URL
TL;DR
- 标题是 “用于端到端分层序列建模的动态分块” ,实际上包含了不少信息量:
- “端到端”:意味着
token free,真正的端到端语言模型,输入输出都是字节流,不需要tokenization过程 - “分层”:意味着
H-Net模型结构是 递归 的,H-Net模型由encoder+main network+decoder组成,其中main network还可以是H-Net模型 - “动态分块”:意味着
H-Net模型可以动态地调整chunk的大小,可以理解为维护了一个隐式的动态tokenizer,模型会在学习过程中找到最优的隐式分词方法
- “端到端”:意味着
- 本质是一个基于
SSM + Transformer结构的大模型,抛弃了tokenization过程,直接在字节流上进行训练和推理
Algorithm
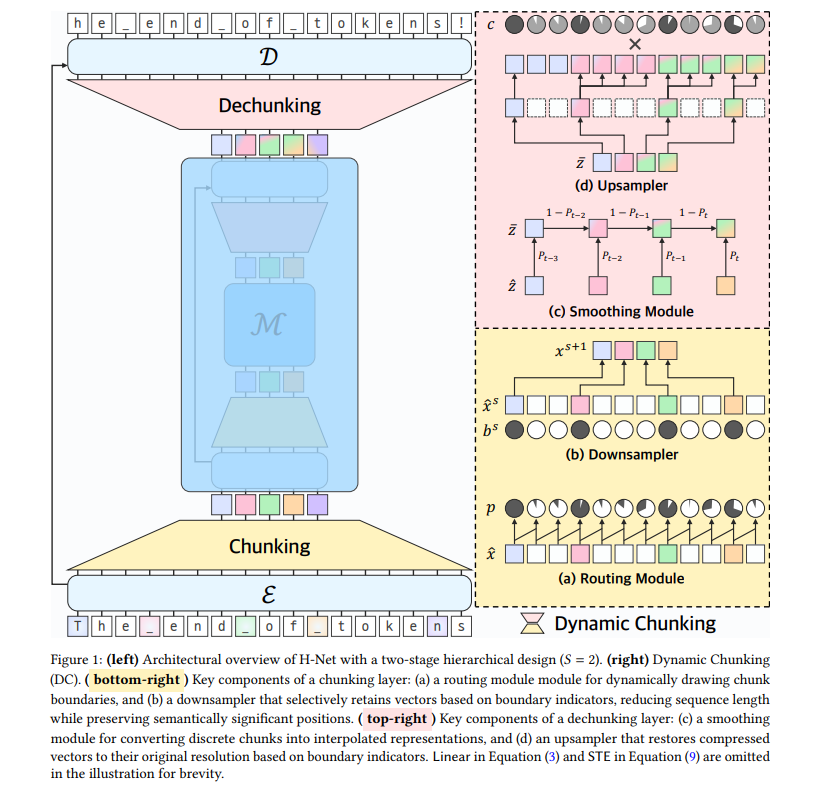
H-Net 总体结构
现有的分词机制的缺陷
- 当前主流语言模型(如
ChatGPT)依赖预定义的分词器(如BPE),存在以下问题:- 语义割裂:分词器基于统计规则,无法根据上下文动态调整边界(如将 “product” 错误拆分为 “pro-duct” )
- 跨语言/模态适配性差:在中文、代码或
DNA序列等缺乏显式分隔符的领域表现不佳
- 直接字节级建模(如
MambaByte),计算开销巨大,且性能低于分词模型 - 一些启发式分块规则(如
MegaByte和SpaceByte)依赖启发式分块规则(如固定步长或空格分隔),无法学习数据驱动的分块策略,限制了模型对复杂信息的表达能力
H-Net 的解决方案
层级化处理架构(U-Net 式设计)
- 三级模块
- 编码器(
E):处理原始字节(小规模SSM层,高效捕获细粒度特征) - 主网络(
M):处理压缩后的语义块(大规模Transformer层,学习高层抽象) - 解码器(
D):恢复原始分辨率(SSM层)
- 编码器(
- 递归扩展:主网络可嵌套
H-Net自身,形成多级抽象(如字符 → 词 → 短语)
Encoder Network
- 路由模块(
Routing Module)- 用相邻向量的余弦相似度判断是否需要分块
-
- 表示
position - 表示
query - 表示
key - 表示余弦相似度
- 表示当前位置分块概率
- 表示
- 当相邻向量语义变化大时, 会趋近于 1,表示需要分块
- 下采样模块(
Downsampler)- 将上一步分块的序列下采样
- 具体使用的下采样方式是 只保留路由模块选定的边界向量,其他向量直接丢弃
Main Network
- 一个最常见的
Transformer结构 - 输入是
Encoder Network输出的下采样后的向量 - 输出和输入的
shape相同
Decoder Network
- 平滑模块(
Smoothing Module)- 用指数移动平均法解决离散决策的梯度不可导问题
-
- 表示当前位置分块概率
- 表示主网络输出的压缩向量
- 表示上一步平滑后的向量
- 表示平滑后的向量
- 上采样模块(
Upsampler)- 表示当前位置是否分块, 表示分块, 表示不分块
- 表示当前位置分块概率
- 表示当前位置
main network输出的置信度 - 表示当前位置
main network输出的向量 复制到原始分辨率
效果
- 效果比
tokenization更好 - 在语言、代码、DNA等异构数据中验证普适性,为多模态基础模型提供新范式
Thoughts
- 能看出
SSM模型已经开始改变战略,从正面和Transformer硬刚到 曲线救国 STE真是个万金油,哪哪都有它