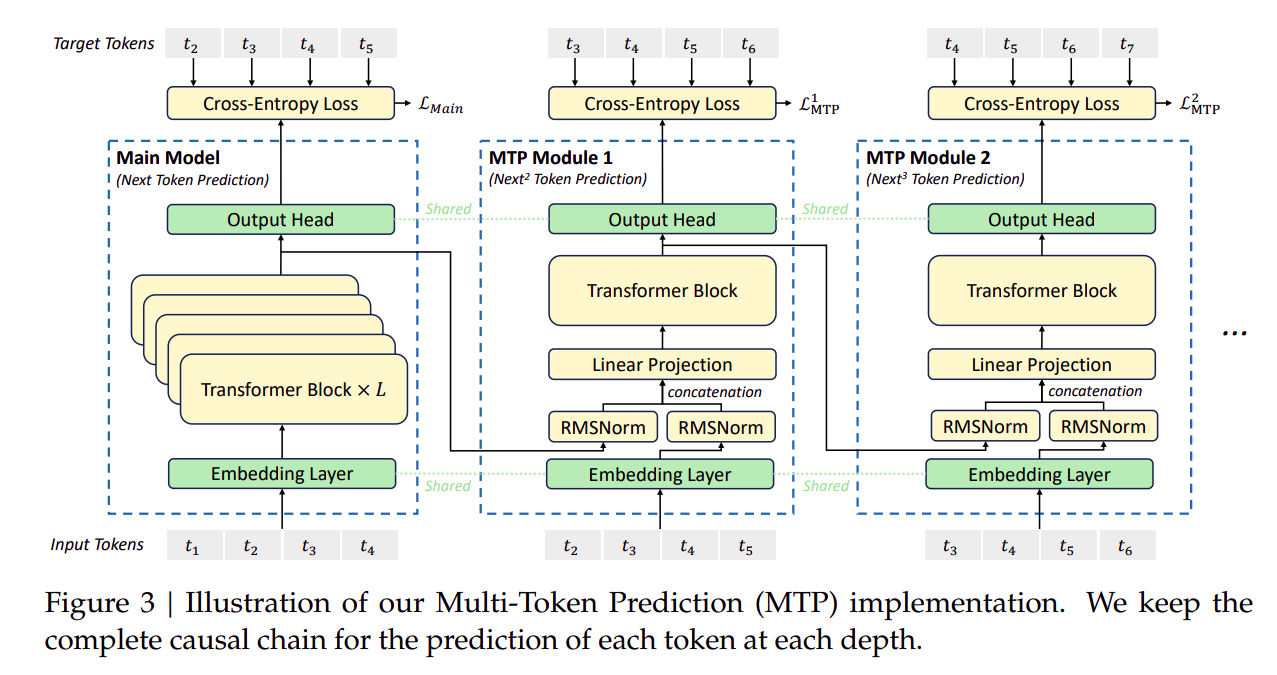
- 上图给出了一次预测
next token 和 next2 token 和 next3 token 的 MTP 模型结构。
- 具体来说,
MTP 是在标准 Decoder only Transformer 的基础上,额外引入了 k-1 个 token 预测头,每个 token 预测头都是一个 Norm + Concat + Projection + Transformer block 结构。
- 假设图上从左到右的
token head 分别记作 head0、head1、head2,则 head0 预测的是 next token,head1 预测的是 next2 token,head2 预测的是 next3 token。
MTP 过程必须要保持因果性:
- head0 输入 token0,主干网络输出 h0,
output layer 将 h0 映射为 next token 预测,记作 token1′。
- head1 输入 h0 和 token1,提取特征记作 h1,
output layer 将 h1 映射为 next2 token 预测,记作 token2′。
- head2 输入 h1 和 token2,提取特征记作 h2,
output layer 将 h2 映射为 next3 token 预测,记作 token3′。
embedding layer 和 output layer 在 MTP 中是共享的。MTP 通常只用在训练阶段,即在推理阶段只使用 head0 的输出。- 也可以将
inference MTP 和 speculative decoding 结合,提高模型生成效率。
Auxiliary-loss-free strategy for load balancing
训练阶段负载均衡策略
gi,t′={si,t,0,si,t+bi∈Topk({si,t+bj∣1≤j≤Nr},Kr)otherwise
- 其中:
- si,t=Sigmoid(utTei)
- bi 是
bias 参数
- Nr 是
Expert 的数量
- Kr 是每个
token 保留的 Expert 数量
- bj 是根据每一个
Expert 被激活的次数动态调整的
- 如果一个
Expert 被激活的次数过多(大于专家激活平均值),则 bj=bj−γ
- 如果一个
Expert 被激活的次数过少(小于专家激活平均值),则 bj=bj+γ
- 其中 γ 是一个超参数,表示
bias update speed
- 关于
bias 的详细更新策略,可参考下图

推理阶段
- 推理阶段无需额外的负载均衡策略,直接使用 si,t 即可。
Complementary Sequence-Wise Auxiliary Loss
- 上面提到的
Auxiliary-loss-free strategy for load balancing 损失只能保证 Expert 的负载均衡,但可能出现一个 Sequence 中每一个 token 都激活了相同的 Expert,这种情况下,Expert 之间的负载仍然不均衡。因此 Complementary Sequence-Wise Auxiliary Loss 通过引入 Auxiliary Loss 来保证 Sequence 内部 token 之间的负载均衡。
- 具体来说,需要关注:
- 离散选择频率:每一个
Expert 在 Sequence 中的激活次数
- 连续激活强度:每一个
Expert 在 Sequence 中平均专家分数
- 公式表述:
LBal=αi=1∑NrfiPi
fi=KrTNrt=1∑TI(si,t∈Topk({sj,t∣1≤j≤Nr},Kr))
si,t′=∑j=1Nrsj,tsi,t
Pi=T1t=1∑Tsi,t′
- 其中:
- LBal 是
Complementary Sequence-Wise Auxiliary Loss
- α 是一个超参数,是一个很小的权重
- fi 是
Expert i 的离散选择频率
- Pi 是
Expert i 的连续激活强度
- T 是
Sequence 的长度
- Nr 是
Expert 的数量
- Kr 是每个
token 激活的 Expert 数量
- I(⋅) 是指示函数
- si,t 是 Sigmoid(utTei),表示专家的分数
- 道理也很简单,就是希望在一个
Sequence 中,每一个 Expert 被激活的次数和激活的强度都是均衡的。
训练框架设计
- 模型训练基于自主研发的
HAI-LLM 框架,这是一个经过优化的高效轻量级训练系统,目前没有开源。
DeepSeek-V3 的并行策略包含三个层面:
16 路流水线并行(Pipeline Parallelism, PP)- 跨
8 个节点的 64 路专家并行(Expert Parallelism, EP)
ZeRO-1 数据并行(Data Parallelism, DP)
- 开发了
DualPipe 流水线并行算法,相比于现有的 PP 算法,减少了空泡,基本上实现了计算和通信的高度重叠。

- 优化了跨节点全对全通信内核,充分利用节点内
GPU 间的 NVLink 带宽和节点间 InfiniBand 带宽,同时减少了通信所需的流式多处理器(SMs)资源占用
- 通过精细的内存管理优化,使得模型训练无需依赖开销较大的张量并行(
Tensor Parallelism, TP)技术
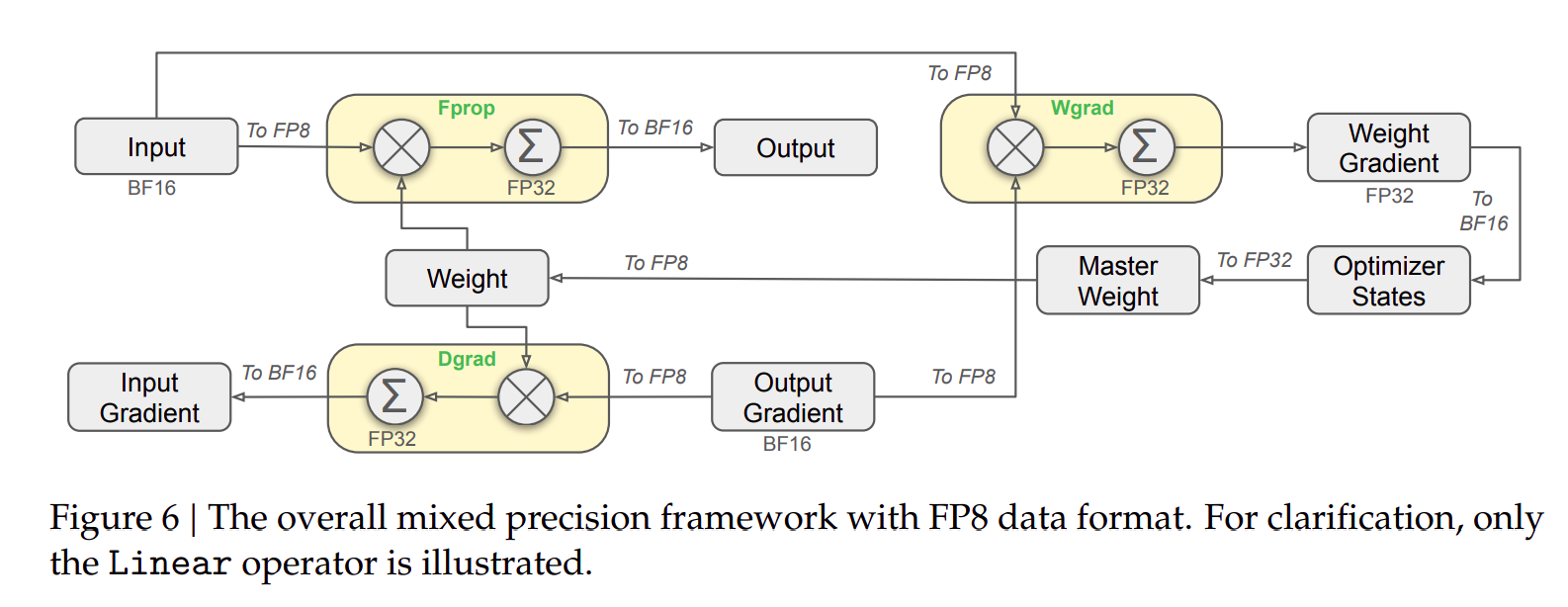
FP8
DeepSeek-V3 开发了 FP8 (E4M3) 混合精度训练框架,首次在超大规模模型上验证了 FP8 训练的可行性和效果。- 通过算法、框架和硬件的综合优化,突破了跨节点 MoE 训练中的通信瓶颈,实现了计算与通信的高度重叠。这种优化大幅提升了训练效率,降低了训练成本,同时支持了更大规模模型的训练而无需额外开销。
Thoughts
- 实际上
DeepSeek V3 技术报告中还有很多细节,尤其是很多关于工程优化的部分,此处不再一一列举
- 工程能力,尤其是开发一套分布式训练框架且根据模型特性对其深度优化的能力,是一个大模型成功的不可或缺因素
- 如果想要在大模型领域有所建树,不仅需要有强大的算法研究能力,还需要有强大的工程能力,比如
CUDA 编程能力等
References