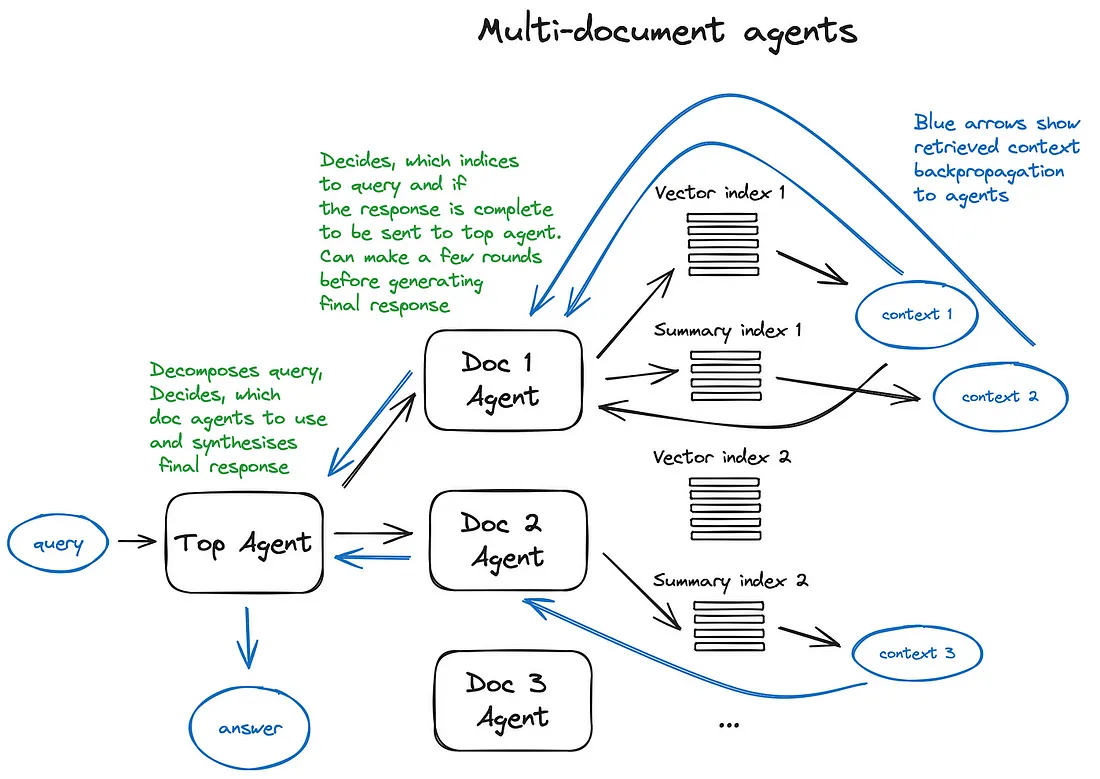
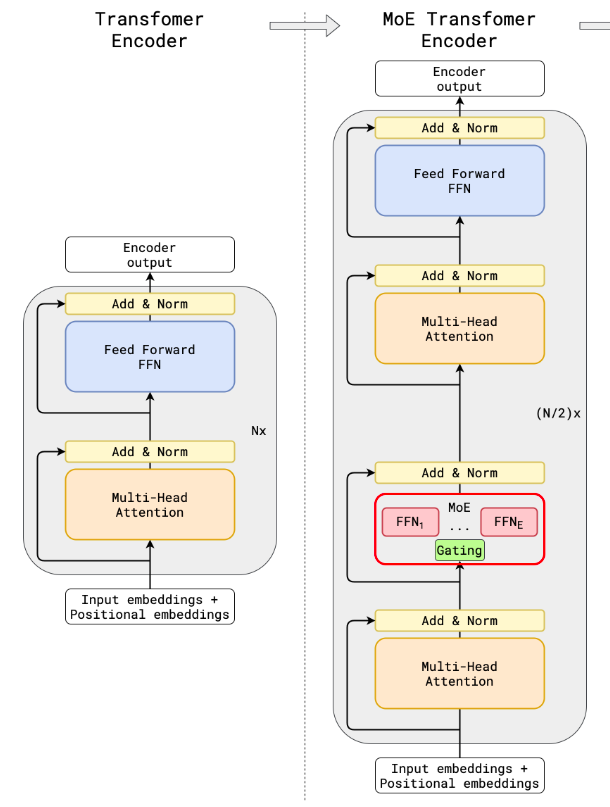
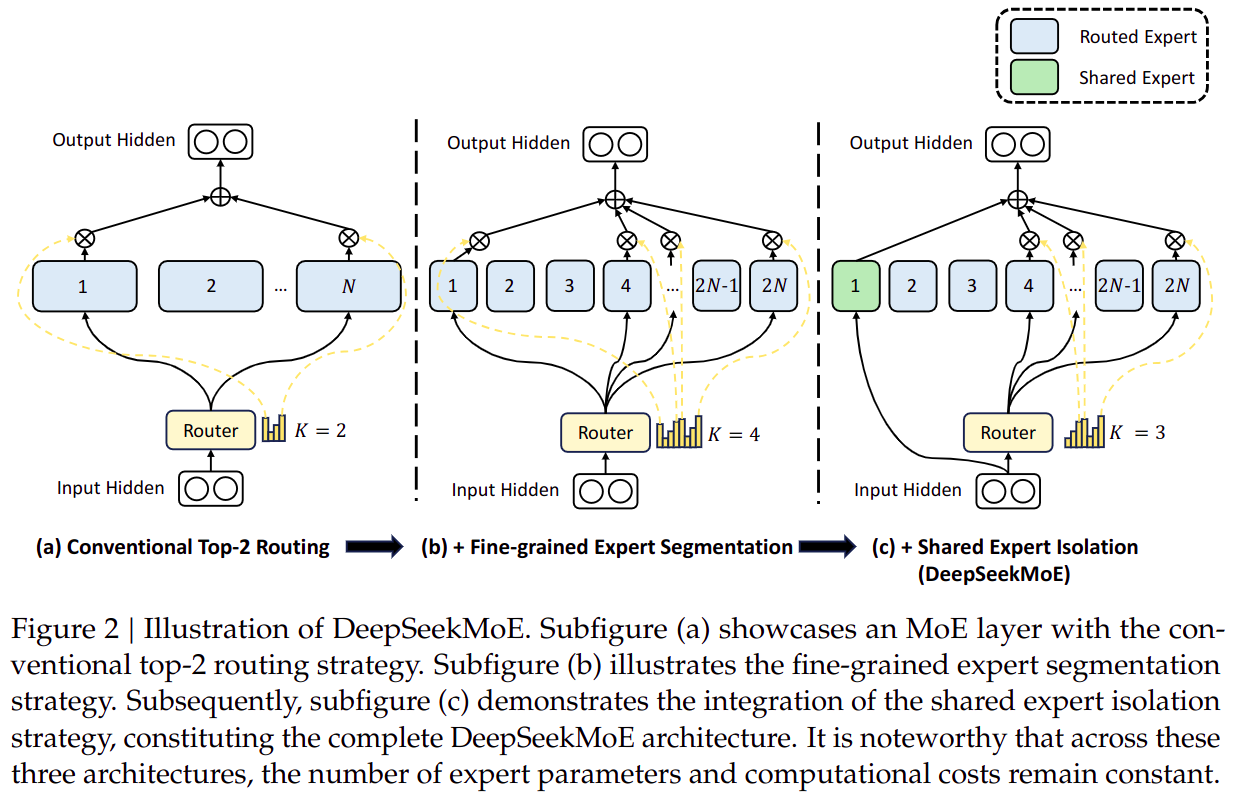
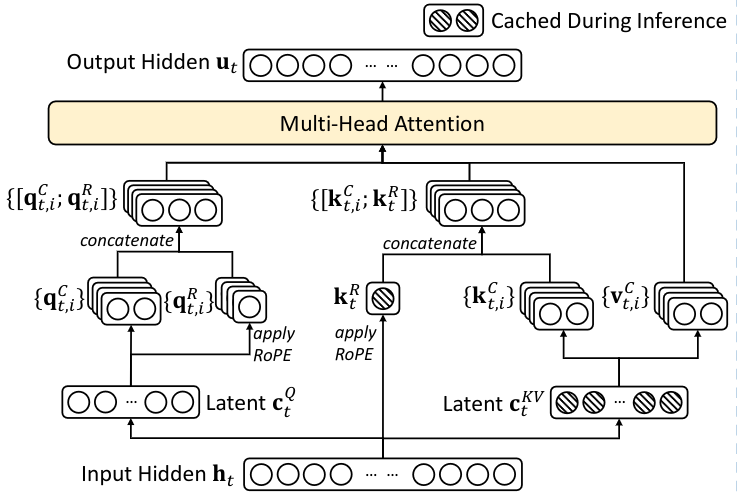
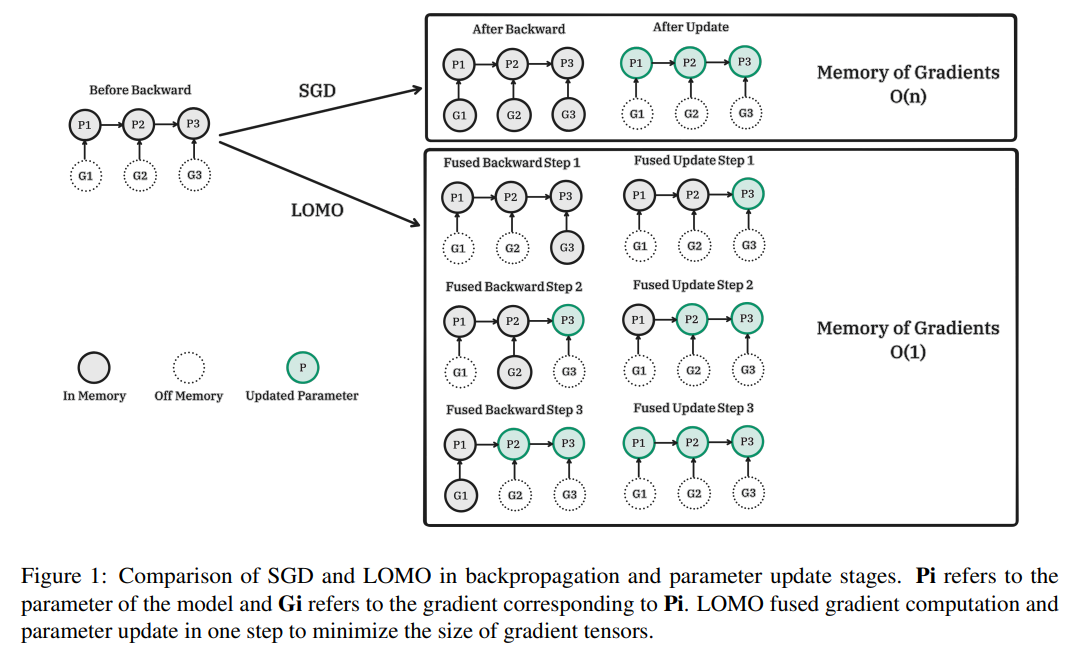
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
| import math
import torch
from torch.optim import Optimizer
import torch.distributed as dist
from transformers.integrations.deepspeed import is_deepspeed_zero3_enabled
class AdaLomo(Optimizer):
"""
一个自定义的优化器类AdaLomo,用于在分布式训练中的梯度更新。
该类实现两个梯度更新函数 :meth:`fuse_update` 和 :meth:`fuse_update_zero3`,分别用于非ZeRO和ZeRO模式下的梯度更新。
:param model: 待优化的模型
:param lr: 学习率,默认值为1e-3
:param eps: 正则化系数。eps[0]防止梯度平方太小,eps[1]用于在根据参数的RMS放缩学习率时防止步长太大
:param clip_threshold: 归一化update矩阵时的阈值
:param decay_rate: 梯度平方移动平均的衰减率
:param clip_grad_norm: 梯度裁剪的范数阈值
.. note::
clip_grad_norm须为正数
:param clip_grad_value: 梯度裁剪的值域阈值
:param weight_decay: 权重衰减系数,默认值为0.0
:param loss_scale: 损失缩放系数,可以用来提高训练精度,但是太大可能会导致nan
"""
def __init__(
self,
model,
lr=1e-3,
loss_scale=2 ** 10,
eps=(1e-30, 1e-3),
clip_threshold=1.0,
decay_rate=-0.8,
clip_grad_norm=None,
clip_grad_value=None,
weight_decay=0.0,
):
self.model = model
self.lr = lr
self.clip_grad_norm = clip_grad_norm
self.clip_grad_value = clip_grad_value
self.weight_decay = weight_decay
self.loss_scale = loss_scale
if self.weight_decay > 0.0:
self.do_weight_decay = True
else:
self.do_weight_decay = False
self.eps = eps
self.step_num = 0
self.decay_rate = decay_rate
self.clip_threshold = clip_threshold
if self.clip_grad_norm is not None and self.clip_grad_norm <= 0:
raise ValueError(
f"clip_grad_norm should be positive, got {self.clip_grad_norm}."
)
self.gather_norm = False
self.grad_norms = []
self.clip_coef = None
self.zero3_enabled = is_deepspeed_zero3_enabled()
if self.zero3_enabled:
self.grad_func = self.fuse_update_zero3()
else:
self.grad_func = self.fuse_update()
self.exp_avg_sq = {}
self.exp_avg_sq_row = {}
self.exp_avg_sq_col = {}
for n, p in self.model.named_parameters():
if self.zero3_enabled:
if len(p.ds_shape) == 1:
self.exp_avg_sq[n] = torch.zeros(
p.ds_shape[0], dtype=torch.float32
).cuda()
else:
self.exp_avg_sq_row[n] = torch.zeros(
p.ds_shape[0], dtype=torch.float32
).cuda()
self.exp_avg_sq_col[n] = torch.zeros(
p.ds_shape[1], dtype=torch.float32
).cuda()
else:
if len(p.data.shape) == 1:
self.exp_avg_sq[n] = torch.zeros(
p.data.shape[0], dtype=torch.float32
).cuda()
else:
self.exp_avg_sq_row[n] = torch.zeros(
p.data.shape[0], dtype=torch.float32
).cuda()
self.exp_avg_sq_col[n] = torch.zeros(
p.data.shape[1], dtype=torch.float32
).cuda()
if p.requires_grad:
p.register_hook(self.grad_func)
defaults = dict(
lr=lr,
eps=eps,
weight_decay=weight_decay,
clip_grad_norm=clip_grad_norm,
clip_grad_value=clip_grad_value,
)
super(AdaLomo, self).__init__(self.model.parameters(), defaults)
@staticmethod
def _approx_sq_grad(exp_avg_sq_row, exp_avg_sq_col):
r_factor = (
(exp_avg_sq_row / exp_avg_sq_row.mean(dim=-1, keepdim=True))
.rsqrt_()
.unsqueeze(-1)
)
c_factor = exp_avg_sq_col.unsqueeze(-2).rsqrt()
return torch.mul(r_factor, c_factor)
@staticmethod
def _rms(tensor):
return tensor.norm(2) / (tensor.numel() ** 0.5)
def fuse_update(self):
"""
在非ZeRO模式下更新模型参数的梯度。
:return: func,一个闭包函数,用于更新模型参数的梯度
"""
def func(x):
"""
闭包函数,用于更新模型参数的梯度。
"""
with torch.no_grad():
for n, p in self.model.named_parameters():
if p.requires_grad and p.grad is not None:
grad_fp32 = p.grad.to(torch.float32)
p.grad = None
if self.loss_scale:
grad_fp32.div_(self.loss_scale)
if self.gather_norm:
self.grad_norms.append(torch.norm(grad_fp32, 2.0))
else:
if (
self.clip_grad_value is not None
and self.clip_grad_value > 0
):
grad_fp32.clamp_(
min=-self.clip_grad_value, max=self.clip_grad_value
)
if (
self.clip_grad_norm is not None
and self.clip_grad_norm > 0
and self.clip_coef is not None
):
grad_fp32.mul_(self.clip_coef)
beta2t = 1.0 - math.pow(self.step_num, self.decay_rate)
update = (grad_fp32 ** 2) + self.eps[0]
if len(p.data.shape) > 1:
self.exp_avg_sq_row[n].mul_(beta2t).add_(
update.mean(dim=-1), alpha=1.0 - beta2t
)
self.exp_avg_sq_col[n].mul_(beta2t).add_(
update.mean(dim=-2), alpha=1.0 - beta2t
)
update = self._approx_sq_grad(
self.exp_avg_sq_row[n], self.exp_avg_sq_col[n]
)
update.mul_(grad_fp32)
else:
self.exp_avg_sq[n].mul_(beta2t).add_(
update, alpha=1.0 - beta2t
)
update = self.exp_avg_sq[n].rsqrt().mul_(grad_fp32)
update.div_(
(self._rms(update) / self.clip_threshold).clamp_(
min=1.0
)
)
p_fp32 = p.data.to(torch.float32)
p_rms = torch.norm(p_fp32, 2.0) / math.sqrt(p.numel())
lr = self.lr
param_scale = max(self.eps[1], p_rms)
lr = lr * param_scale
if self.do_weight_decay:
p_fp32.mul_(1.0 - lr * self.weight_decay)
p_fp32.add_(update, alpha=-lr)
p.data.copy_(p_fp32)
return x
return func
def fuse_update_zero3(self):
"""
在ZeRO模式下更新模型参数的梯度。
:return: func,一个闭包函数,用于更新模型参数的梯度。
"""
def func(x):
with torch.no_grad():
for n, p in self.model.named_parameters():
if p.grad is not None:
torch.distributed.all_reduce(
p.grad, op=torch.distributed.ReduceOp.AVG, async_op=False
)
grad_fp32 = p.grad.to(torch.float32)
p.grad = None
if self.loss_scale:
grad_fp32.div_(self.loss_scale)
if self.gather_norm:
self.grad_norms.append(torch.norm(grad_fp32, 2.0))
else:
partition_size = p.ds_tensor.numel()
start = partition_size * self.dp_rank
end = min(start + partition_size, grad_fp32.numel())
if self.clip_grad_value is not None:
grad_fp32.clamp_(
min=-self.clip_grad_value, max=self.clip_grad_value
)
if (
self.clip_grad_norm is not None
and self.clip_grad_norm > 0
and self.clip_coef is not None
):
grad_fp32.mul_(self.clip_coef)
beta2t = 1.0 - math.pow(self.step_num, self.decay_rate)
update = (grad_fp32 ** 2) + self.eps[0]
if len(p.ds_shape) > 1:
self.exp_avg_sq_row[n].mul_(beta2t).add_(
update.mean(dim=-1), alpha=1.0 - beta2t
)
self.exp_avg_sq_col[n].mul_(beta2t).add_(
update.mean(dim=-2), alpha=1.0 - beta2t
)
update = self._approx_sq_grad(
self.exp_avg_sq_row[n], self.exp_avg_sq_col[n]
)
update.mul_(grad_fp32)
else:
self.exp_avg_sq[n].mul_(beta2t).add_(
update, alpha=1.0 - beta2t
)
update = self.exp_avg_sq[n].rsqrt().mul_(grad_fp32)
update.div_(
(self._rms(update) / self.clip_threshold).clamp_(
min=1.0
)
)
one_dim_update = update.view(-1)
partitioned_update = one_dim_update.narrow(
0, start, end - start
)
param_fp32 = p.ds_tensor.to(torch.float32)
partitioned_p = param_fp32.narrow(0, 0, end - start)
p_rms = torch.norm(partitioned_p, 2.0) ** 2
dist.all_reduce(p_rms, op=torch.distributed.ReduceOp.SUM)
p_rms = (p_rms / p.ds_numel).sqrt()
lr = self.lr
param_scale = max(self.eps[1], p_rms)
lr = lr * param_scale
if self.do_weight_decay:
partitioned_p.mul_(1.0 - lr * self.weight_decay)
partitioned_p.add_(partitioned_update, alpha=-lr)
p.ds_tensor[: end - start] = partitioned_p
return x
return func
def fused_backward(self, loss, lr):
"""
执行一步反向传播并更新模型的梯度。
:param loss: 模型的loss值
:param lr: 学习率
"""
self.lr = lr
if self.loss_scale:
loss = loss * self.loss_scale
self.step_num += 1
loss.backward()
self.grad_func(0)
def grad_norm(self, loss):
"""
计算梯度的范数。
:param loss: 模型的loss值
"""
self.gather_norm = True
self.grad_norms = []
if self.loss_scale:
loss = loss * self.loss_scale
loss.backward(retain_graph=True)
self.grad_func(0)
with torch.no_grad():
self.grad_norms = torch.stack(self.grad_norms)
total_norm = torch.norm(self.grad_norms, 2.0)
self.clip_coef = float(self.clip_grad_norm) / (total_norm + 1e-6)
self.clip_coef = torch.clamp(self.clip_coef, max=1.0)
self.gather_norm = False
|