URL
https://arxiv.org/pdf/1901.05555.pdf
TL;DR
- 本文提出一种在 不平衡数据分类 场景使用的 Loss ——
Class-Balanced Loss
- 提出一个理论模型,对每类的 有效样本数量 进行估计,从而对每类设计损失权重
- 理论可概括为:对某一类的所有样本(样本容量为 n)进行采样,每一次采样,有 p 的概率和之前采样过的样本
重复,有 1-p 的概率不重复,n 越大,冲突可能越大,所以 p 越大
- 该理论模型简化后可用数学归纳法证明,Class-Balanced Loss 最终化简为包含一个超参 β 的权重系数
Algorithm
常用的不平衡数据处理方法
- 重采样
- 重赋权
- 以类间样本容量比例直接作为权重
- 缺点:虽然最为常用,但不科学,因为样本容量的比值不能代替样本中有效样本的比值
有效样本
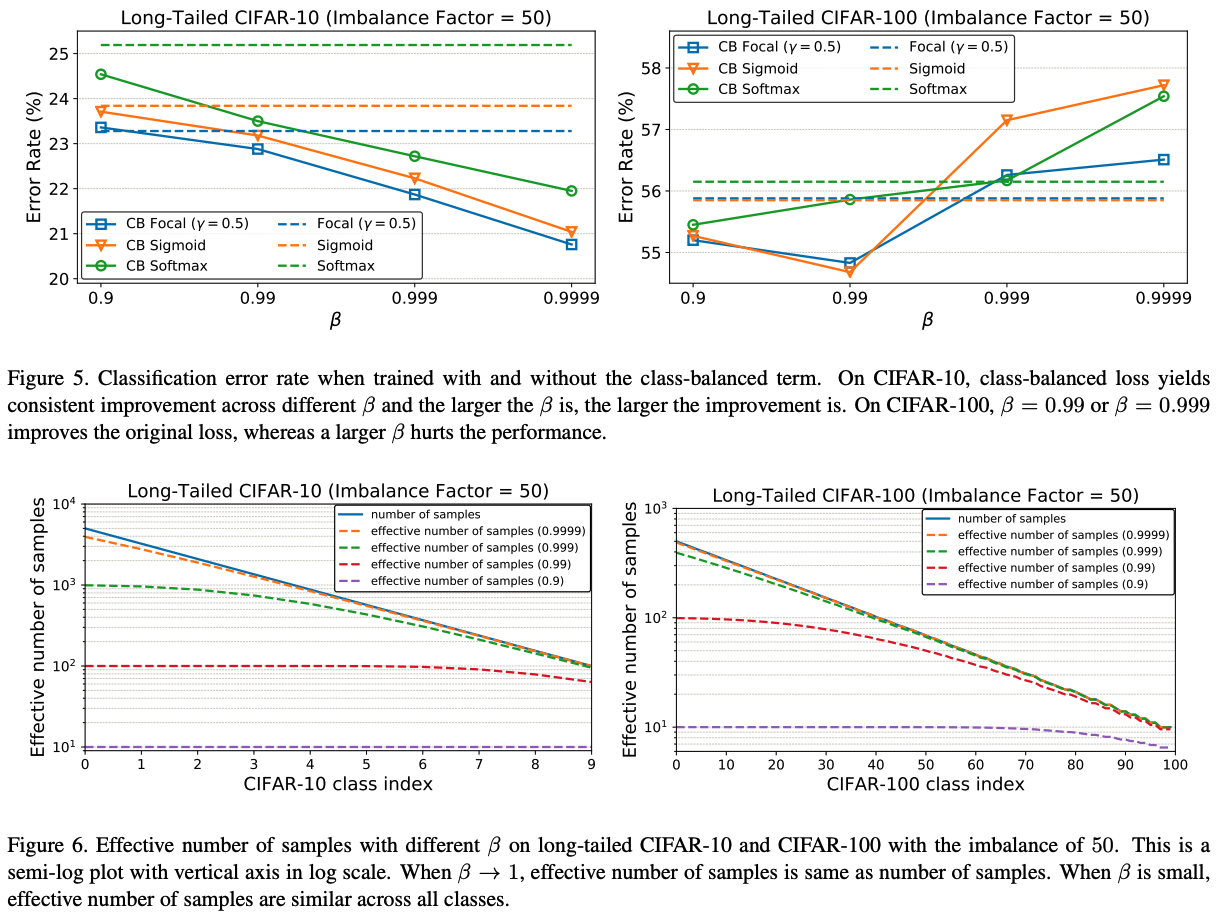
- 本文提出一种类中有效样本的计算方式,类中样本容量用 n∈Z>0 表示,有效样本量用 N∈Z>0 表示,有效样本的期望用 En∈Z>0 表示
En=1−β1−βn, β=NN−1

- 实际使用时,β 为一个超参,取值范围:{0.9, 0.99, 0.999, 0.9999}
实际使用时的损失函数
-
理论模型只提供一个权重,实际使用时还需要结合其他的分类损失函数,例如 [Softmax Loss(交叉熵), Sigmoid Loss, Focal Loss]
CB(p,y)=Eny1L(p,y)=1−βny1−βL(p,y)
其中,p∈[0,1] 表示输入样本 x 后模型输出的各类的概率分布,y 表示样本 x 的 label,β 是一个超参数,L(p,y) 是分类常用损失函数
-
class-balanced softmax cross-entropy loss
CBsoftmax(z,y)=−1−βny1−βlog(∑j=1Cexp(zj)exp(zy))
-
class-balanced sigmoid cross-entropy loss
CBsigmoid(z,y)=−1−βny1−β∑i=1Clog(1+exp(−zit)1)
-
class-balanced focal loss
CBfocal(z,y)=−1−βny1−β∑i=1C(1−pit)γlog(pit)
γ∈{0.5,1,2}
Thought
- 理论被不停简化,条件过于理想化,最后变成一个很简单的公式
- 和其他损失函数结合后,准确率比较随机
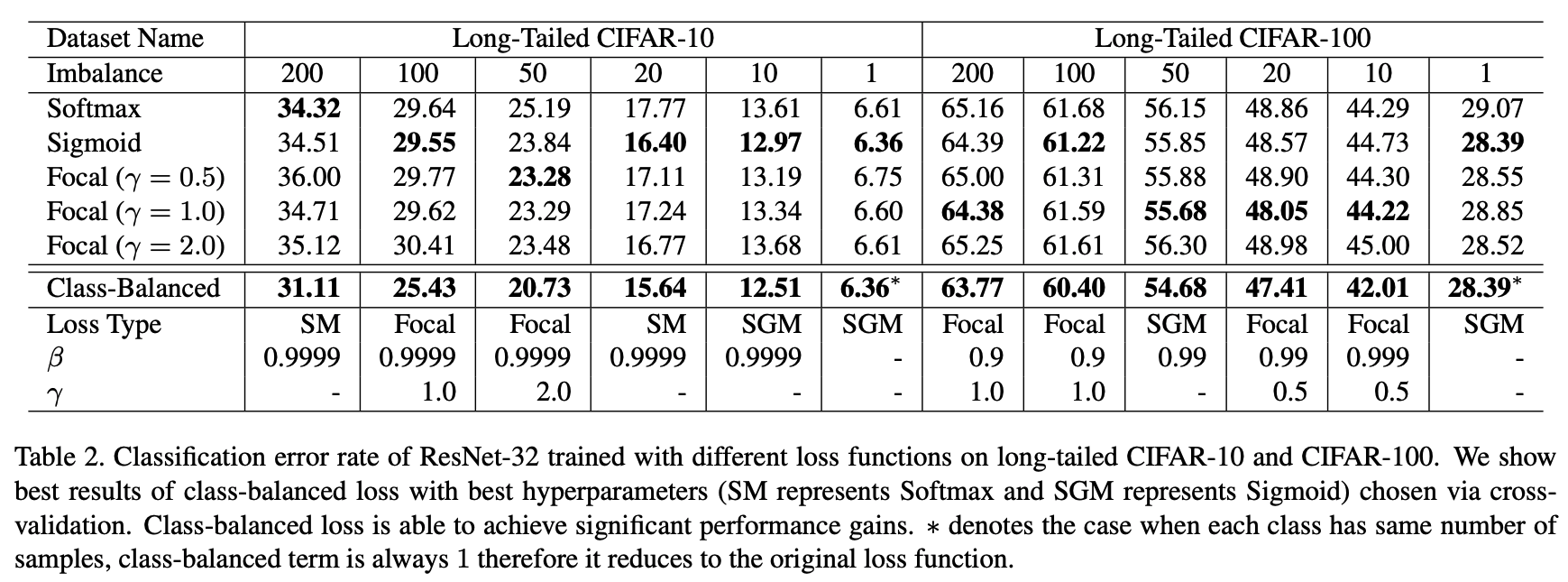
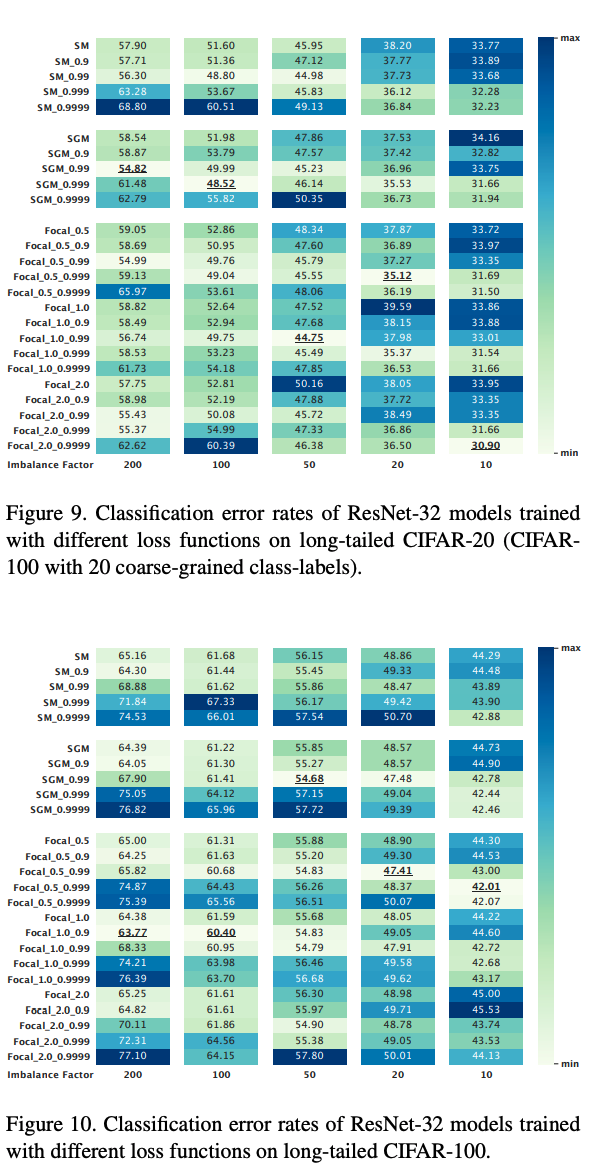
效果
- 其中 Imbalanced factor=Sample size for least classSample size for largest class