URL
- paper: https://arxiv.org/pdf/2212.06817
- code: https://github.com/google-research/robotics_transformer
- homepage: https://robotics-transformer1.github.io
- dataset: https://console.cloud.google.com/storage/browser/gresearch/rt-1-data-release
TL;DR
- 本文提出了
RT-1模型,本质是一个输入连续6帧图像 + 一句语言指令,输出是11维动作空间的VLA模型,控制一个有可移动底座和一个手臂的机器人,也就是说,RT-1实际上是一个 小脑模型(执行控制模型,输入是相对简单的指令,输出是精细动作控制信号) RT-1首次证明大规模Transformer模型在机器人控制的可行性:通过任务无关训练、高效架构设计及异构数据融合,实现700+任务的97%成功率及显著零样本泛化能力- 整个模型非常轻量,只有
35M的参数
Algorithm
网络结构
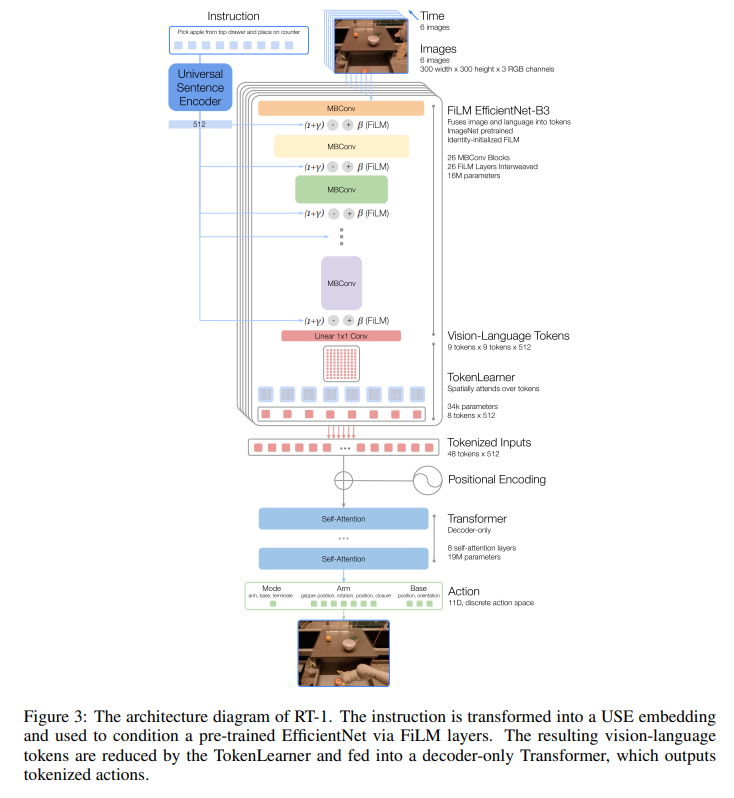
- 模型大概由四部分组成:
| 模块 | 输入形状 | 输出形状 | 关键说明 |
|---|---|---|---|
| Universal Sentence Encoder | 文本字符串 | 512维向量 | 语言语义编码 |
| FiLM EfficientNet-B3 | 6×300×300×3(图像) + 512 | 486×512 | 每帧生成81个视觉Token |
| TokenLearner | 486×512 | 48×512 | 压缩至8 Token/帧 |
| Transformer | 48×512(+位置编码) | 11×256 | 输出离散化动作分布 |
模型输出
- 输出
11维动作空间,每个动作空间都是离散的256个值 11个动作空间分别表示:1个离散维度用于控制模式切换:- 控制底座
- 控制手臂
- 终止
7个维度控制机械臂:- 末端位置:
x, y, z - 末端姿态:
roll, pitch, yaw - 抓夹:开合度
- 末端位置:
3个维度控制底座:- 位置:
x, y - 旋转角度:
yaw
- 位置:
数据集
Thoughts
- 模型很简单,数据很简单,训练范式也很简单,但泛化能力很强
RT-1数据开源,推动具身智能社区发展