0%
URL
TL;DR
Qwen3 系列模型四月二十九日正式发布,但到目前为止,还没发布技术报告,只有一篇官方博客,介绍了 Qwen3 的一些基本信息- 本文围绕着官方博客介绍,结合实际使用情况,给出一些个人的理解
Qwen3 系列模型
- 本次
Qwen3 主要发布了八个版本的模型,其中包含两个 MOE 模型和六个 dense 模型:
Qwen3-235B-A22B:MOE 模型,235B 参数量,22B 激活参数量Qwen3-30B-A3B:MOE 模型,30B 参数量,3B 激活参数量Qwen3-32B:dense 模型,32B 参数量Qwen3-14B:dense 模型,14B 参数量Qwen3-8B:dense 模型,8B 参数量Qwen3-4B:dense 模型,4B 参数量Qwen3-1.7B:dense 模型,1.7B 参数量Qwen3-0.6B:dense 模型,0.6B 参数量
- 还有对应的
Base 模型(只经过预训练)和 fp8 Quantized 模型(量化模型)
Qwen3 相较于上一代 Qwen2.5,一个较大的技术进步是:统一了 Reasoning 和非 Reasoning 模式,即不再区分推理模型和非推理模型(或者叫思考模型和非思考模型),而是一个模型可以通过 prompt 来选择推理模式和非推理模式
Qwen3 模型的主要特性
预训练
- 相较于上一代
Qwen2.5 使用了 18 万亿个 token 做预训练,Qwen3 使用了 36 万亿个 token 做预训练(整整翻了一倍,这是多大的数据团队才能搞出来的,太壕了)
- 包含了
119 种语言和方言,有大量数据是合成数据和在 PDF 上识别的文本数据
- 预训练分成了三个阶段:
- 第一阶段:模型在超过
30 万亿个 token 上进行了预训练,上下文长度为 4K token
- 第二阶段:通过增加知识密集型数据(如
STEM、编程和推理任务)的比例来改进数据集,在 5 万亿个 token 上进行了预训练
- 第三阶段:使用高质量的长上下文数据将上下文长度扩展到
32K token
- 预训练实际效果:官方的说法是
Qwen3-1.7B/4B/8B/14B/32B-Base 分别与 Qwen2.5-3B/7B/14B/32B/72B-Base 表现相当
后训练
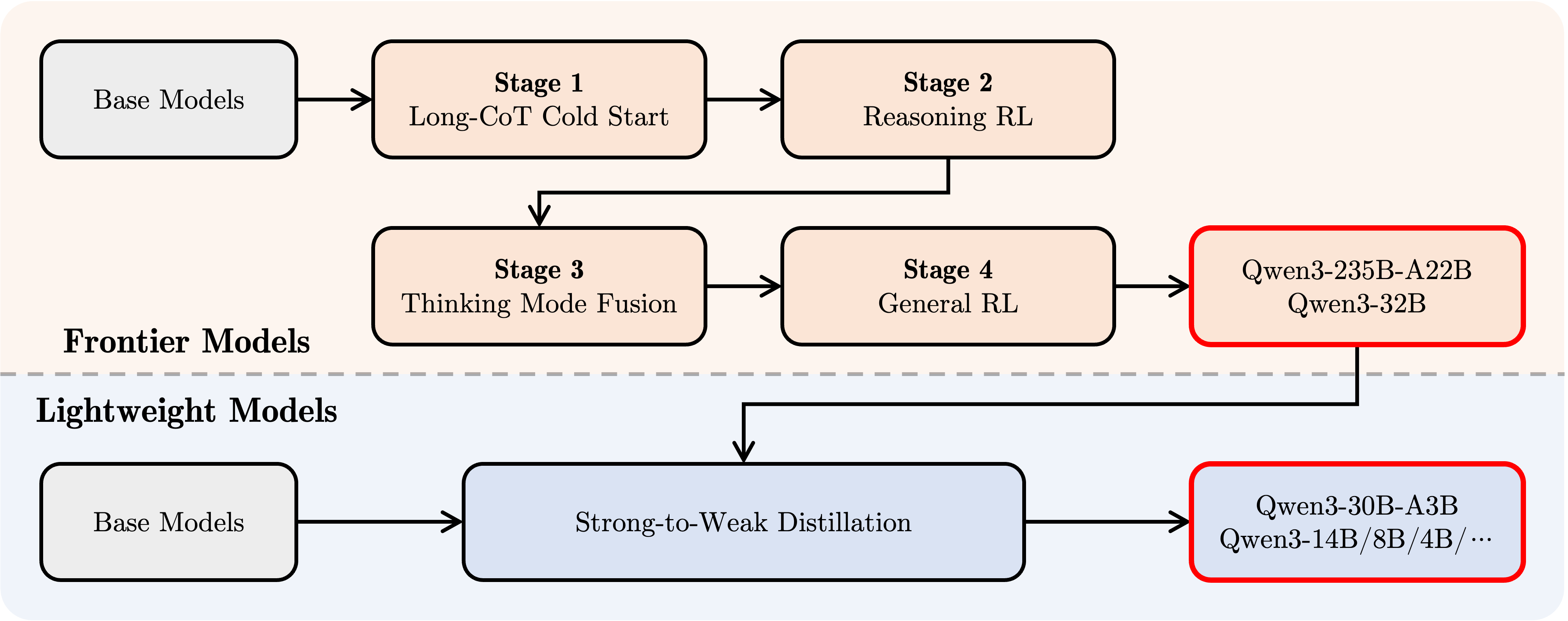
- 简单概括:用
SFT → RL → SFT+RL 混合 → RL 四个阶段后训练 Qwen3-235B-A22B 和 Qwen3-32B 模型,然后蒸馏得到其他小尺寸模型(大 MOE 蒸小 MOE,大 dense 蒸小 dense)
- 四个阶段分别是:
- 长思维链冷启动 :使用监督微调(
SFT)训练模型生成初步的长思维链推理能力,作为初始阶段的基础。
- 长思维链强化学习 :通过强化学习(
RL)进一步提升模型在复杂推理任务中的表现,优化生成思维链的质量和连贯性。
- 思维模式融合 :结合
SFT 和 RL 的混合策略,将不同思维模式(如逻辑推理、知识检索等)整合到统一框架中,增强模型的灵活性。
- 通用强化学习 :以
RL 为主导,对模型进行全局优化,强化其在多样化任务中的通用性和鲁棒性。
Qwen3 使用
- 使用上和
Qwen2.5 没有太大区别,主要是增加了 Reasoning 模式的选择开关
- 这个开关也非常简便,大概有两种方式可以选择:
- 在最新版
Transformer 库中 tokenizer.apply_chat_template 中可以设置 enable_thinking=True # Switch between thinking and non-thinking modes. Default is True.
- 另外一种方式就是始终保持上面的开关常开,然后在
prompt 中添加 /no_think 来关闭推理模式。/no_think 可加到 system content 或 user content 结尾。
- 在一些下游任务上做了
SFT 微调测试,发现 Qwen3-1.7B 经过 SFT 之后和 Qwen2.5-3B-Instruct 经过 SFT 之后的效果差不多,这一点和官方对预训练的说法一致
Thoughts
- 在当今这个大模型结构同质化时代,预训练数据越多,模型的能力越强(同样效果下数据翻一倍模型尺寸可缩减一半!!),所以小厂没有这么多数据工程师,搞不到大量的高质量的数据,是很难在大模型上追赶大厂
- 到今天为止,
Llama 系列官方模型都不能做到原生支持中文,和 Qwen 系列模型原生支持 119 种语言和方言相比,感觉非常小家子气,注定会被扫进历史的垃圾堆里
DeepSeek 对 Qwen 的影响很大,比如:
- 从
DeepSeek v3 之后,Qwen 系列模型预训练和最终版的命名从:Qwen2.5-7B/Qwen2.5-7B-Instruct 变成了 Qwen3-8B-Base/Qwen3-8B
- 广泛的使用了模型蒸馏,确实极大的提高了小尺寸模型的能力(之前
Qwen2.5-0.5B-Instruct 基本就是个答非所问的傻子,现如今的 Qwen3-0.6B 在不开推理模式的情况下也可以解决很多数学问题,非常强)
- 四段式后训练也和
DeepSeek 使用的后训练非常相似
- 合并推理和非推理模型的做法,是今后大模型的趋势,有不少模型都在朝着这个方向发展
- 官方表示
Qwen 系列后续会向着 Agent 方向发展,铺垫了很久的 MCP 可能会产生新的 Agent 应用变革