URL
TL;DR
- 本文提出一种新的缓存利用机制
CacheBlend,旨在解决RAG系统中知识KV Cache的可用性,通过一种稀疏近似的方式平衡速度和准确性。
Algorithm
知识注入的两种常见方式
1. 微调
- 收集知识库中的文档数据,微调模型,使其能够在生成文本时利用这些知识。
- 优点:推理时不会有额外的延迟。
- 缺点:
- 动态更新困难
- 模块化困难(无法要求模型使用哪些知识,不用哪些知识)
2. 知识检索
- 在推理时,检索相关文档并将其作为上下文输入到模型中。
- 优点:动态更新知识库,模块化。
- 缺点:推理时需要额外的延迟,一是因为检索本身的延迟,二是因为模型需要计算额外的上下文注意力。
如何同时解决模块化和速度的问题?
- 如果在知识检索技术的基础上,检索系统提前缓存了 知识库中文档对应的
KV Cache,那么就可以在推理时直接使用这些KV Cache无需计算这部分的注意力(只需要检索延迟)。
这样做有什么问题?
- 一个很重要的问题是:优于现如今绝大多数
LLM的decoder only架构,缓存的知识库的KV Cache必须作为prefix注入到模型中,且只能用一个,否则模型无法利用这些知识。 - 例如:
- 记检索到的文档的
KV Cache为A,历史对话信息和用户输入为B - 那么模型的输入应该是
A + B,而不是B + A - 因为
KV Cache位置i的值依赖于0 ~ i-1位置的值,如果不作为prefix注入,那么模型无法利用这些知识。
- 记检索到的文档的
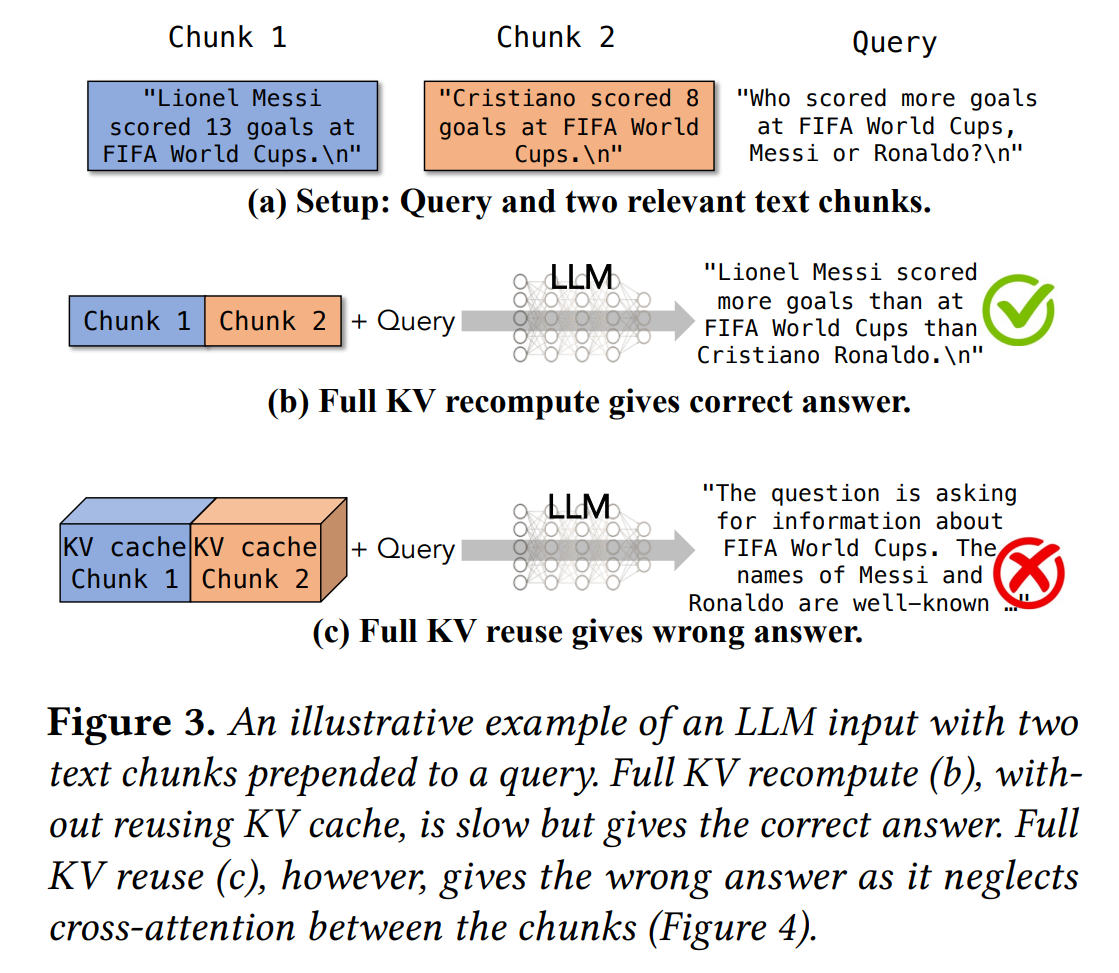
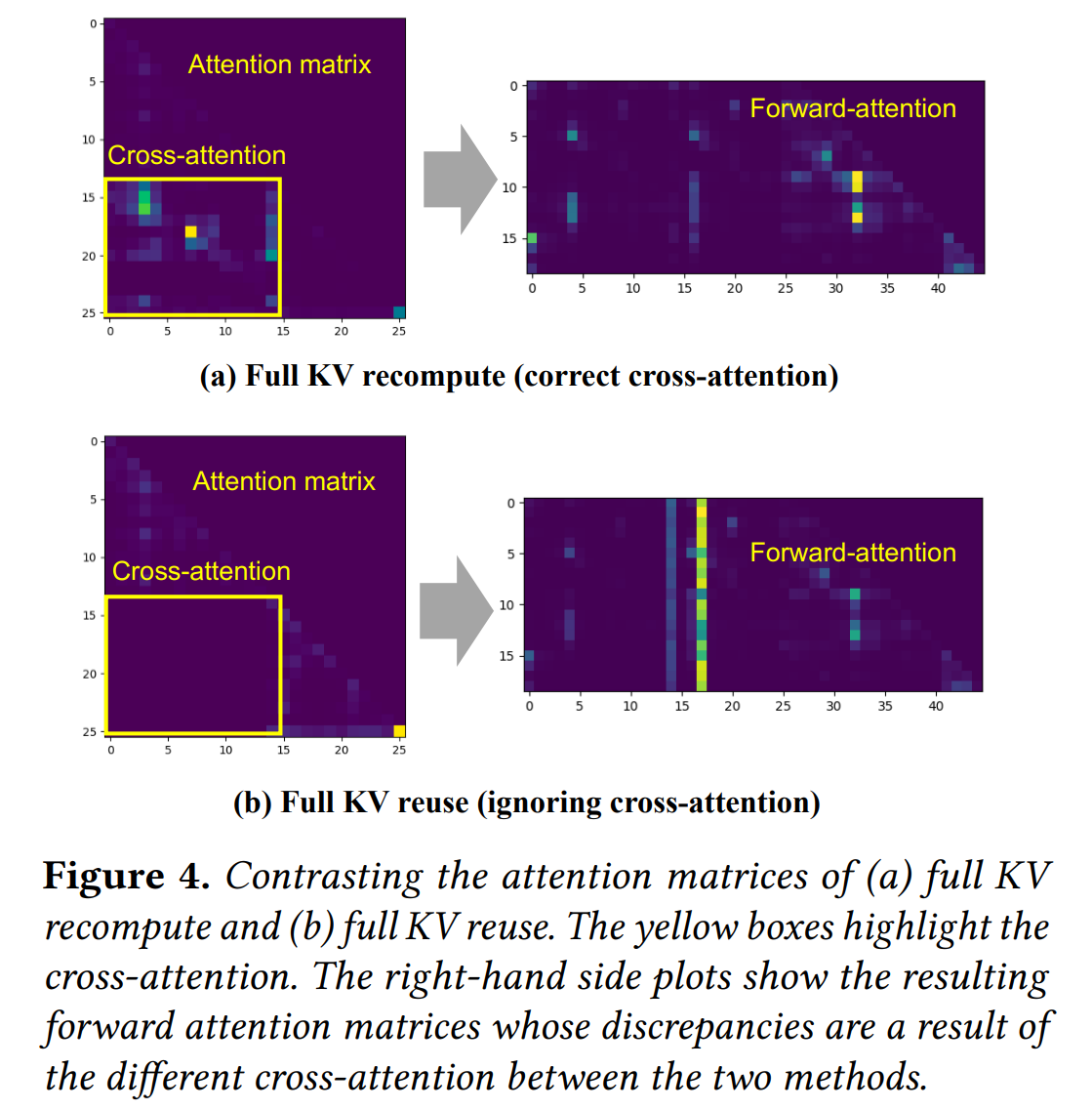
CacheBlend 想要解决的问题
CacheBlend目的就是为了 解决RAG系统中知识KV Cache只能作为prefix注入的问题CacheBlend做不到和完全重新计算数学上等价,只能是近似- 原理本质上讲是平衡,即 在完全重新计算
KV Cache和完全使用缓存的KV Cache之间进行平衡,如下图:
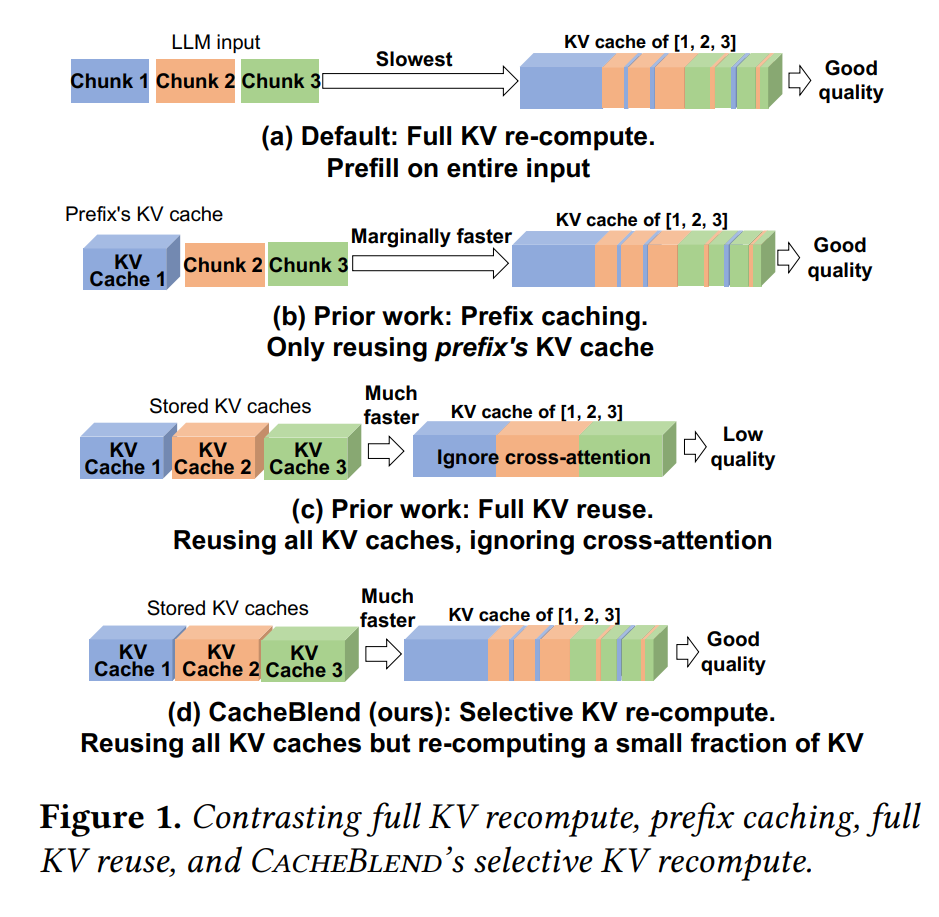
CacheBlend 的解决方案
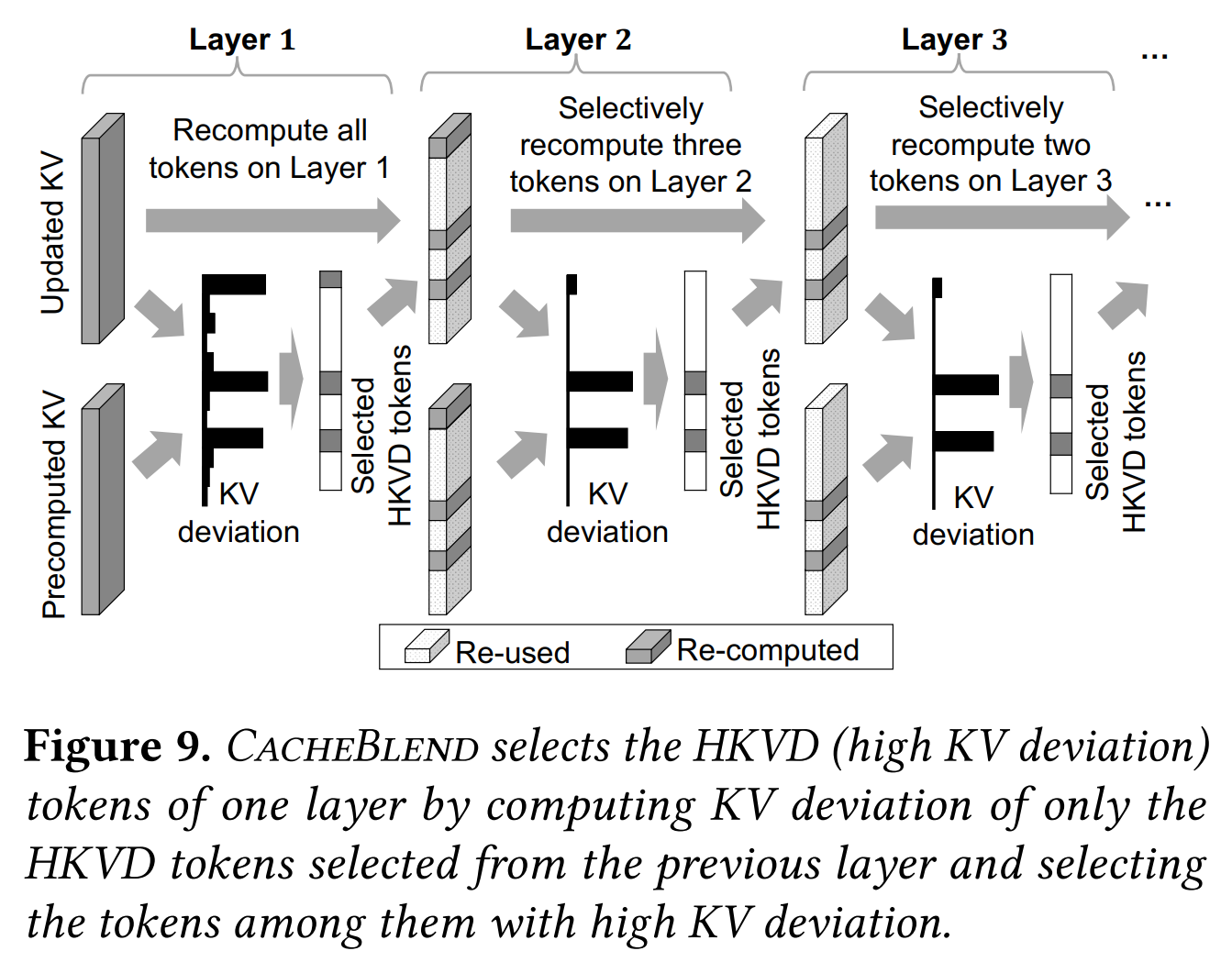
CacheBlend通过 稀疏近似 的方式,平衡速度和准确性,具体来说,对非prefix的KV Cache,做:- 第
1层:计算所有Token的KV偏差,选择Top 20%作为候选HKVD (High-KV-Deviation) Token - 后续层:仅对前一层的
HKVD Token计算偏差,从中选择 作为当前层HKVD Token - 终止:最终每层仅更新约
10-15% Token,偏差显著降低
- 第
- 总体上就是用逐层用新的
KV Cache替换旧的KV Cache,替换依据是KV偏差,偏差越大的Token替换的优先级越高。
CacheBlend 的优势
- 质量保障:仅更新
10-15% Token即可达到Full KV Recompute的质量(F1/Rouge-L偏差<0.02) - 延迟隐藏:
KV重新计算与KV缓存加载流水线并行,使额外延迟近乎为零 - 提速:
TTFT (Time To First Token)降低2.2 ~ 3.3倍,吞吐量提升2.8 ~ 5倍
Thoughts
- 稀疏无处不在