URL
TL;DR
- 这是由恺明和杨立昆提出的一篇关于
transformer算子优化的论文,主要观点是去掉transformer结构中的normalization层,改成tanh层 - 改用
tanh算子的transformer模型,在大多数任务上可达到使用归一化层的模型相同的性能,甚至更好
Algorithm
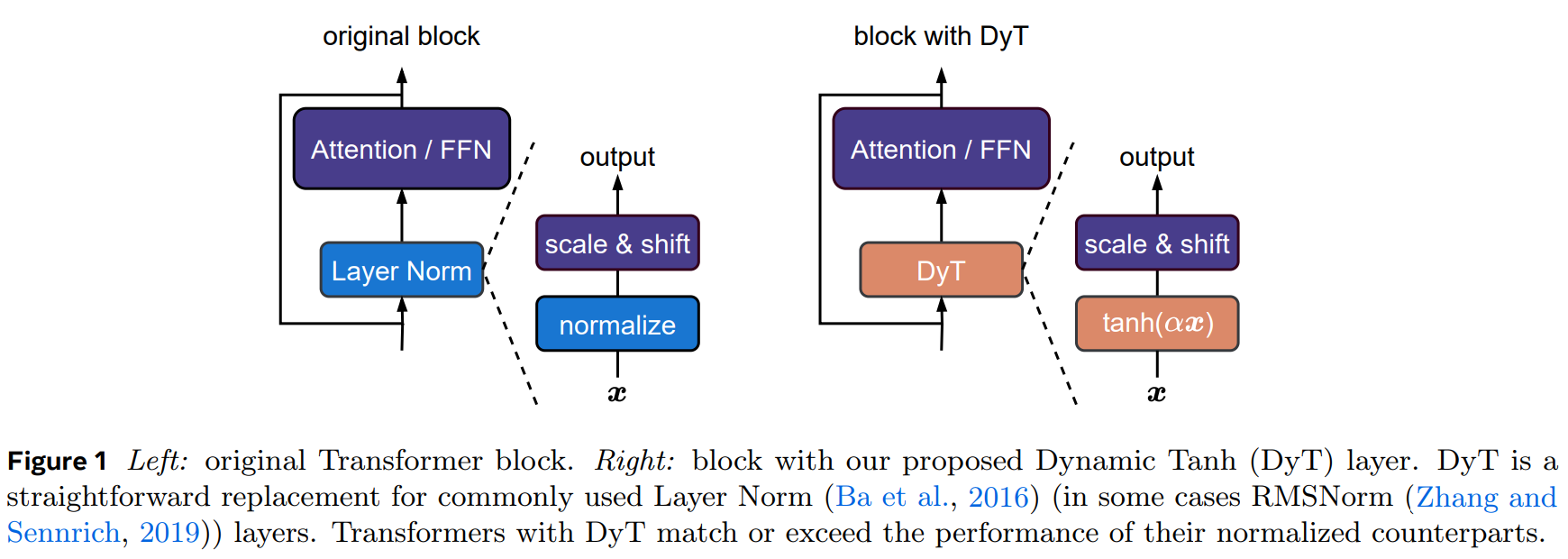
- 简单来说,这篇论文的核心思想是将
transformer中的normalization层(可以是LayerNorm或RMSNorm)替换成dynamic tanh层(简称DyT) normalization计算公式:
其中 和 分别是
mean和std, 和 是scale和shift参数
DyT计算公式:
其中 是个可学习参数, 和 是
scale和shift参数(和normalization一样)
DyT实现伪代码:
1 | # input x has the shape of [B, T, C] |
默认初始化值为
0.5
Results
- 作者在多个领域的知名模型上都对比了修改前后训练精度,
DyT的性能和normalization的性能基本一致,打的有来有回
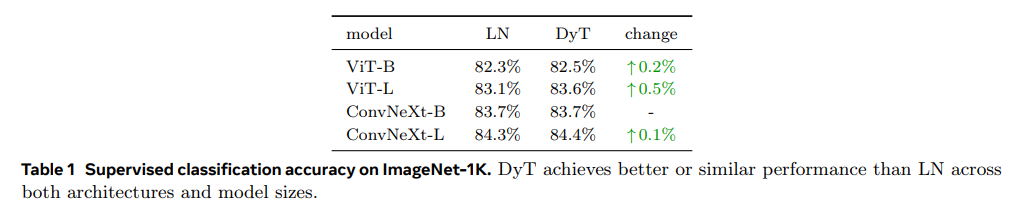


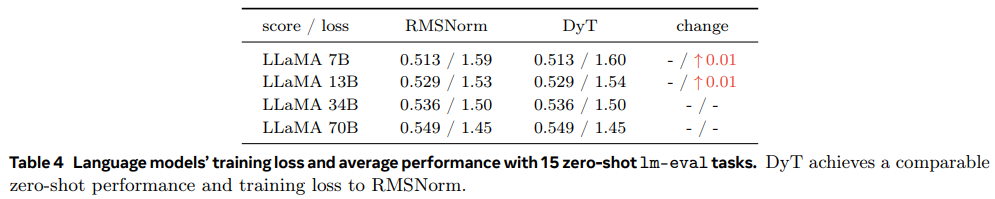


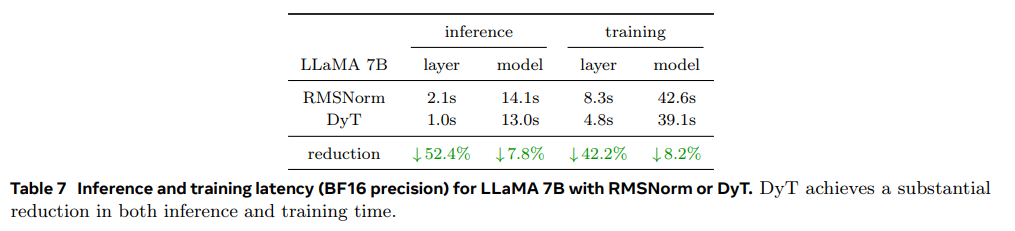
- 作者还对比了
DyT和normalization的训练/推理速度,DyT的训练/推理速度要快很多
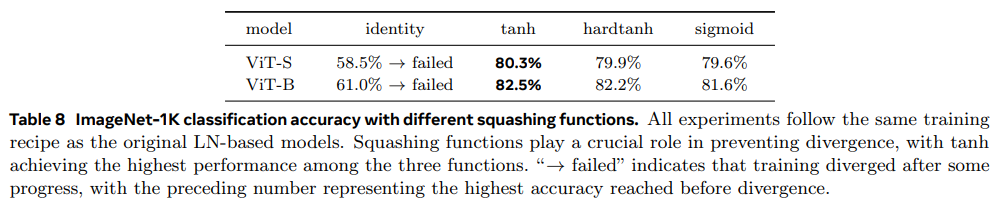
- 作者同时做
tanh和 做了消融实验,发现tanh和 都是必要的

Thoughts
- 属于是恺明和立昆的梦幻联动了…,这种对最火的结构的优化,非大佬不能为也,想象下如果这篇论文是大学实验室发表的,大家第一反应恐怕是:Who think you are? 😂
- 之前算是稍微接触过硬件,
DyT这种element-wise op比normalization这种reduce op一定快多了,想怎么tiling都行…