URL
TL;DR
- 本文的标题很直白《通过反向传播进行无监督领域自适应》,目标是实现无监督领域自适应。
- 提出了梯度反转层 (
Gradient Reversal Layer, GRL),用于无监督领域自适应任务中,通过在特征提取器和领域分类器之间插入GRL,实现特征提取器在训练过程中 最大化 领域分类器的损失,从而通过对抗学习到领域不变的特征表示。 - 和
GAN的思想有些类似,不过GAN的目标是生成,GRL的目标是表征。
Algorithm
什么是无监督领域自适应
- 领域自适应 (
Domain Adaptation) 是迁移学习 (Transfer Learning) 的核心问题之一,旨在将从源领域 (Source Domain) 学习到的知识迁移到目标领域 (Target Domain)。

- 比如上图所示,有一批
MNIST黑底白字的手写数字识别数据集,包含图像和标签,作为源领域;还有一批背景和字体颜色都随机的MNIST-M手写数字识别数据集,只有图像没有标签,作为目标领域。 - 目标是利用源领域的有标签数据训练一个分类器,并使其在目标领域上也能有较好的性能。
如何实现无监督领域自适应
- 最直接的方法:在源领域数据上训练,直接迁移到目标领域。但效果显然会很差,因为两个领域的数据分布差异较大。
- 本文提出的方法:通过对抗训练学习领域不变的特征表示。
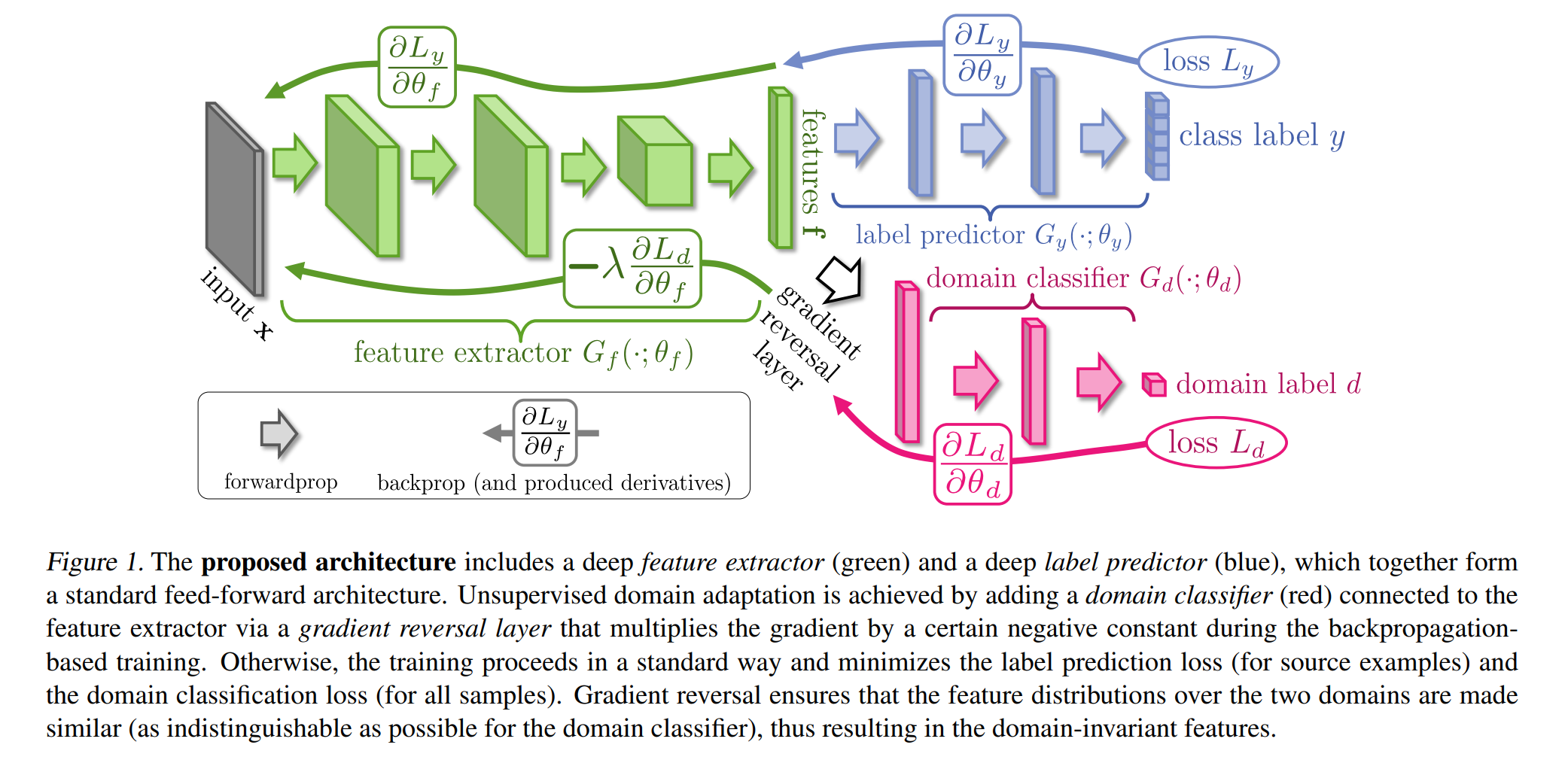
- 模型分成三个部分:
- 特征提取器 (
Feature Extractor, G_f): 提取输入数据的特征表示,上图绿色部分。 - 标签分类器 (
Label Classifier, G_y): 根据特征表示预测标签,上图蓝色部分。 - 领域分类器 (
Domain Classifier, G_d): 根据特征表示预测数据来自哪个领域(源领域或目标领域),上图红色部分。
- 特征提取器 (
- 训练目标:
- 最小化标签分类器的损失,使其在源领域数据上表现良好。
- 最大化(注意这里是最大化,不是最小化)领域分类器的损失,使特征提取器学习到领域不变的特征表示。
- 损失函数:
- 标签分类器只对源领域数据计算交叉熵损失 。
- 领域分类器对源领域和目标领域数据都计算交叉熵损失
- 两个损失直接求和就是总损失 (一定要注意这里没有 ,别被论文带沟里去)。
- 梯度反转层 (
Gradient Reversal Layer, GRL) 如何起作用:- 位置:插入在特征提取器和领域分类器之间。
- 前向传播:
GRL不改变输入,直接将特征传递给领域分类器。 - 反向传播:
GRL将从领域分类器传回的梯度乘以一个负的常数-λ,使得特征提取器在更新时朝着最大化领域分类器损失的方向调整参数。
- 梯度反转层的数学表达(设输入特征为
x,GRL的输出为y):- 前向传播:
y = x - 反向传播:
dL/dx = -λ * dL/dy
- 前向传播:
- 梯度反转层的
PyTorch实现:
1 | import torch |
- 的调节:从
0逐渐增加到1,意义:- 训练初期,,模型主要关注源领域的标签分类任务,确保分类器能学到有用的特征。
- 随着训练进行,逐渐增加 ,模型开始更多地关注领域分类器的对抗任务,促使特征提取器学习到领域不变的特征表示。
Thoughts
- 很有趣的对抗学习设计,很简单但很有效。
- 本质就是让领域分类器掌握的领域分类知识泄露给特征提取器,从而让特征提取器不断调整自己提取的特征,使得领域分类器无法区分源领域和目标领域的数据。