URL
- code: https://gymnasium.farama.org/tutorials/training_agents/blackjack_tutorial/
- doc: https://gymnasium.farama.org/environments/toy_text/blackjack/
TL;DR
- 本文通过一个简单的例子介绍了如何用
Q Learning算法训练一个Agent玩Blackjack游戏,环境是OpenAI Gym提供的Blackjack-v0 Q Learning算法是一种用于有限离散状态和动作环境下的强化学习算法,通过基于贝尔曼方程的更新策略,不断更新Q Table来学习最优策略,最终实现Agent的自动决策
Algorithm

Q Learning算法
1. 环境介绍
Blackjack游戏规则
graph TD
A[开始] --> B[给玩家发两张牌,给庄家发两张牌,一张明牌,一张暗牌]
B --> H{玩家是否有21点?}
H -->|是| I[玩家有自然牌,检查庄家]
H -->|否| N{玩家选择是否继续要牌?}
I --> K{庄家是否也有自然牌?}
K -->|是| L[平局]
K -->|否| M[玩家胜利]
N -->|要牌| O[发一张牌给玩家]
N -->|停牌| P[玩家停牌,轮到庄家]
O --> Q{玩家是否爆掉(超过21点)?}
Q -->|是| R[玩家爆掉,庄家胜利]
Q -->|否| N
P --> S{庄家是否点数≥17?}
S -->|是| T[庄家停牌]
S -->|否| U[庄家要牌]
U --> V{庄家是否爆掉?}
V -->|是| M[玩家胜利]
V -->|否| S
T --> X{比较玩家和庄家的点数}
X -->|玩家点数更大| M[玩家胜利]
X -->|庄家点数更大| Z[庄家胜利]
X -->|点数相同| L[平局]
R --> AA[游戏结束]
Z --> AA
L --> AA
M --> AA
Blackjack环境定义:Observation space:Tuple(Discrete(32), Discrete(11), Discrete(2)),用一个三元组表示当前状态,分别是:- 玩家的点数
- 庄家的明牌点数
- 玩家是否有
Ace
Action space:Discrete(2)0表示stick(停牌)1表示hit(要牌)
Reward:+1表示玩家胜利,-1表示庄家胜利,0表示平局Starting state:- 玩家牌之和为
4 - 21之间 - 庄家明牌为
1 - 10之间 - 玩家是否有
Ace为0或1
- 玩家牌之和为
Episode End:- 玩家停牌
- 玩家爆牌
2. Q Learning 算法
| 特性 | V 函数 (状态价值函数) | Q 函数 (状态-动作价值函数) |
|---|---|---|
| 定义 | 评估状态 s 的价值,即在状态 s 开始,按照策略 π 执行的期望累积奖励 |
评估状态 s 和动作 a 的价值,即在状态 s 选择动作 a,然后按照策略 π 执行的期望累积奖励 |
| 输入 | 状态 s |
状态 s 和动作 a |
| 输出 | 状态的价值,即期望的回报 | 状态-动作对的价值,即从状态 s 执行动作 a 后的期望回报 |
| 更新方式 | 通过 来更新,通常用贝尔曼方程 | 直接通过贝尔曼方程更新,通常用于 Q-learning 或 DQN |
| 公式 | ||
| 主要用途 | 用于评估某一状态的好坏,特别适合评估策略 | 用于评估某一状态下选择特定动作的好坏,通常用于 Q-learning 等算法 |
Q Learning算法是一种Off-Policy的强化学习算法,通过不断更新Q Table来学习最优策略Q Table是一个State-Action表,用于存储每个状态下每个动作的Q Value,因此Q Table的大小是Observation space length*Action space lengthQ Value的更新公式:
- 是当前状态
s下采取动作a的Q Value - 是学习率
- 是当前状态下采取动作
a后的奖励 - 是折扣因子,用于平衡当前奖励和未来奖励,越大表示越重视未来奖励,越小表示越重视当前奖励
- 是下一个状态
s'下所有动作中最大的Q Value
3. 使用 Q Learning 算法训练 Agent 玩 Blackjack
实现代码如下:
1 | from collections import defaultdict |
- 代码中定义了一个
BlackjackAgent类,用于实现Q Learning算法 - 初始化:
- 初始化
Q Table为一个空的字典,Q Value为0 - 学习率为
0.01 - 折扣因子为
0.95 - 初始
epsilon为1.0,随着训练逐渐减小为0.1
- 初始化
get_action方法用于根据当前状态选择动作,以epsilon的概率选择随机动作,以1 - epsilon的概率选择最优动作update方法用于更新Q Value,根据Q Learning公式更新Q Value
4. 训练结果
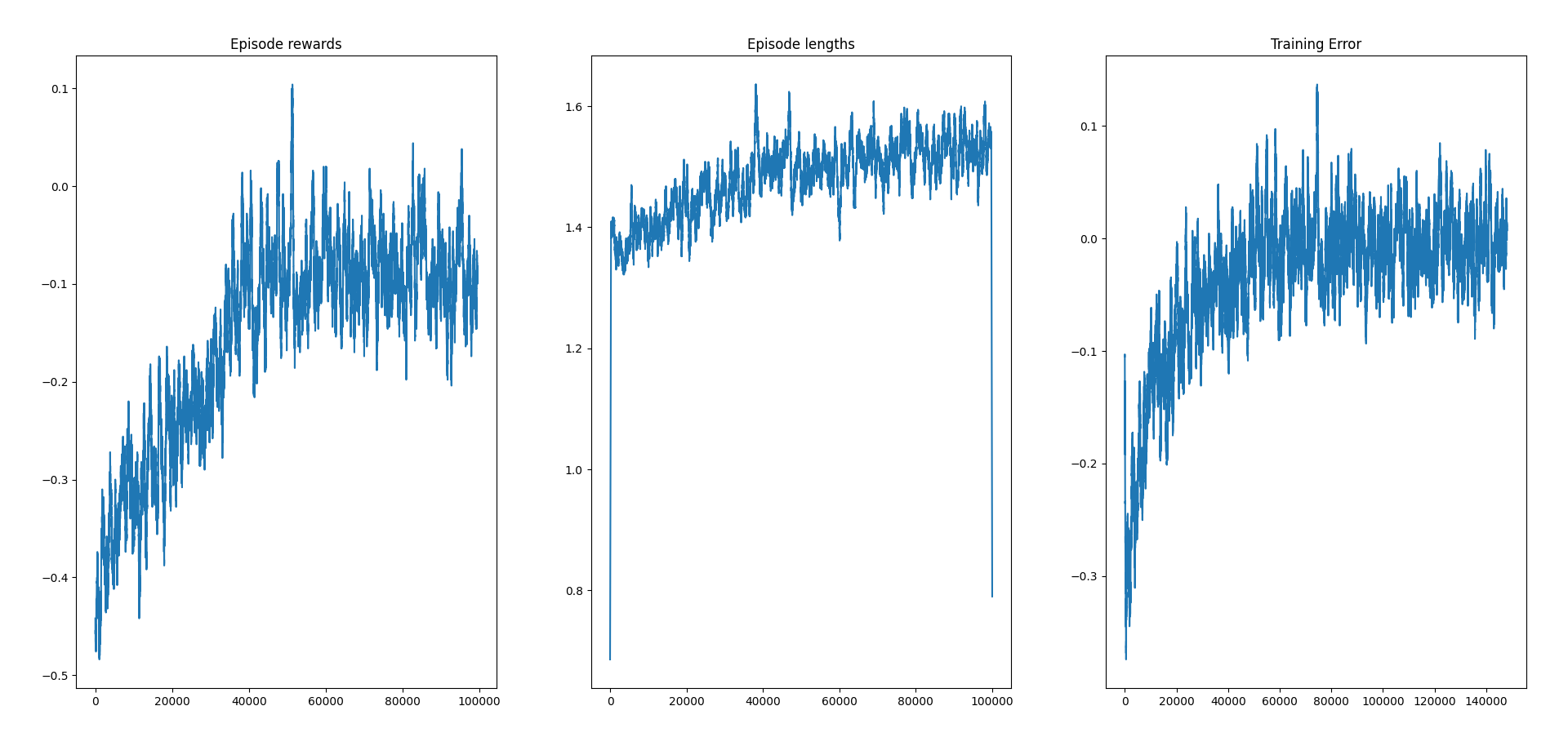
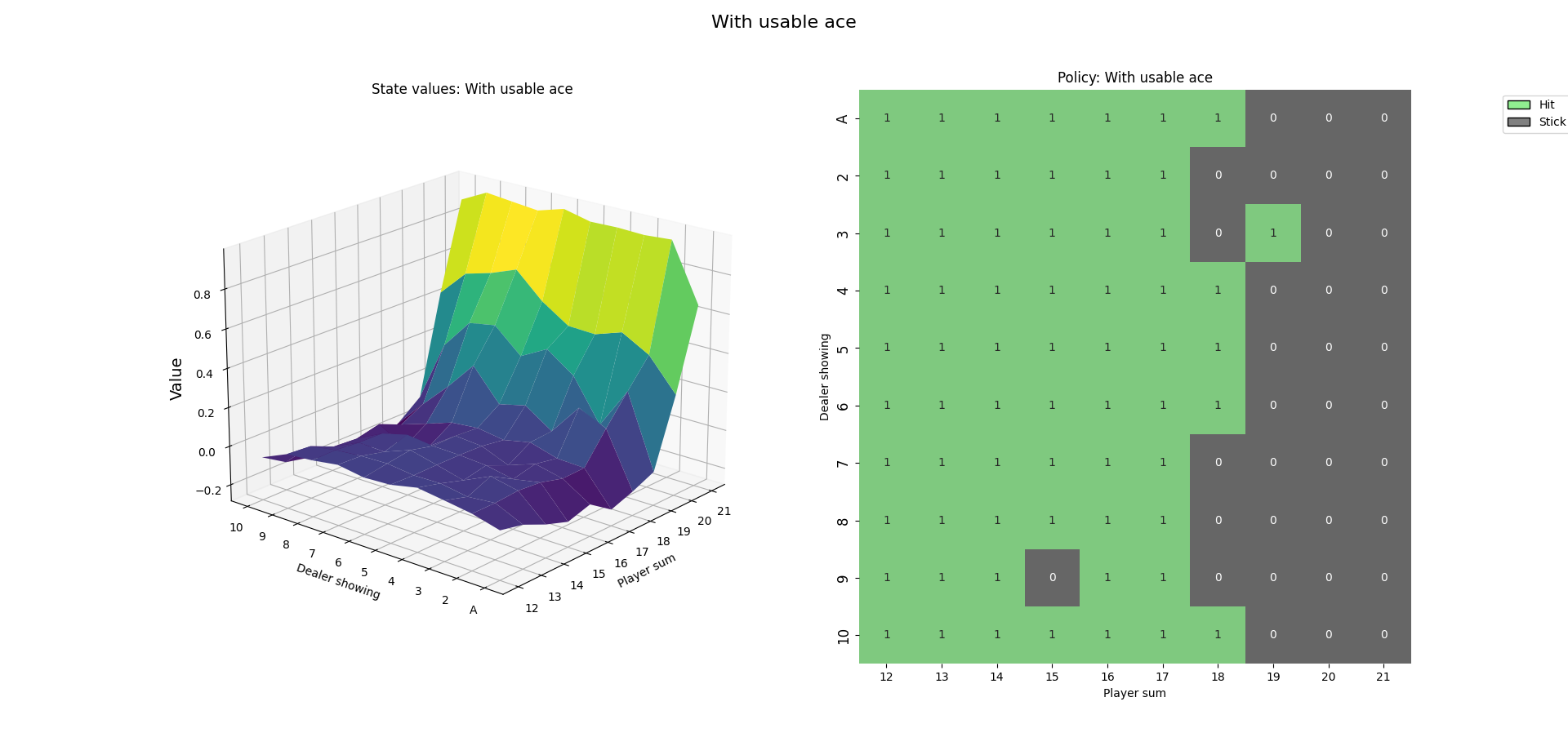
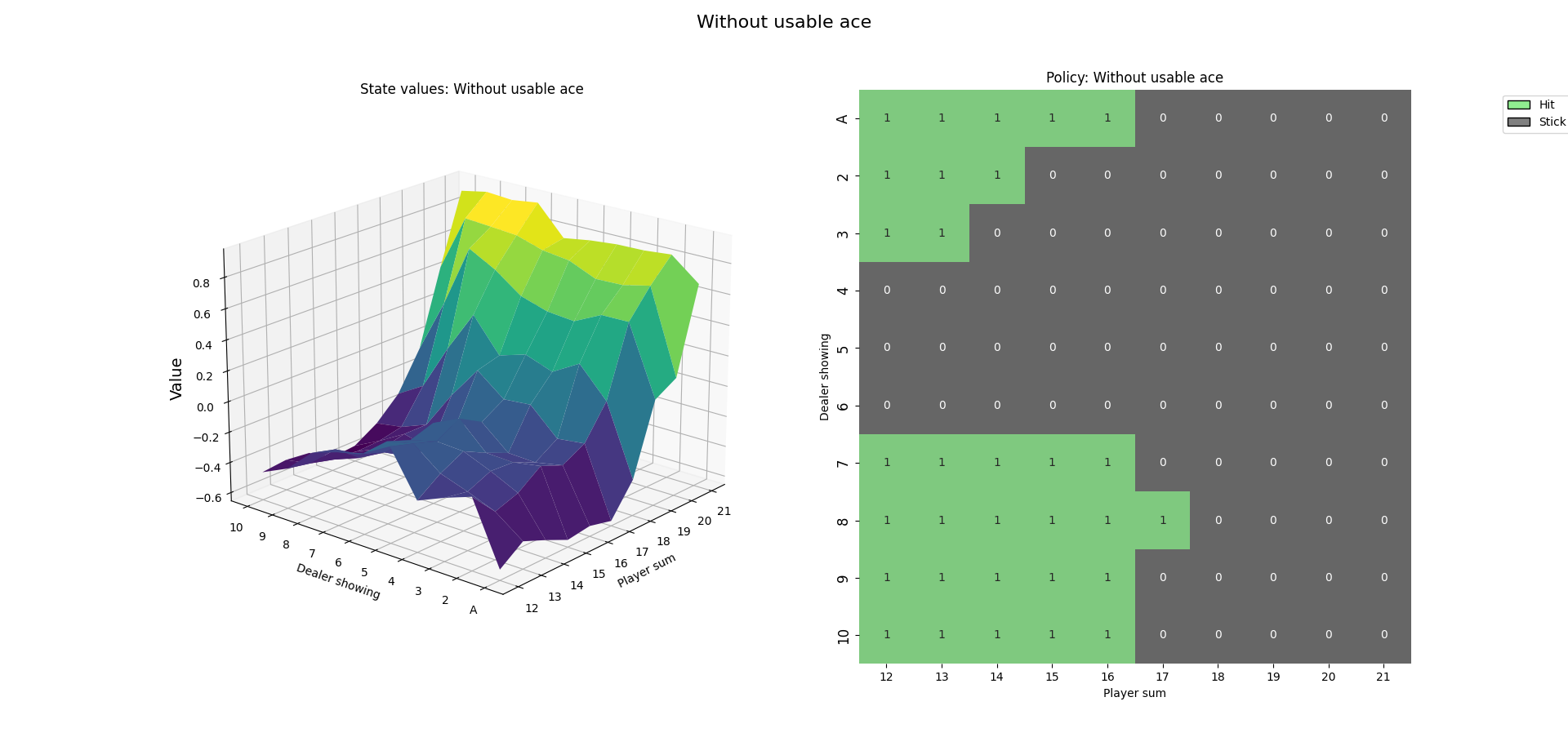
Thoughts
Q Learning算法的关键是更新Q Table的过程,原理是贝尔曼方程:,表示当前状态下采取动作a的Q Value等于即时奖励加上折扣后未来(下一个时间步)状态的最大Q Value- 对于
State Space和Action Space比较大的问题,Q Learning算法的Q Table可能会非常庞大,因此需要使用Deep Q Learning算法,用神经网络来近似Q Value,以减少存储空间,也就是DQN算法