URL
TL;DR
- 本文主要介绍
Qwen3-Next 架构,由于还没有发正式论文,所以主要参考官方博客和 transformers 实现代码
架构优化
混合架构
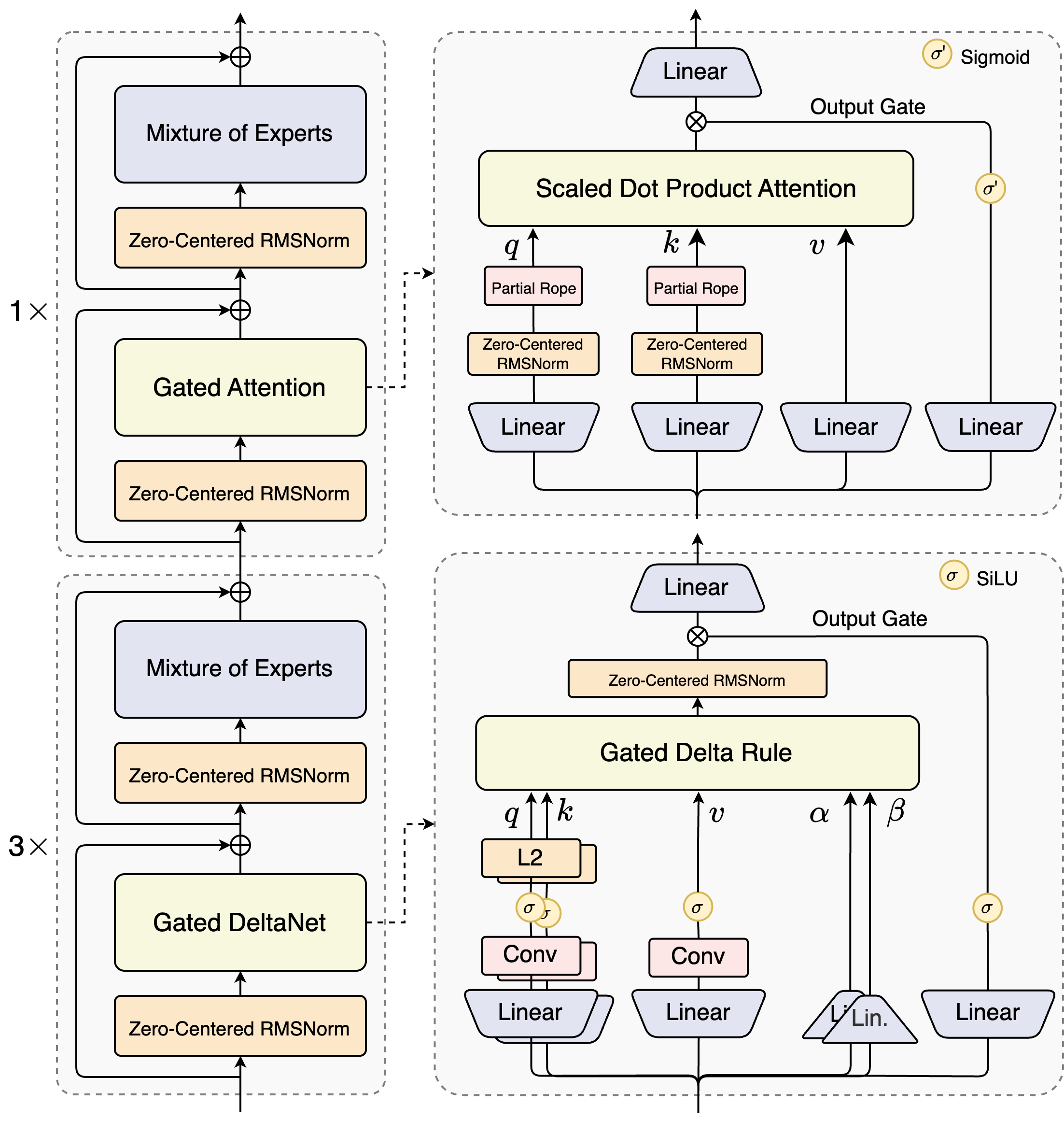
Output=SDPA(Q,K,V)⊙σ(XWθ)
- 二者层数占比:
GatedDeltaNet 占比 75%GatedAttention 占比 25%
极致稀疏 MoE
- 共有
512 个专家,每次只激活 10 个路由专家 + 1 个共享专家
- 激活参数只占原参数的
3.7%,因此采用 80B-A3 这种又大又快的模型
训练稳定性友好设计
Zero-Centered RMSNorm
- 在
GatedAttention 的 QK Norm (上图中 QK 做 Attention 之前的)用 Zero-Centered RMSNorm
LayerNorm(x)=N1∑1N(xi−μ)2+ϵx−μ⋅γ+β
RMSNorm(xi)=N1∑1Nxi2+ϵx⋅γ
Zero-Centered RMSNorm(x)=N1∑1N(xi−μ)2+ϵx−μ⋅γ
- 从公式上看
Zero-Centered RMSNorm 本质就是不带 β 的 LayerNorm
MoE router 权重初始化
- 初始化时归一化了
MoE router 的参数,确保每个 expert 在训练早期都能被无偏地选中,减小初始化对实验结果的扰动
Multi-Token Prediction
- 和
DeepSeek-V3 的 MTP 的区别是:本 MTP 不仅在训练时候预测多个,推理的时候也预测多个,非常方便 Speculative Decoding
预训练
Qwen3-Next 采用的是 Qwen3 36T 预训练语料的一个均匀采样子集,仅包含 15T tokens
Thoughts
Qwen3-Next-80B-A3B 比 Qwen3-32B 效果更好,速度更快,这主要归功于超稀疏 MoE 带来的计算量显著下降,以及 GatedDeltaNet 带来的平方复杂度到线性复杂度的下降- 预训练竟然会对数据做采样使用,这个有点反直觉,后续会关注论文中有没有详细解释