URL
TL;DR
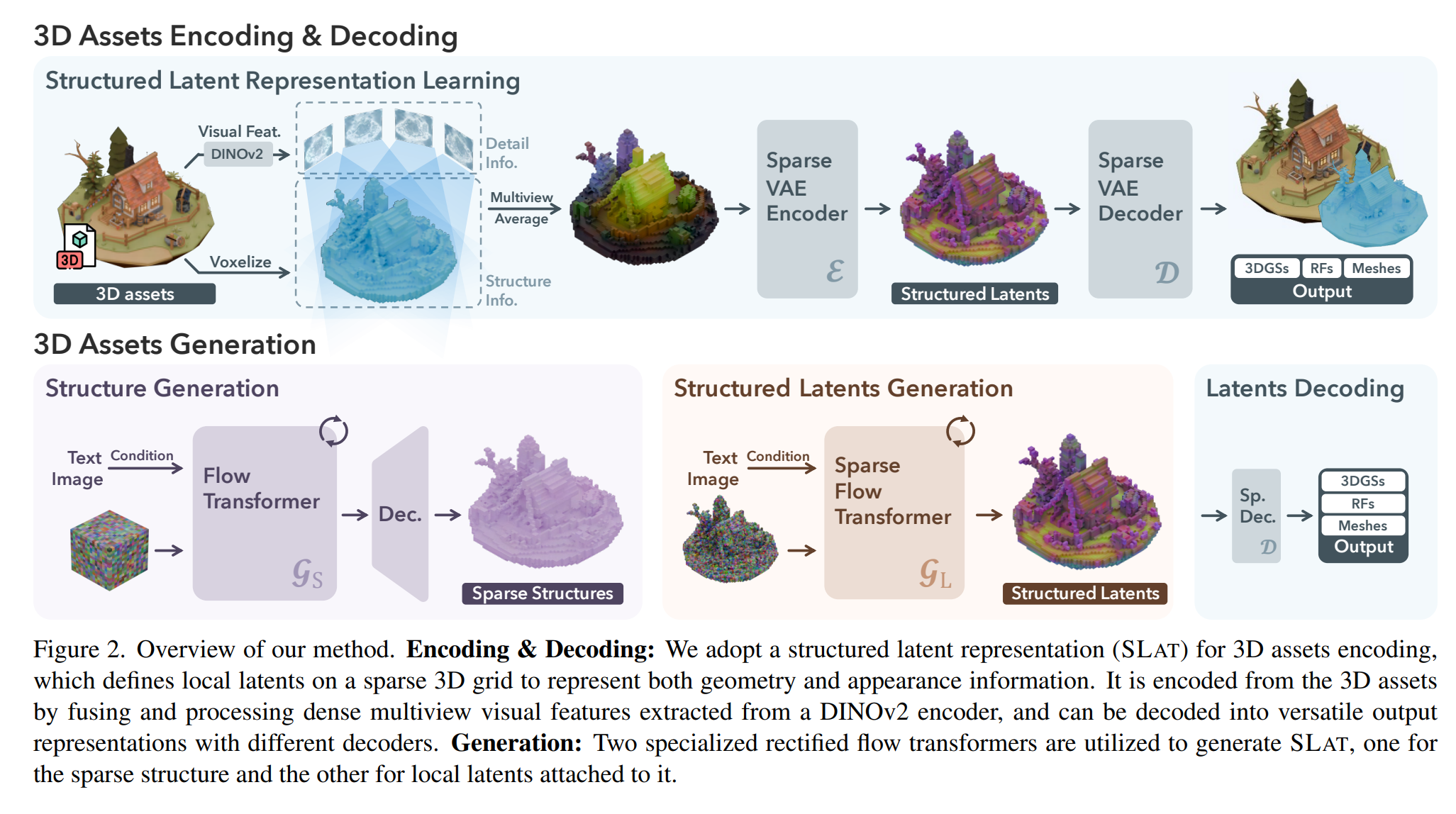
- 本文提出一个图/文生
3D 的模型 TRELLIS 和一种 3D 表征方式 SLAT (Structured LATent),具体来说 SLAT 表征包含两个部分:
coords: 整数坐标 (N, 4) int32 - [batch, x, y, z],用于描述 163 voxel 空间下的物体 表面 占据的体素坐标feats: 浮点特征 (N, 8) float32 - 8通道特征向量,用于描述每一个激活体素坐标上的特征编码,编码长度为 8
- 关键就是两个
DiT 模型,两个模型的输出结果合并就是 SLAT 表征,两个 DiT 都是使用流匹配范式训练的
- 第一个
DiT 模型从图像/文本特征中得到 3D 物体的表明占据体素坐标,这个模型被称为 SparseStructureFlowModel
- 第二个
DiT 模型从图像/文本特征以及体素占据坐标得到每个激活体素的特征向量,这个模型被称为 ElasticSLatFlowModel
- 模型在
3D 数据集上通过自监督方式训练得到,可从图片或文本得到不同的 3D 输出格式(3D Gaussian、Radiance Field、mesh 等)
Algorithm
1. 推理过程
flowchart TD
A[输入图片] --> B[预处理 518x518]
B --> C[DINOv2编码 Bx1369x1024]
C --> D[Stage 1: Sparse Structure Flow]
D --> E[噪声 Bx8x16x16x16]
E --> F[DiT Transformer 24层]
C --> F
F --> G[Sparse Structure Latent Bx8x16x16x16]
G --> H[Decoder]
H --> I[稀疏坐标 Nx4]
I --> J[Stage 2: SLAT Flow]
J --> K[稀疏噪声 SparseTensor Nx8]
K --> L[稀疏DiT Transformer 24层]
C --> L
L --> M[SLAT表征 SparseTensor Nx8 分辨率64^3]
M --> N[Gaussian解码器]
M --> O[Radiance Field解码器]
M --> P[Mesh解码器]
N --> Q[3D Gaussians]
O --> S[Strivect辐射场]
P --> T[三角网格]
0: 图像预处理
- 功能:去除背景、裁剪、归一化
- 输入:原始PIL图像(任意尺寸)
- 输出:518×518 RGB图像,带alpha通道
- 处理步骤:
- 使用 rembg (U2-Net) 去除背景
- 根据前景内容裁剪并居中
- 调整大小到 518×518
1: 图像条件编码
- 模型:DINOv2 ViT-L/14-reg
- 输入:(B, 3, 518, 518) - 预处理后的图像
- 输出:(B, N, 1024) - 图像特征tokens,其中 N = (518/14)² = 1369(37 x 37)
- 处理:通过 DINOv2 提取 patch tokens
2: 稀疏结构生成 (Stage 1)
- 模型:SparseStructureFlowModel(DiT)
- 输入:
- Noise: (B, 8, 16, 16, 16) - 3D噪声张量
- Image condition: (B, 1369, 1024) - DINOv2特征
- Timestep: (B,) - Flow matching时间步
- 处理流程:
- 将3D噪声 patchify(如果patch_size>1)
- 添加3D位置编码
- 通过24层 DiT transformer blocks,进行图像条件的交叉注意力
- Unpatchify 回3D体积
- 输出:(B, 8, 16, 16, 16) - 稀疏结构latent
- 解码到坐标:
- 通过 SparseStructureDecoder 解码为occupancy grid
- Resolution: 16³
- 提取 occupancy > 0 的体素坐标
- 解码器输出:(B, 1, 16, 16, 16) - occupancy概率
- 提取坐标:(N_occupied, 4) - [batch_idx, x, y, z],其中 N_occupied 是非空体素数量
3: SLAT 生成 (Stage 2) - 核心表征
- 模型:ElasticSLatFlowModel
- 输入:
- Sparse noise: SparseTensor
- coords: (N_voxels, 4) - 从Stage 1得到的坐标
- feats: (N_voxels, 8) - 随机噪声特征
- Image condition: (B, 1369, 1024) - DINOv2特征
- Timestep: (B,) - Flow matching时间步
- 处理流程:
- 通过sparse linear层和下采样ResBlocks处理输入 (2倍下采样)
- 添加稀疏3D位置编码
- 通过24层稀疏DiT transformer blocks,带图像交叉注意力
- 通过上采样ResBlocks和skip connections恢复分辨率
- 输出层产生8通道特征
- 输出 - SLAT表征:SparseTensor
- coords: (N_voxels, 4) - [batch_idx, x, y, z],坐标在64³空间
- feats: (N_voxels, 8) - 8通道特征,应用归一化
4: SLAT 解码到多种3D表征
- SLAT (Structured Latent) 是TRELLIS的统一3D表征,以稀疏张量格式存储,可以解码为三种不同的3D资产格式:
- Gaussian Splatting 解码
- Radiance Field 解码
- Mesh 解码
2. 训练过程
0. 数据准备与多视角特征提取
- 输入:
- 3D 资产模型(mesh 或 point cloud)
- 渲染器生成的多视角 RGB 图像(约 150 views)
- 每张图的相机姿态(R, t, intrinsics)
- 过程:
- 使用预训练视觉模型 DINOv2 提取每张图的 patch-level 特征(每张图被切成 37x37 个 patch,每个 patch 提取成 1024 长度的特征向量);
- 将 3D 资产 voxel 化(64 x 64 x 64 分辨率)
- 体素稀疏化,只保留表面区域激活体素,平均每个样本保留 20k 左右的体素;
- 通过已知相机位姿把这些特征反投影到 3D voxel grid;
- 在每个 voxel 聚合多视角特征(平均 / max pooling)→ 得到 voxel feature grid f(x, y, z);
- 输出:
- 稀疏 3D 特征 (pi, fi) 组成的序列(active voxels),pi 表示体素 i 的位置坐标,fi 表示体素 i 的特征向量
1. 训练稀疏结构生成模型 SparseStructureFlowModel
- 输入:
| 名称 |
Shape |
含义 |
| noise |
(B, 8, 16, 16, 16) |
初始高斯噪声 |
| image_feats |
(B, 1369, 1024) |
DINOv2 提取的图像特征 |
| t |
(B,) |
flow matching 时间步 |
- 输出:
| 名称 |
Shape |
含义 |
| latent |
(B, 8, 16, 16, 16) |
生成的体素 latent |
| occupancy |
(B, 1, 16, 16, 16) |
occupancy 概率 (经解码器预测) |
- 监督信号:监督目标来自 ground-truth occupancy grids(稀疏体素结构),根据 3d 资产可以得到(64 下采样到 16)
2. 训练 SLAT 核心生成 (ElasticSLatFlowModel)
- 输入:
| 输入 |
说明 |
| Sparse coords |
Stage 1 输出的非空体素坐标 |
| Sparse feats |
随机噪声特征 (8维) |
| Image feats |
DINOv2 图像特征 |
| t |
时间步,用于 flow matching |
- 输出:
| 输出 |
Shape |
含义 |
| SLAT coords |
(N_voxels, 4) |
稀疏坐标 (batch,x,y,z) |
| SLAT feats |
(N_voxels, 8) |
稀疏latent特征 |
- 监督信号(SLAT 表征无法直接监督,需要 decode 为 3D 才可以):
- 多视图渲染监督
- 对每个 3D 资产有多视角图像
- SLAT → 解码为 NeRF / Gaussian → 渲染成图像
- 与真实视图计算重建损失
- 几何一致性监督:SLAT → 解码为 mesh / occupancy → 与真实 mesh 计算 Chamfer 距离
- 稀疏特征正则化:约束 latent 特征的分布,促进稀疏性和稳定性
3. 训练多格式解码器
- SLAT 是统一稀疏latent论文中提到它可被解码为三种不同的 3D 资产类型:Gaussian / Radiance Field / Mesh
- 这三个解码器各自独立训练,共享同一 SLAT latent 空间
Thought
3D 生成基本都几何结构 + 纹理信息分开训练,都是用 Diffusion 模型在隐空间做,图像 / 文本作为 Diffusion 的 condition- 生成的
3D 模型 -> 渲染得到某个视角的 2D 图片,和原始 3D 模型对应视角渲染图片做 pixel-level 的损失,是自监督 3D 生成模型绕不开的