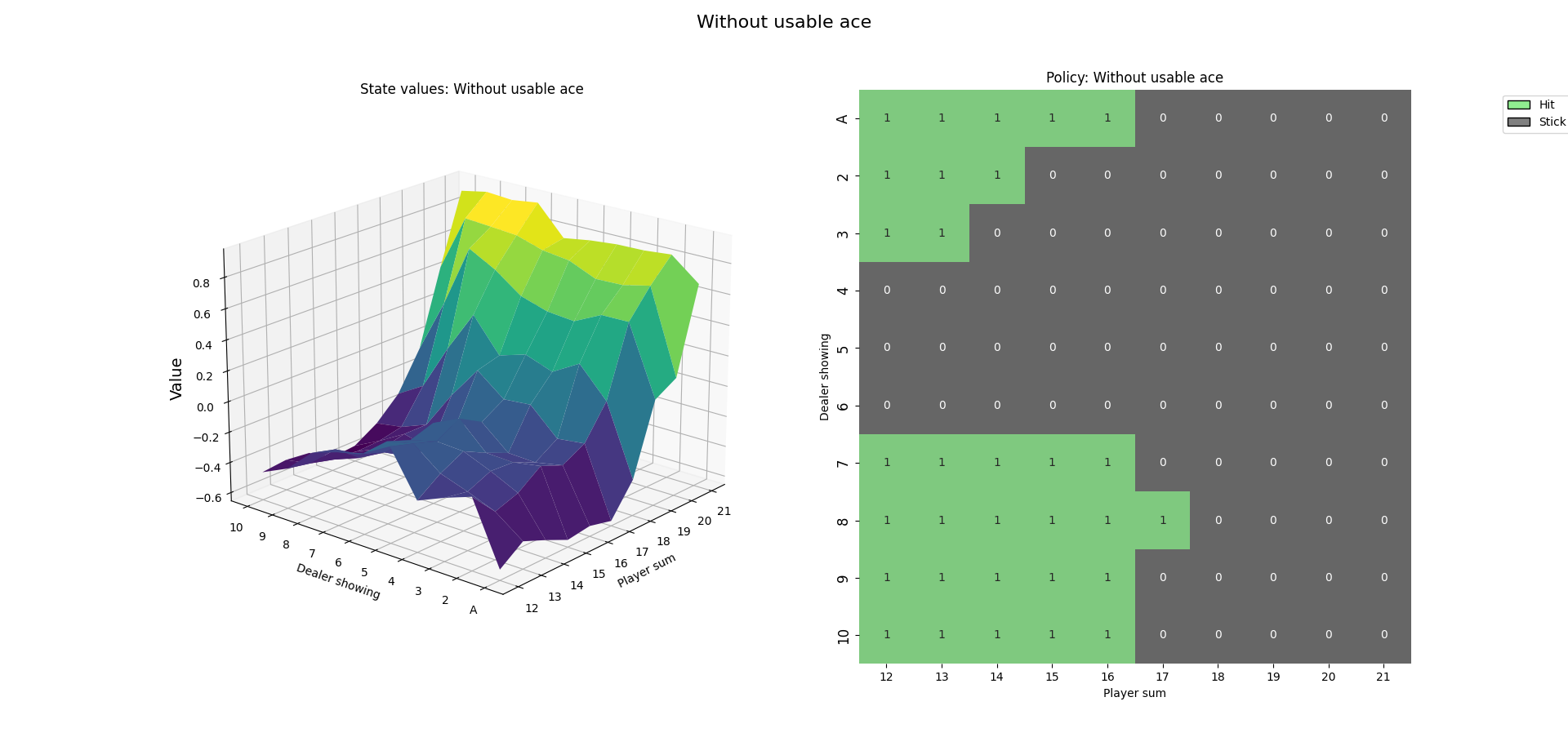
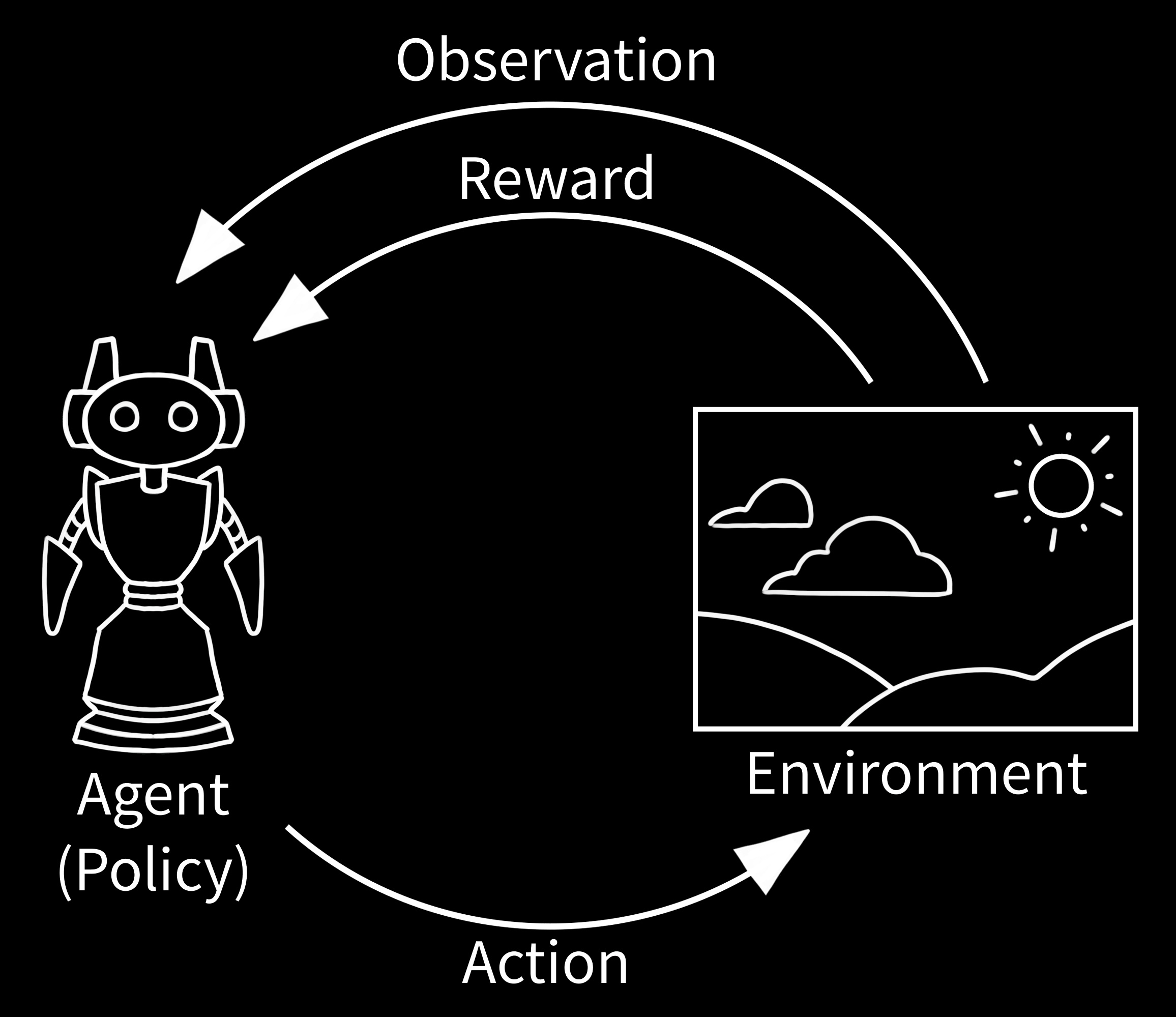
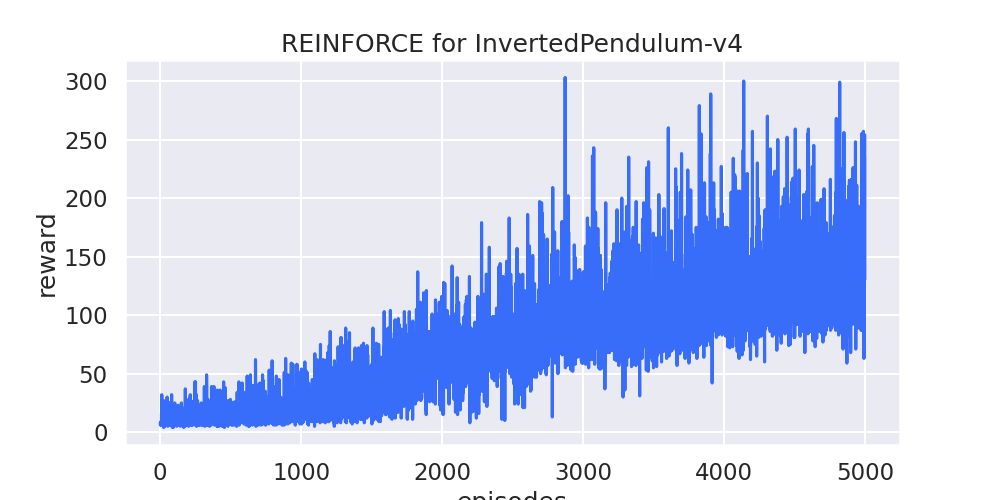
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
| class C51(nn.Module):
def __init__(self, input_dim, output_dim, n_atoms, V_min, V_max):
super(C51, self).__init__()
self.n_atoms = n_atoms
self.output_dim = output_dim
self.V_min = V_min
self.V_max = V_max
self.delta_z = (V_max - V_min) / (n_atoms - 1)
self.input_dim = input_dim
self.fc1 = nn.Linear(input_dim, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, output_dim * n_atoms)
def forward(self, x):
x = torch.nn.functional.one_hot(
x.to(torch.int64), num_classes=self.input_dim
).float()
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
x = x.view(-1, self.output_dim, self.n_atoms)
return torch.softmax(x, dim=-1)
class C51Agent:
def __init__(
self,
env,
learning_rate: float,
initial_epsilon: float,
epsilon_decay: float,
final_epsilon: float,
discount_factor: float = 0.95,
batch_size: int = 64,
memory_size: int = 10000,
n_atoms: int = 51,
V_min: float = -10.0,
V_max: float = 10.0,
):
self.env = env
self.lr = learning_rate
self.discount_factor = discount_factor
self.epsilon = initial_epsilon
self.epsilon_decay = epsilon_decay
self.final_epsilon = final_epsilon
self.batch_size = batch_size
self.n_atoms = n_atoms
self.V_min = V_min
self.V_max = V_max
self.delta_z = (V_max - V_min) / (n_atoms - 1)
self.z = torch.linspace(V_min, V_max, n_atoms).to(torch.float32)
self.memory = deque(maxlen=memory_size)
self.training_error = []
self.input_dim = env.observation_space.n
self.output_dim = env.action_space.n
self.q_network = C51(
input_dim=self.input_dim,
output_dim=self.output_dim,
n_atoms=n_atoms,
V_min=V_min,
V_max=V_max,
)
self.target_network = C51(
input_dim=self.input_dim,
output_dim=self.output_dim,
n_atoms=n_atoms,
V_min=V_min,
V_max=V_max,
)
self.target_network.load_state_dict(self.q_network.state_dict())
self.optimizer = optim.Adam(self.q_network.parameters(), lr=self.lr)
def get_action(self, obs: int) -> int:
if np.random.random() < self.epsilon:
return self.env.action_space.sample()
else:
obs_tensor = torch.tensor([obs], dtype=torch.int64)
dist = self.q_network(obs_tensor)
q_values = torch.sum(dist * self.z, dim=2)
action = torch.argmax(q_values, dim=1).item()
return action
def update(self):
if len(self.memory) < self.batch_size:
return
batch = random.sample(self.memory, self.batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
states = torch.tensor(states, dtype=torch.int64)
actions = torch.tensor(actions, dtype=torch.long)
rewards = torch.tensor(rewards, dtype=torch.float32)
next_states = torch.tensor(next_states, dtype=torch.int64)
dones = torch.tensor(dones, dtype=torch.float32)
batch_size = states.size(0)
dist = self.q_network(states)
dist = dist[range(batch_size), actions]
with torch.no_grad():
next_dist = self.target_network(next_states)
next_q_values = torch.sum(next_dist * self.z, dim=2)
next_actions = torch.argmax(next_q_values, dim=1)
next_dist = next_dist[range(batch_size), next_actions]
Tz = rewards.unsqueeze(1) + (
1 - dones.unsqueeze(1)
) * self.discount_factor * self.z.unsqueeze(0)
Tz = Tz.clamp(self.V_min, self.V_max)
b = (Tz - self.V_min) / self.delta_z
l = b.floor().long()
u = b.ceil().long()
l[(u > 0) * (l == u)] -= 1
u[(l < (self.n_atoms - 1)) * (l == u)] += 1
m = torch.zeros(batch_size, self.n_atoms)
offset = (
torch.linspace(0, ((batch_size - 1) * self.n_atoms), batch_size)
.unsqueeze(1)
.expand(batch_size, self.n_atoms)
.long()
)
m.view(-1).index_add_(
0, (l + offset).view(-1), (next_dist * (u.float() - b)).view(-1)
)
m.view(-1).index_add_(
0, (u + offset).view(-1), (next_dist * (b - l.float())).view(-1)
)
dist = dist + 1e-8
loss = -torch.sum(m * torch.log(dist), dim=1).mean()
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.training_error.append(loss.item())
def decay_epsilon(self):
self.epsilon = max(self.final_epsilon, self.epsilon - self.epsilon_decay)
def store_experience(self, obs, action, reward, next_obs, done):
self.memory.append((obs, action, reward, next_obs, done))
def update_target_network(self):
self.target_network.load_state_dict(self.q_network.state_dict())
|