URL
https://arxiv.org/pdf/2006.15102.pdf
TL;DR
ULSAM是一个超轻量级的子空间注意力网络,适合用在轻量级的网络中,例如MobileNet、ShuffleNet等- 适合用在图像细粒度分类任务中,能减少大约
13%的Flops和大约25%的params,在ImageNet - 1K和 其他三个细粒度分类数据集上Top1 error分别降低0.27%和1% - 与 SENet 有点类似,
SENet在C维度上添加注意力,ULSAM在HW维度上添加注意力
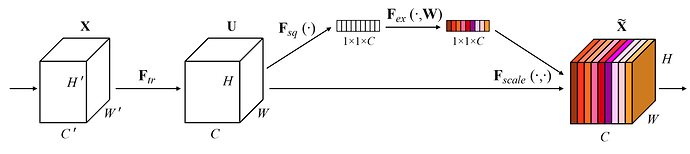
Algorithm
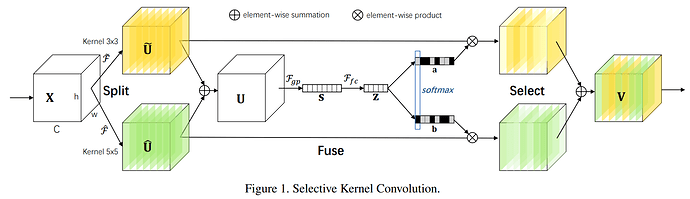
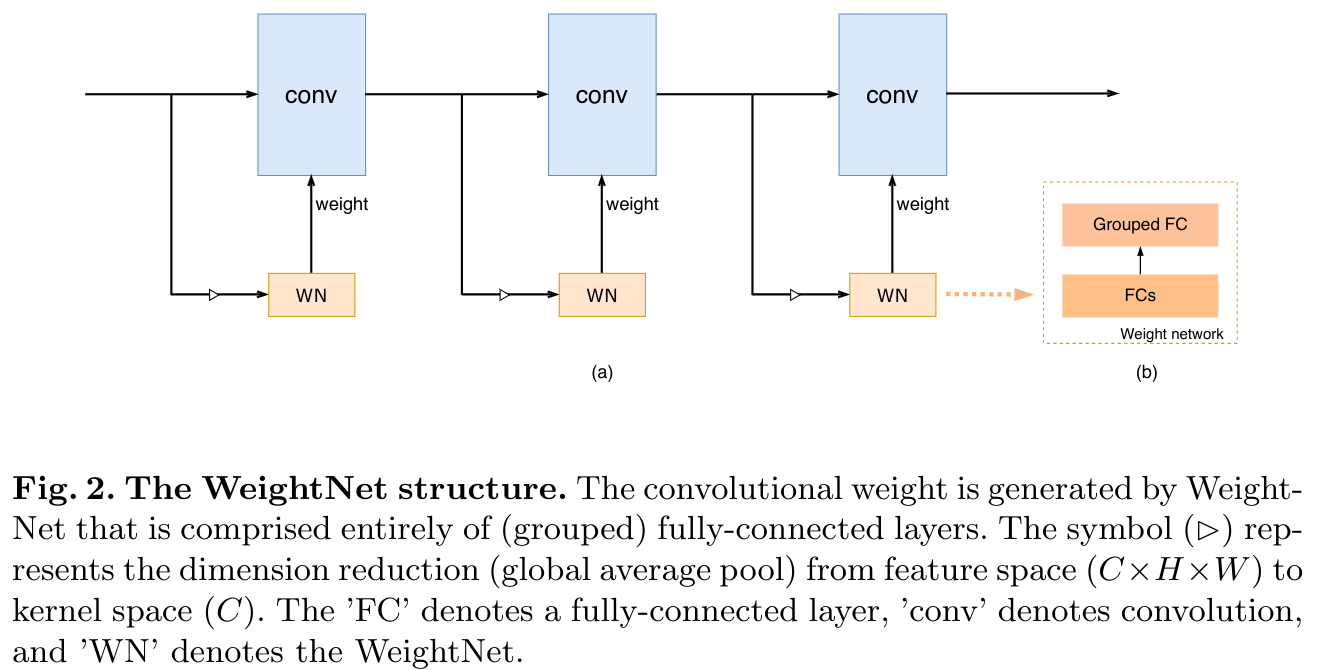
网络结构
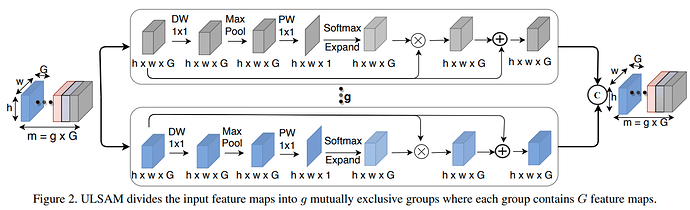
- 将输入
tensor F按照通道分为g组:CHW-->gGHW, ,每一组 被称为一个子空间 - 对每个子空间 进行如下运算:
Depth-wise Conv(kernel_size = 1)MaxPool2d(kernel_size = 3, stride = 1, padding = 1), 这一步可以获得感受野同时减小方差Point-wise Conv(kernel_size = 1), kernels = 1softmaxout = x + x * softmax
- 将所有子空间的结果
concat作为输出
公式表示
源码表示
1 | import torch |
Grad-CAM++ 热力图
ULSAM加入到MobileNet v1和v2之后,模型的focus能力更好

Thoughts
- 虽然
Flops和params减小或者几乎不变,但引入了很多element-wise运算,估计速度会慢 SENet使用sigmoid来处理权重,而ULSAM使用HW维度上softmax处理权重,所以需要使用残差结构
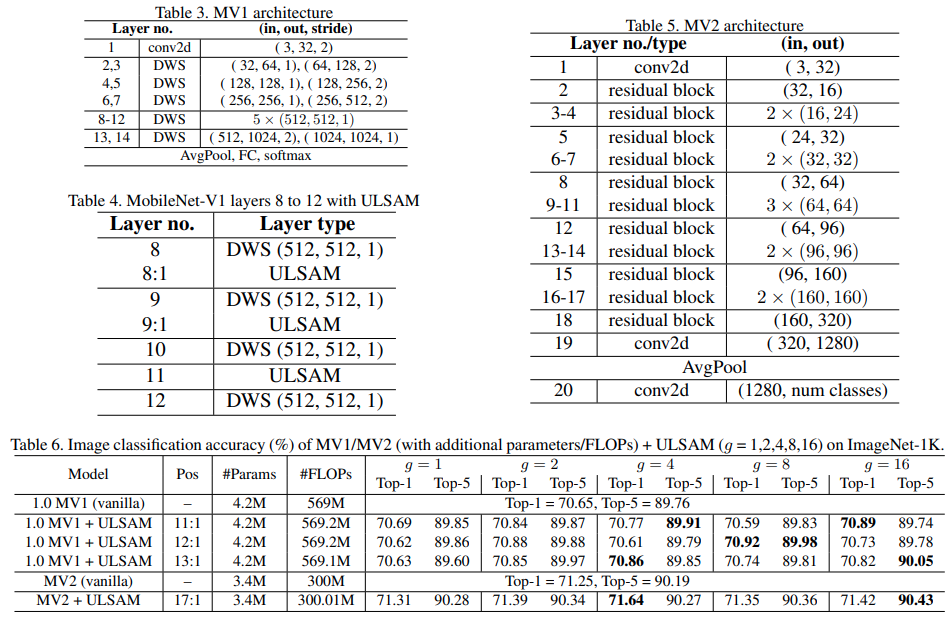
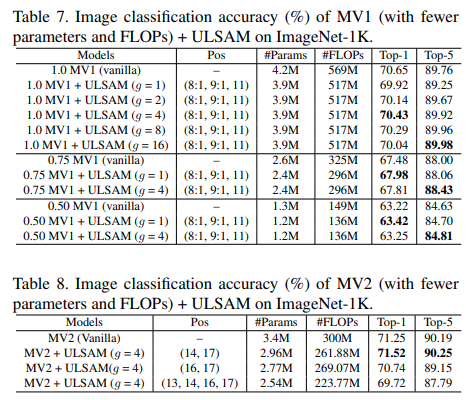
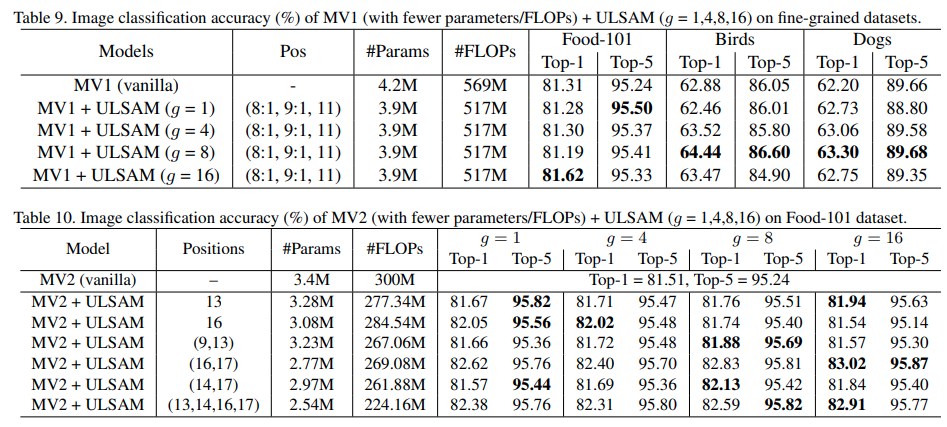
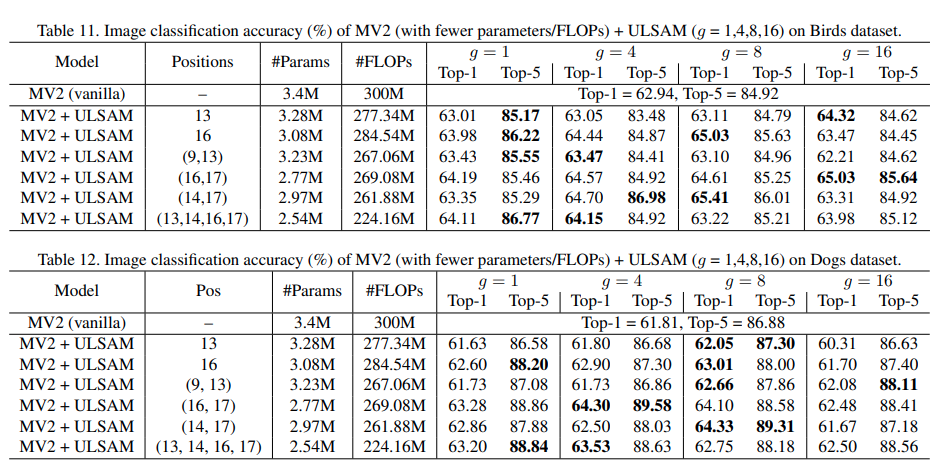
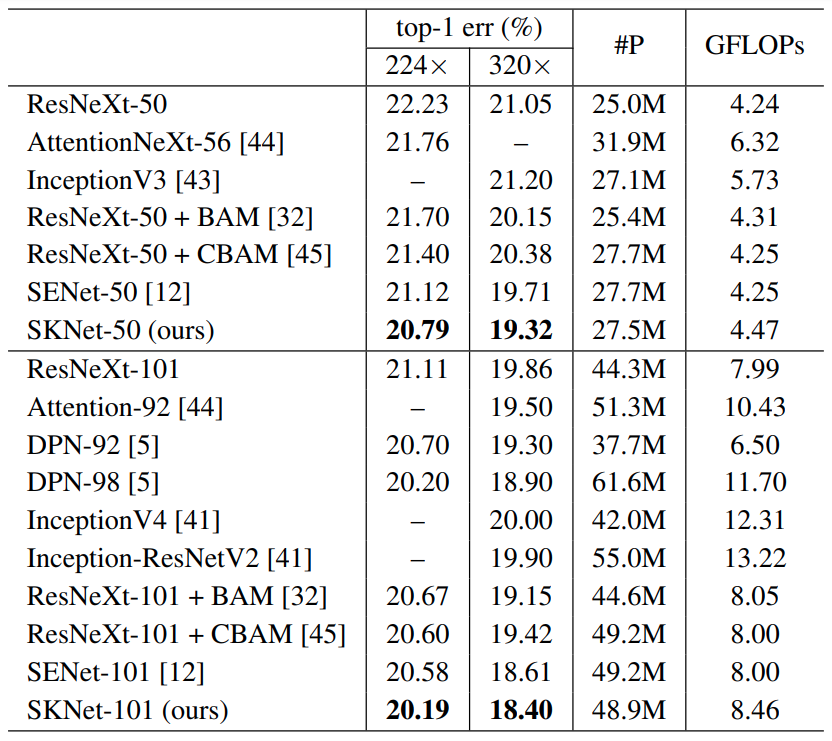
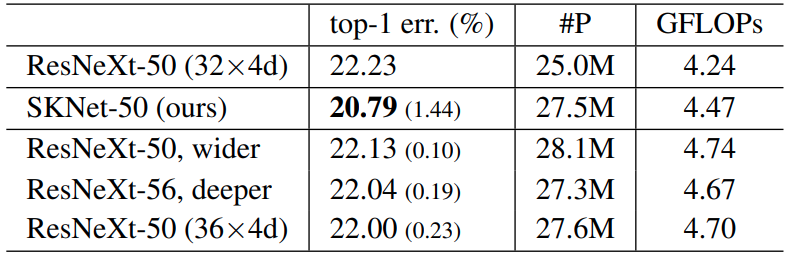
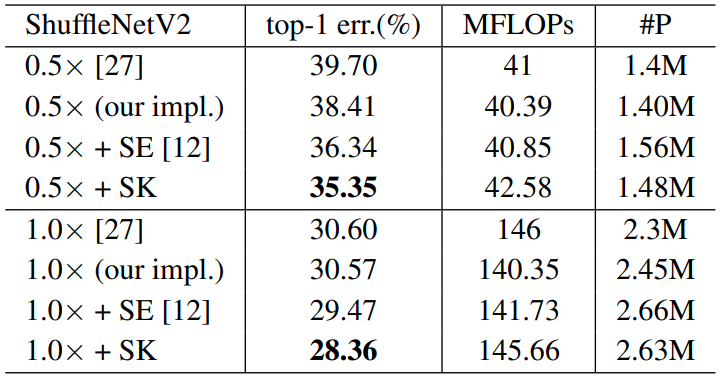
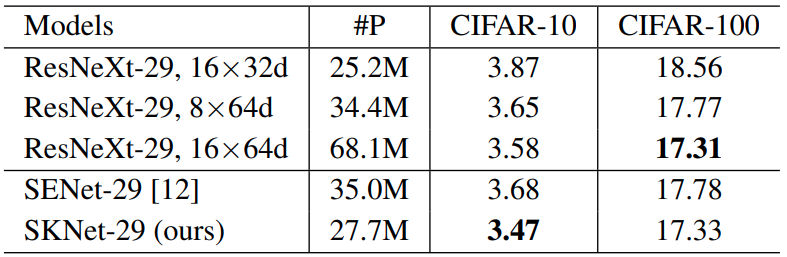
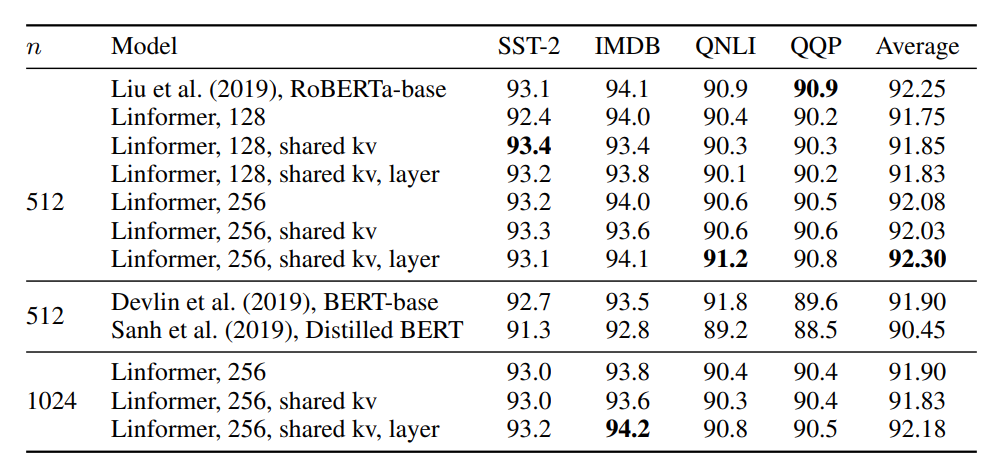
网络表现
- 通过控制变量实验,验证子空间数量
g和替换位置pos对模型表现的影响
对比实验