URL
- paper: https://arxiv.org/pdf/2410.23262
- code(民间实现):https://github.com/taco-group/OpenEMMA/blob/main/README_zh-CN.md
TL;DR
EMMA是Waymo提出的端到端自动驾驶VLA模型,不像RT-1和RT-2模型输出离散化的动作token,EMMA的输出是纯文本。- 模型架构特别简单,就是一个标准的
VLM({image, text} -> {text}),在预训练基础上进行自动驾驶数据和通用多模态数据共训练得到。 - 纯
VLA架构,没有除图和文之外的其他任何模态(例如激光雷达、毫米波雷达、高精度地图定位等)。
Algorithms
核心思想
- 核心思想:将自动驾驶任务转化为语言建模问题
- 将所有文本类数据都统一到纯自然语言空间,不做任何的编码,这样所有任务都能在一个“语言空间”中统一表示与训练,利用预训练权重中的语言知识和推理能力。
| 类型 | 表示方式 |
|---|---|
| 视觉输入 (V) | 多摄像头拼接图像或视频帧 |
| 非视觉输入 (T) | 文本(包括导航意图、历史状态等) |
| 输出 (O) | 文本(轨迹点、3D框、车道线等) |
模型架构
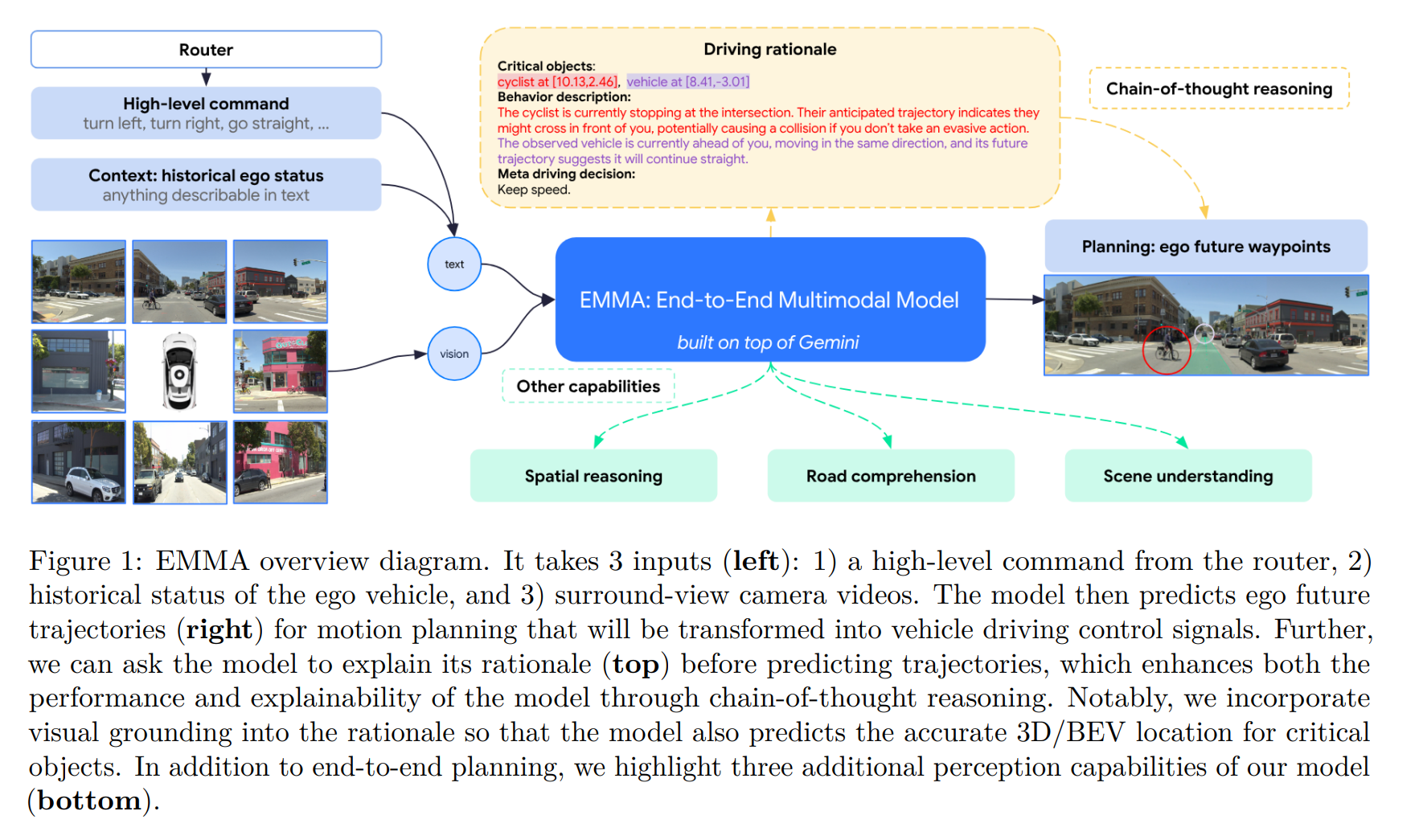
模型能力
EMMA有三大能力:- 端到端运动规划(E2E Planning)
- 推理增强 (Chain-of-Thought)
- 通用多任务(Generalist EMMA)
- 这三种能力均来自于同一个模型的同一组参数,区别只是
prompt中描述的任务内容不同。
1. 端到端运动规划能力
- 输入:
- 视频图像 V(多相机)
- 高层导航意图 Tintent(如 “turn left”)
- 历史自车轨迹 Tego(BEV坐标文本序列)
- 输出:
- 未来轨迹 Otrajectory:未来 Tf 个时刻的坐标 {(xt, yt)},纯文本形式输出
- 监督:
- 自监督,仅需未来轨迹真实值(无需人工标注)
- 无需 HD 地图,无需 LiDAR
2. 思维链推理增强能力
- 在输出轨迹前,模型生成 4 层“推理文本”,如下
| 层级 | 含义 | 示例 |
|---|---|---|
| R1 | 场景描述(天气、路况等) | “It’s sunny and the road is four-lane…” |
| R2 | 关键物体及其坐标 | “Pedestrian at [9.01, 3.22], vehicle at [11.58, 0.35]” |
| R3 | 关键物体行为 | “The pedestrian looks toward the road and may cross.” |
| R4 | 元驾驶决策 | “I should keep my current low speed.” |
- 训练标签自动生成:
- 由专家感知模型+启发式算法+Gemini生成描述 → 无需人工标注
- 效果:
- CoT 提升规划质量约 6.7%
- 关键贡献来自 meta-decision (+3.0%) 与关键对象识别 (+1.5%)
3. 通用多任务
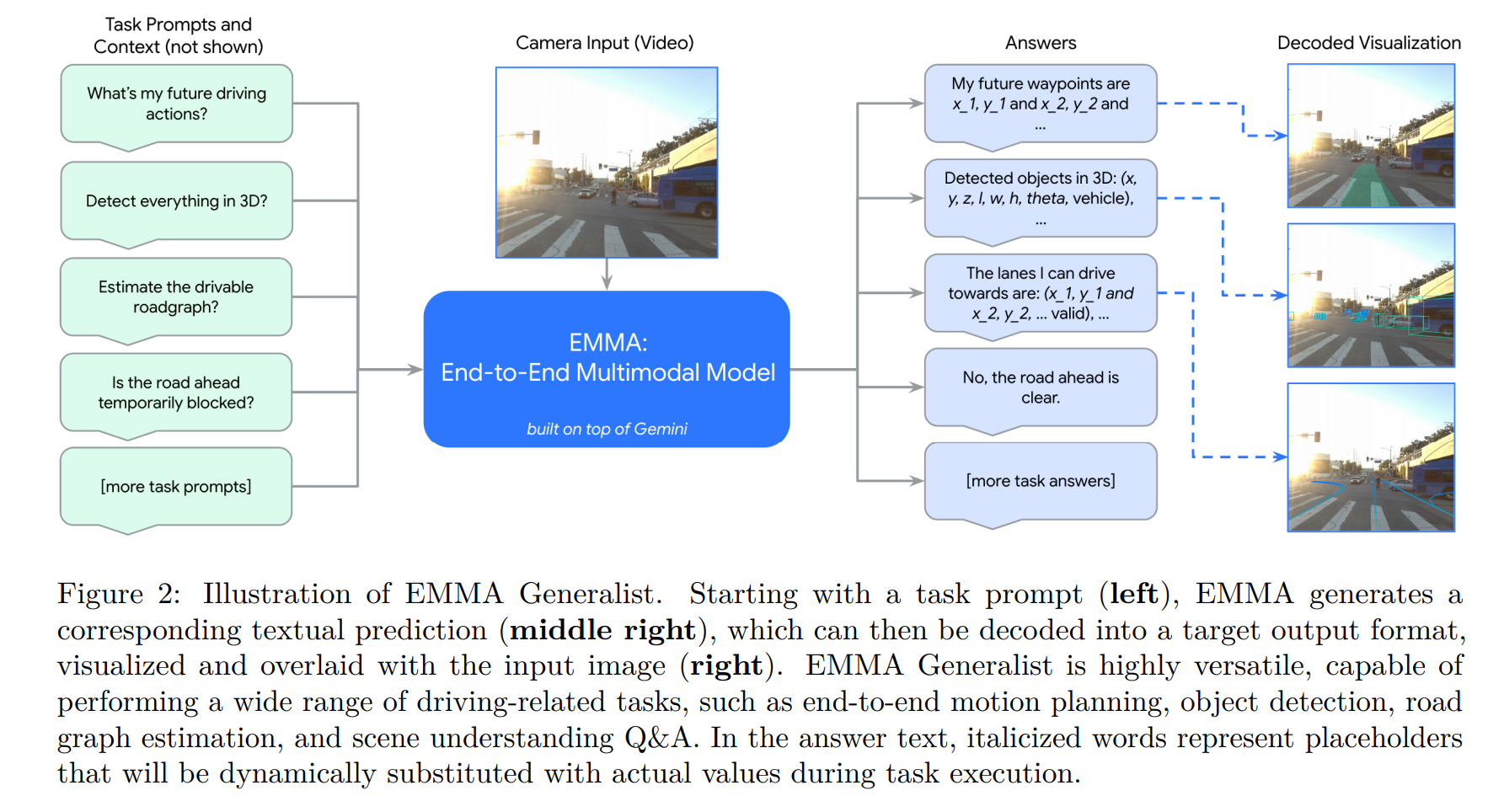
模型表现
- 一句话概括:在所有任务上,超越所有 SOTA
Thought
- 和某车企复杂晦涩的
VLA框架相比,EMMA简直太优雅了,没有复杂的设计,统一框架上解决所有自动驾驶问题 - 如果只做端到端,甚至不需要数据标注,只需要把驾驶数据的数量和质量堆上去就行
- 可以只输出感知结果,也可以端到端,甚至
CoT还可以做到白盒端到端,太雅了…