URL
TL;DR
- 这篇论文构建了一个单一的通用智能体
Gato,它具有多模态、多任务、多实施方式能力,是一个纯端到端的智能体,甚至可以直接给出机械臂动作控制指令。 - 模型就是
1.2B参数的decoder only Transformer架构,只用一份权重可以玩 Atari 游戏、给图片加字幕、控制机械手臂堆叠积木等 604 个任务。
Algorithm
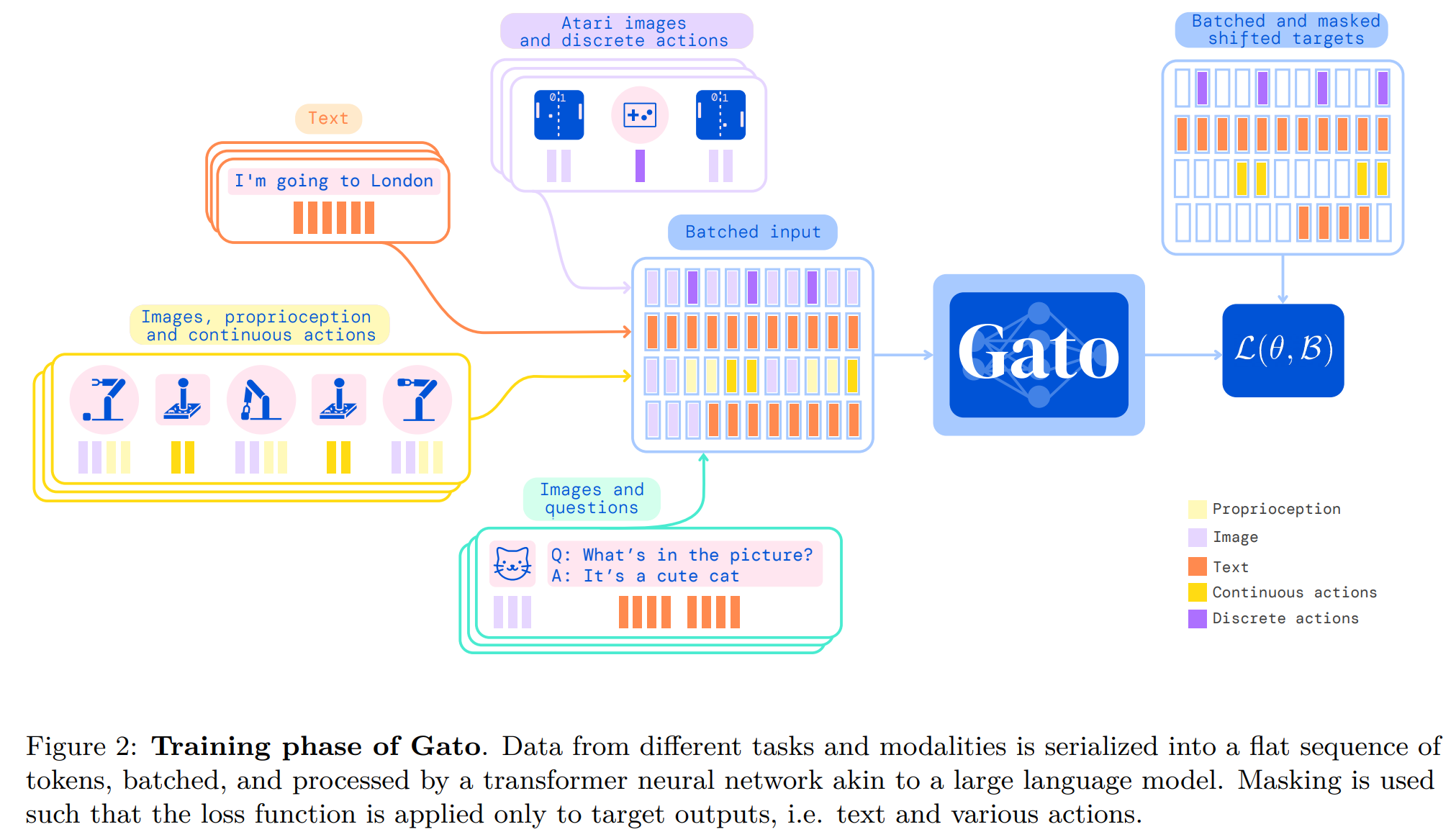
编码方案
Gato 将所有模态的输入和输出都编码为整数序列,输出除了不能输出图像之外,其他模态都可以输出。
- 文本:通过
SentencePiece方式编码,共32000个子单词编码为整数范围[0, 32000) - 图像:按照
ViT的编码方式,切成不重叠的16x16的patches - 离散值:存储为
[0, 1024)的整数序列 - 连续值: 离散化为
1024个箱子,并移到[32000, 33024)的范围
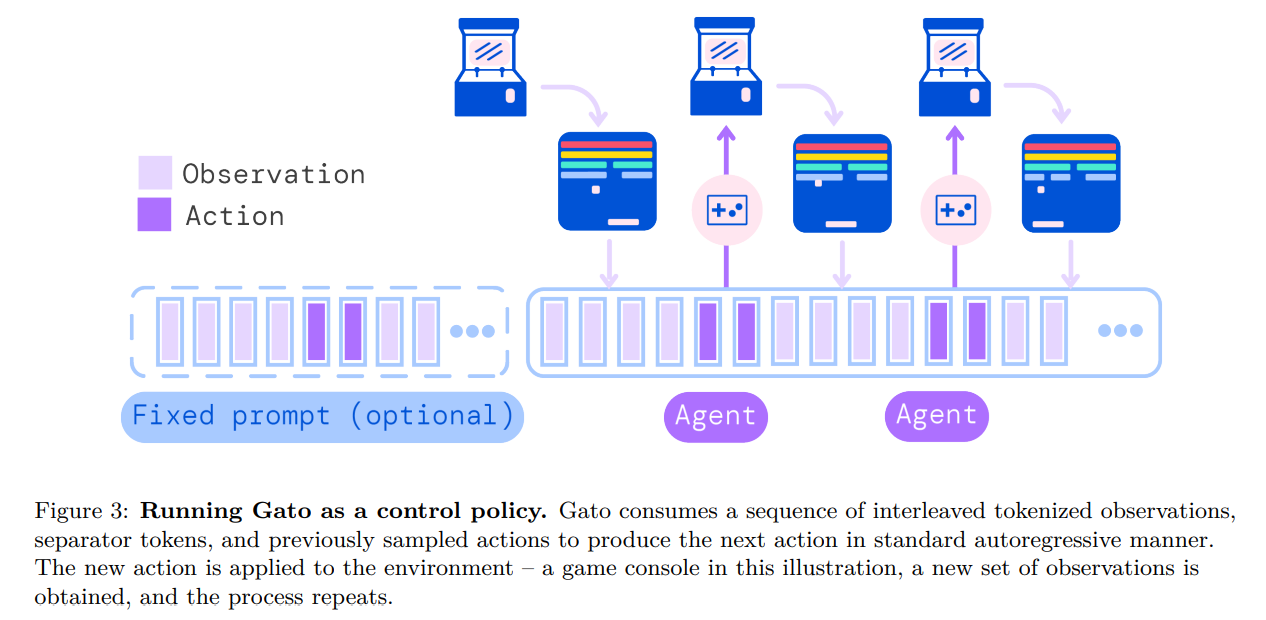
训练和部署方案
- 使用
decoder only Transformer架构,做自回归训练,图像切成16x16的patches后,归一化到[-1, 1]之间,再用Resnet将图像编码成多个特征向量和其他模态的特征向量拼接起来,作为输入。 - 什么参与自回归训练?什么不参与?
- 参与自回归训练的:文本符元、离散和连续值以及动作
- 不参与自回归训练的:图像、智能体观测到的非文本信息(比如机械臂的关节参数等)
- 训练结束后,模型能做什么?
- 训练时候没有屏蔽什么,训练收敛的模型就能做什么。
- 训练时固定上下文长度为
1024,超过1024的数据会被随机截取1024 - 推理时不限制上下文长度
实验结果
- 在
604项任务中,有450项任务能够达到专家分数的50% - 论文中有每个任务类型的详细结果,可以参考论文
Thought
- 把这么多种任务抽象成一种编码,然后用一个
1.2B参数的模型来处理,这个想法很厉害 - 编码方式有点复杂,可以对比下将图片之外的模态转成文本,然后用
tokenizer编码的最终效果