URL
- paper: https://arxiv.org/pdf/2307.15818
- homepage: https://robotics-transformer2.github.io/
TL;DR
- 本文算是第一个真正意义上的
VLA模型,和RT-1相比,有两个显著特征:- 使用了大量互联网的
VL数据和Robotic数据混合训练做co-fine-tuning - 模型更大了,
5 - 55B规模参数量,且co-fine-tuning的起点模型就是在互联网数据上训练收敛的模型
- 使用了大量互联网的
Algorithm
RT-1 的意义是什么?
RT-1最主要的意义是证明了:将机器人控制信号离散化为动作 token,用 transformer 架构直接预测是可行的- 既然架构是可行的,那就顺其自然做
scaling(放大数据量和参数量)
RT-2 做了什么?
1. 起点是个 VLM
RT-2分别用了谷歌自家的PaLM-E和PaLI-X两个多模态模型做为起点模型,两个模型都是单独使用的- 二者都是
ViT+LLM架构,且都是{image, text} -> {text}范式
2. 统一 VL 和 Robotic 数据格式
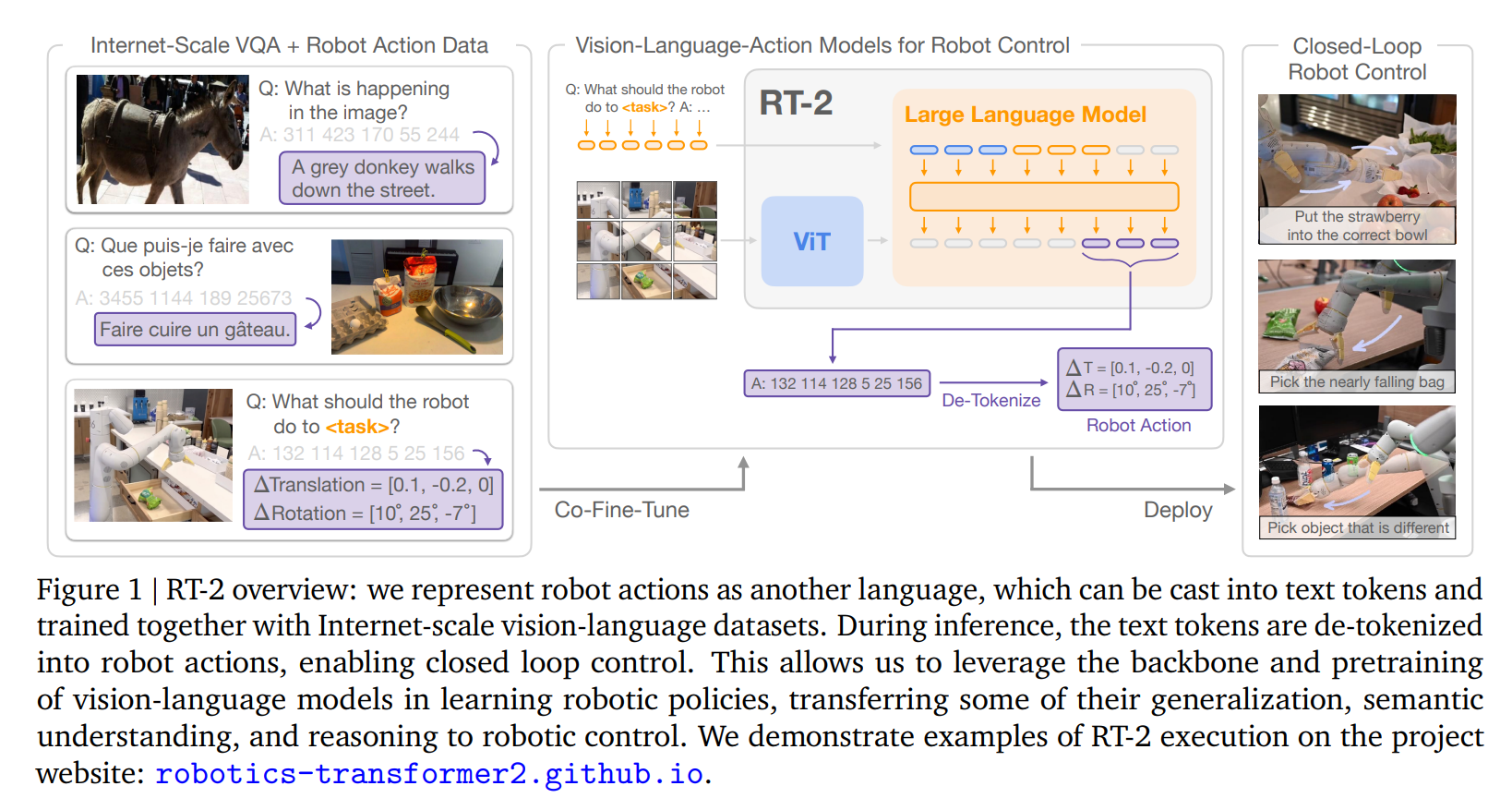
- 方法和
RT-1一样,将机器人动作信号离散化,并编码成动作token - 具体来说:
- 8-DoF 动作空间:6 个自由度(位置 + 旋转)+ 手爪开合 + “终止”标志
- 每个连续维度被离散化为 256 个 bin
- 每个 bin 对应一个 token
- 将 VLM 已有的 tokens 与这 256 个离散量联系起来,才能实现 VLM 到 VLA 的转换
- PaLI-X 和 PaLM-E 使用不同的 tokenization 方法,action tokens 需要与分别与其保持一致:
- PaLI-X:1000 以内的每个数字都有一个相应的token,因此只需将 256 个离散量等于 256 个整数即可
- PaLM-E:将最少出现的 256 个 tokens 覆盖掉,分别对应 256 个离散量
3. 混合数据集
- vision-language datasets:来源于 PaLI-x 和 Palm-e 所使用的数据集,数据包括:
- VQA: visual question answering
- Captioning
- unstructured interwoven image and text examples
- PaLI数据集(WebLI)大小:10B images and covering over 109 anguages
- Palm-e 使用多个数据集联合训练,其中 WebLI 占比52.4%
- robotics dataset:RT1 dataset(13个机器人,17个月收集得到的数据)
- 混合方式:co-fine-tuning 过程中,对数据做加权
- RT-2-PaLI-X 中 robotics 数据占 50%
- RT-2-PaLM-E 中 robotics 数据占 66%
泛化能力如何?
1. 在没见过的物体、背景、环境下的泛化能力

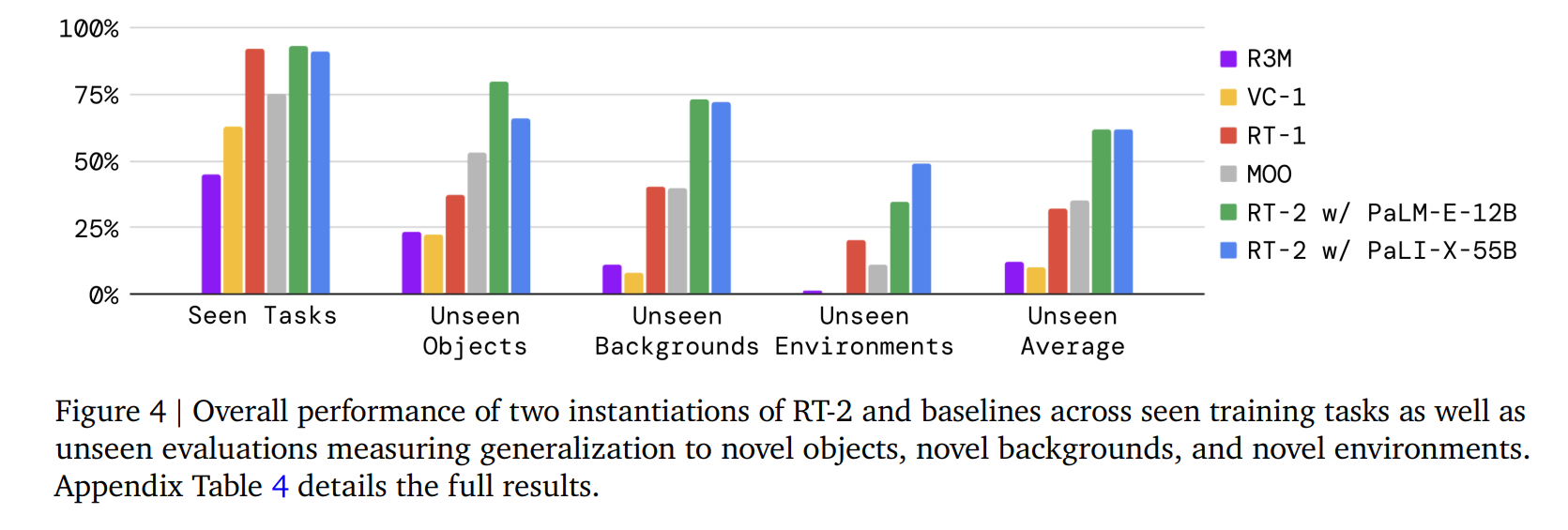
在同场景下,
RT-2和RT-1差别很小,在没见过的物体、背景、环境下,RT-2遥遥领先
2. 涌现能力
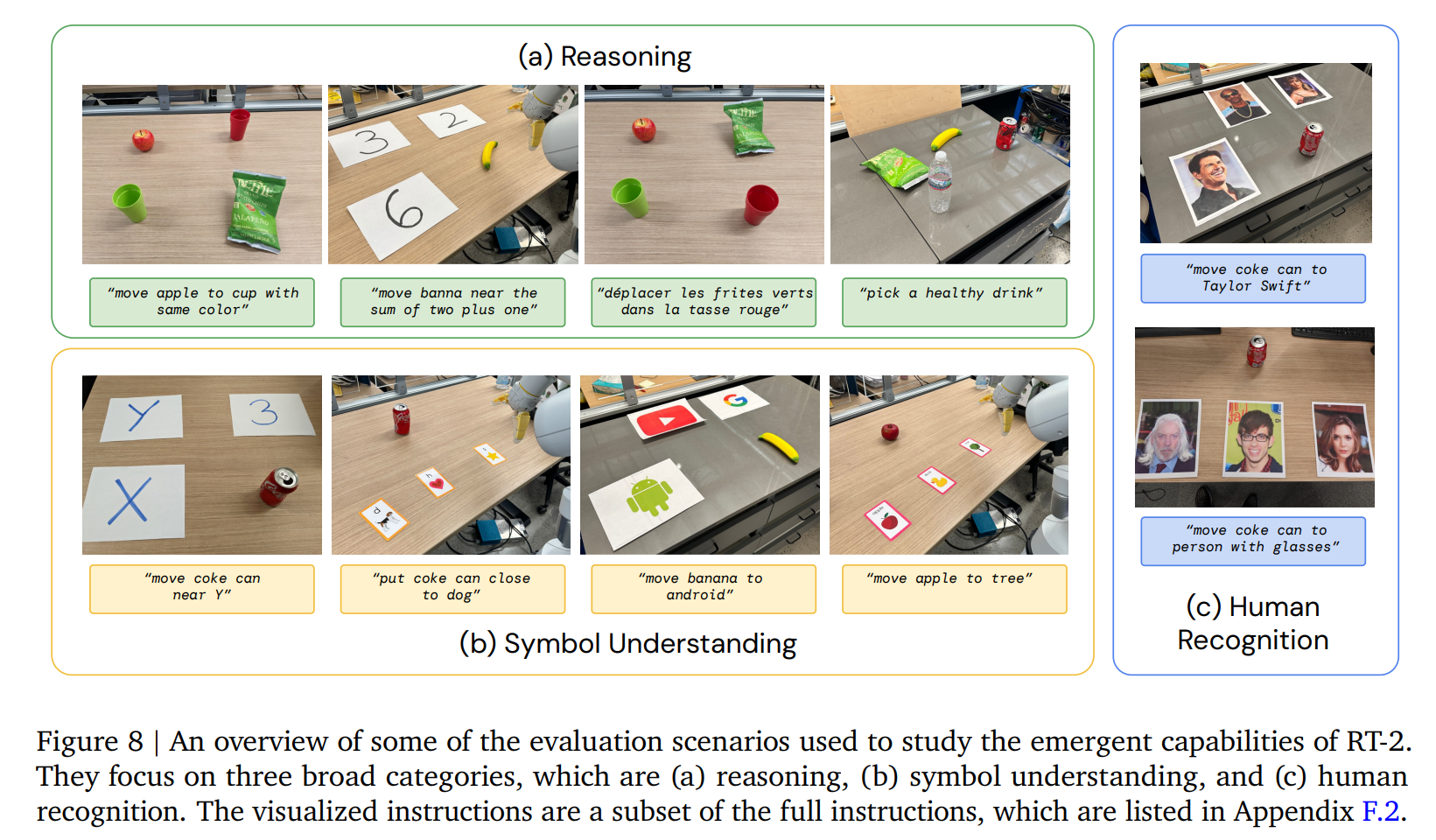
3. CoT 能力
- 在
robotic数据的动作token之前,加入resoning token,会提高模型解决问题的能力

resoning即图中的plan部分
局限性和展望
- 局限:
- 物理技能仍局限于机器人数据分布(无法生成全新动作)。
- 推理频率低,云端计算成本高。
- 未来方向:
- 结合人类视频学习新技能;
- 模型量化与蒸馏以提升实时性;
- 更多开源 VLM 融合(如 LLaVA、InternVL 等)。
Thought
- 很有趣的工作,ppl 非常简单,引领了之后
VLA的发展