defget_result(self, player): """ 核心方法:返回特定 player 在当前终局下的得分。 赢=1.0,输=0.0,平局=0.5 """ winner = self.get_winner() if winner isNone: return0.5# 平局 if winner == player: return1.0# 该玩家获胜 else: return0.0# 该玩家落败
def__str__(self): symbols = {1: 'X', -1: 'O', 0: '.'} res = "" for i inrange(3): res += " ".join([symbols[self.board[i*3 + j]] for j inrange(3)]) + "\n" return res
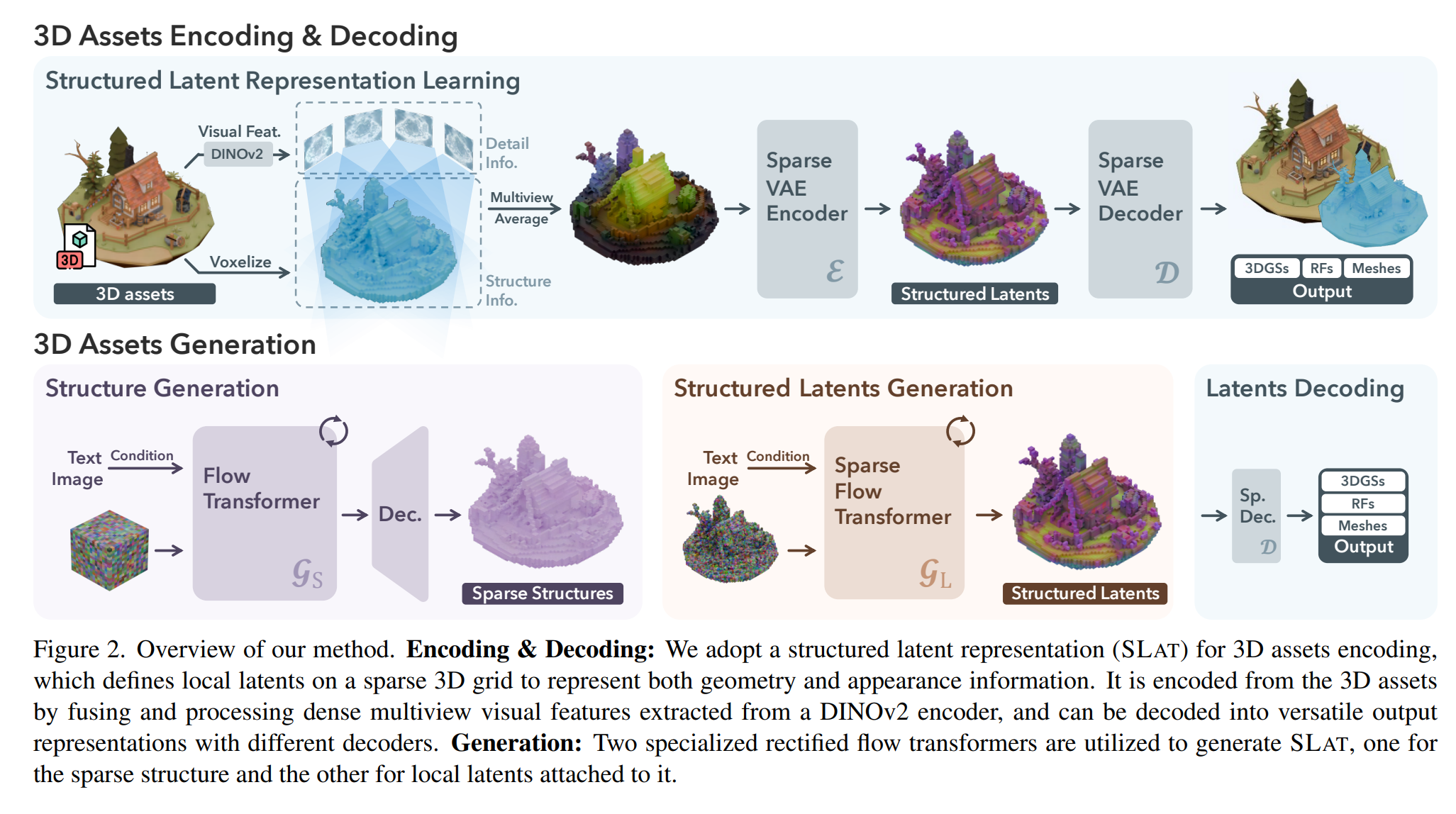
关键就是两个 DiT 模型,两个模型的输出结果合并就是 SLAT 表征,两个 DiT 都是使用流匹配范式训练的
第一个 DiT 模型从图像/文本特征中得到 3D 物体的表明占据体素坐标,这个模型被称为 SparseStructureFlowModel
第二个 DiT 模型从图像/文本特征以及体素占据坐标得到每个激活体素的特征向量,这个模型被称为 ElasticSLatFlowModel
模型在 3D 数据集上通过自监督方式训练得到,可从图片或文本得到不同的 3D 输出格式(3D Gaussian、Radiance Field、mesh 等)
Algorithm
1. 推理过程
以图片 -> 3D 为例:
flowchart TD
A[输入图片] --> B[预处理 518x518]
B --> C[DINOv2编码 Bx1369x1024]
C --> D[Stage 1: Sparse Structure Flow]
D --> E[噪声 Bx8x16x16x16]
E --> F[DiT Transformer 24层]
C --> F
F --> G[Sparse Structure Latent Bx8x16x16x16]
G --> H[Decoder]
H --> I[稀疏坐标 Nx4]
I --> J[Stage 2: SLAT Flow]
J --> K[稀疏噪声 SparseTensor Nx8]
K --> L[稀疏DiT Transformer 24层]
C --> L
L --> M[SLAT表征 SparseTensor Nx8 分辨率64^3]
M --> N[Gaussian解码器]
M --> O[Radiance Field解码器]
M --> P[Mesh解码器]
N --> Q[3D Gaussians]
O --> S[Strivect辐射场]
P --> T[三角网格]
0: 图像预处理
功能:去除背景、裁剪、归一化
输入:原始PIL图像(任意尺寸)
输出:518×518 RGB图像,带alpha通道
处理步骤:
使用 rembg (U2-Net) 去除背景
根据前景内容裁剪并居中
调整大小到 518×518
1: 图像条件编码
模型:DINOv2 ViT-L/14-reg
输入:(B, 3, 518, 518) - 预处理后的图像
输出:(B, N, 1024) - 图像特征tokens,其中 N = (518/14)² = 1369(37 x 37)
处理:通过 DINOv2 提取 patch tokens
2: 稀疏结构生成 (Stage 1)
模型:SparseStructureFlowModel(DiT)
输入:
Noise: (B, 8, 16, 16, 16) - 3D噪声张量
Image condition: (B, 1369, 1024) - DINOv2特征
Timestep: (B,) - Flow matching时间步
处理流程:
将3D噪声 patchify(如果patch_size>1)
添加3D位置编码
通过24层 DiT transformer blocks,进行图像条件的交叉注意力
Unpatchify 回3D体积
输出:(B, 8, 16, 16, 16) - 稀疏结构latent
解码到坐标:
通过 SparseStructureDecoder 解码为occupancy grid
Resolution: 16³
提取 occupancy > 0 的体素坐标
解码器输出:(B, 1, 16, 16, 16) - occupancy概率
提取坐标:(N_occupied, 4) - [batch_idx, x, y, z],其中 N_occupied 是非空体素数量
3: SLAT 生成 (Stage 2) - 核心表征
模型:ElasticSLatFlowModel
输入:
Sparse noise: SparseTensor
coords: (N_voxels, 4) - 从Stage 1得到的坐标
feats: (N_voxels, 8) - 随机噪声特征
Image condition: (B, 1369, 1024) - DINOv2特征
Timestep: (B,) - Flow matching时间步
处理流程:
通过sparse linear层和下采样ResBlocks处理输入 (2倍下采样)
添加稀疏3D位置编码
通过24层稀疏DiT transformer blocks,带图像交叉注意力
通过上采样ResBlocks和skip connections恢复分辨率
输出层产生8通道特征
输出 - SLAT表征:SparseTensor
coords: (N_voxels, 4) - [batch_idx, x, y, z],坐标在64³空间