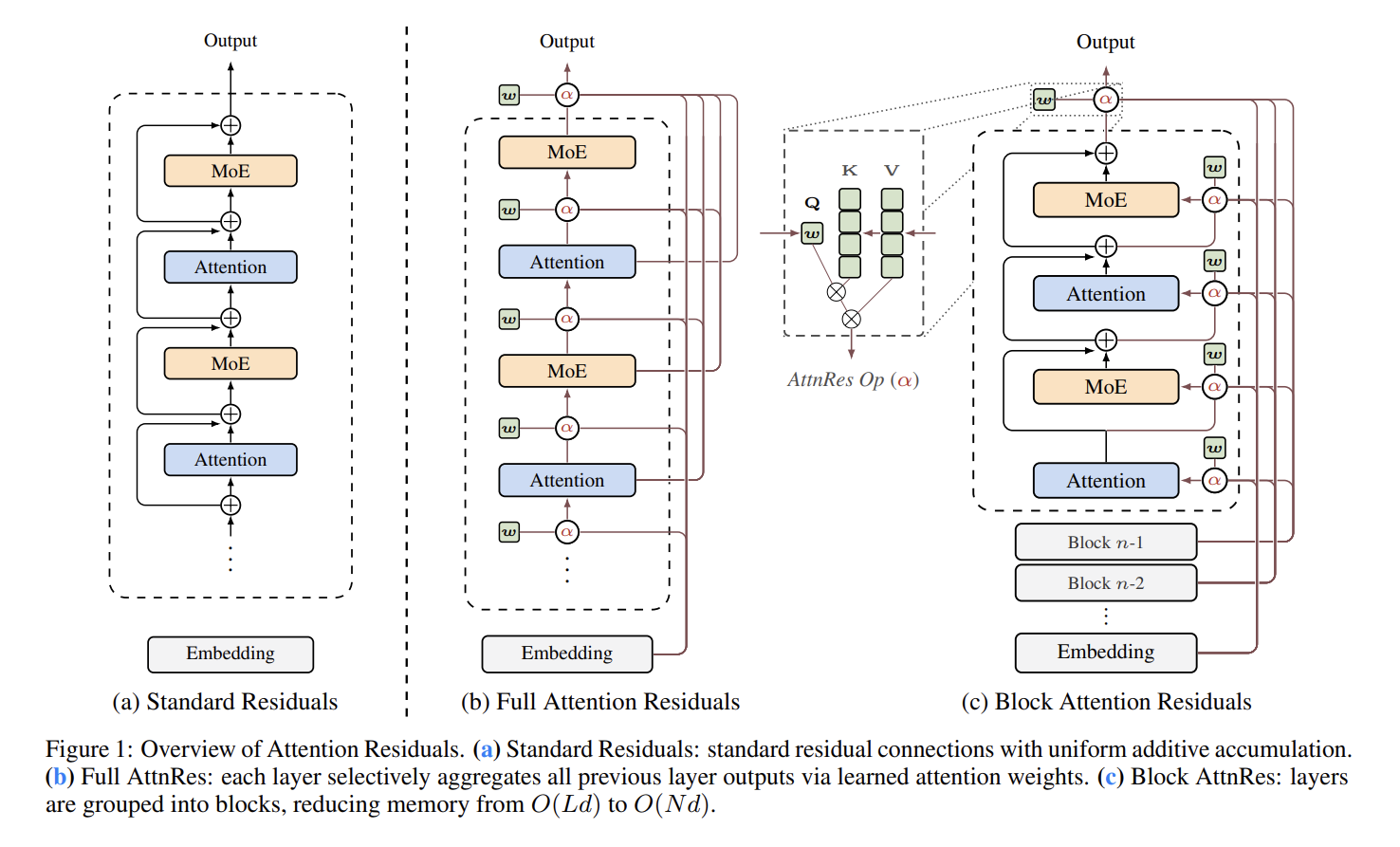
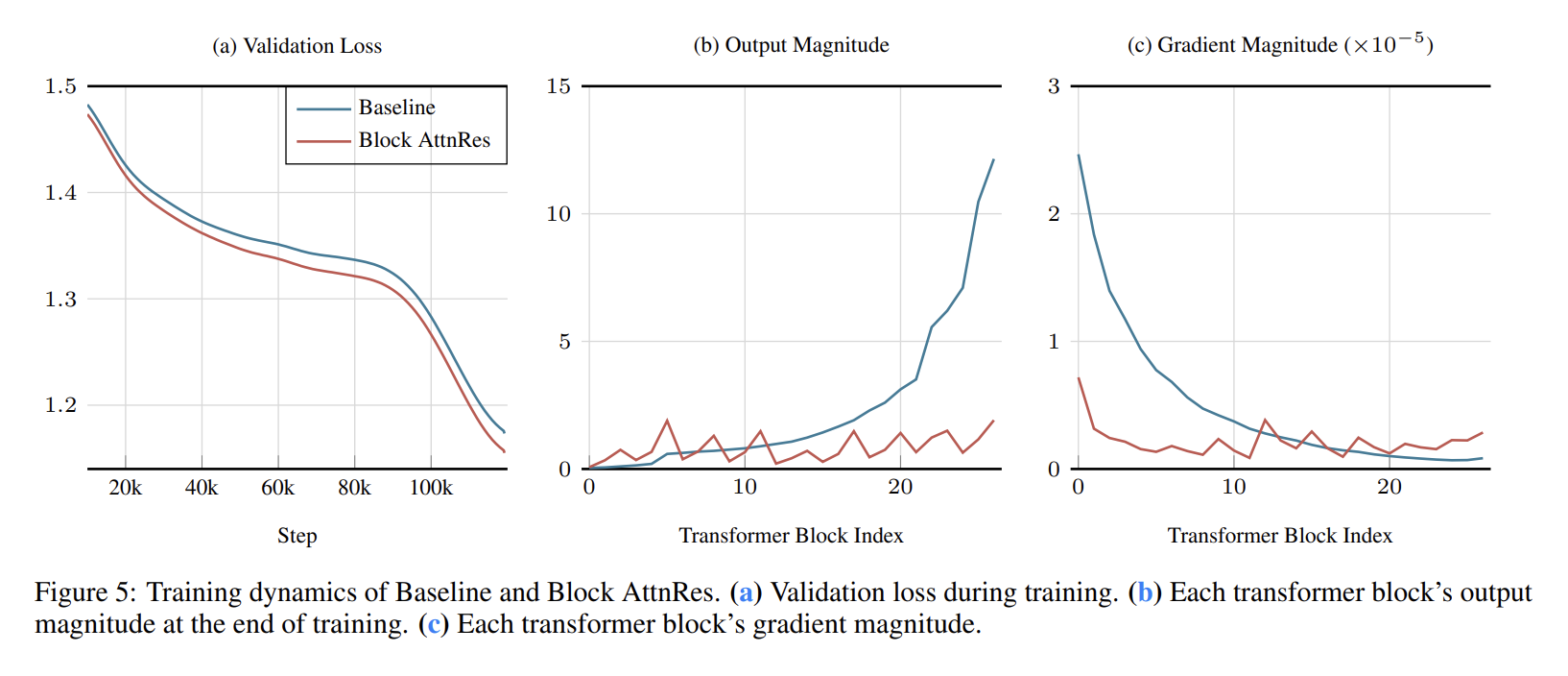
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
| def block_attn_res(
blocks: list[Tensor],
partial_block: Tensor,
proj: Linear,
norm: RMSNorm
) -> Tensor:
"""
跨块注意力:在 [已完成块] + [当前块部分和] 上进行选择性聚合
"""
V = torch.stack(blocks + [partial_block])
K = norm(V)
logits = torch.einsum('d, n b t d -> n b t', proj.weight.squeeze(), K)
h = torch.einsum('n b t, n b t d -> b t d', logits.softmax(0), V)
return h
def forward(
self,
blocks: list[Tensor],
hidden_states: Tensor
) -> tuple[list[Tensor], Tensor]:
"""
单层前向传播,维护块内残差累积 + 块间注意力聚合
"""
partial_block = hidden_states
h = block_attn_res(
blocks,
partial_block,
self.attn_res_proj,
self.attn_res_norm
)
if self.layer_number % (self.block_size // 2) == 0:
blocks.append(partial_block)
partial_block = None
attn_out = self.attn(self.attn_norm(h))
if partial_block is not None:
partial_block = partial_block + attn_out
else:
partial_block = attn_out
h = block_attn_res(
blocks,
partial_block,
self.mlp_res_proj,
self.mlp_res_norm
)
mlp_out = self.mlp(self.mlp_norm(h))
partial_block = partial_block + mlp_out
return blocks, partial_block
|