TL;DR
- 本文是一篇关于强化学习算法分类的综述性文章,主要介绍了强化学习算法的分类方法,包括基于模型的分类、基于价值函数的分类、基于策略的分类、基于目标的分类、基于学习方法的分类等
强化学习算法分类
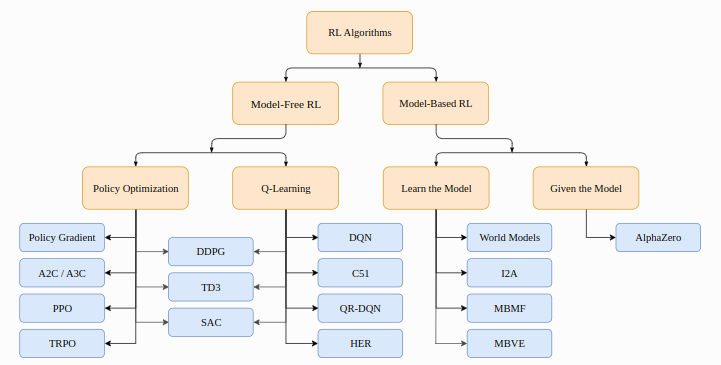
这张图表展示了强化学习(RL)算法的分类,分为无模型强化学习(Model-Free RL)和基于模型的强化学习(Model-Based RL)。
1. 无模型强化学习(Model-Free RL)
无模型强化学习方法不依赖于 环境的模型,而是通过与环境的交互来学习最优策略。它进一步分为策略优化(Policy Optimization)和 Q 学习(Q-Learning)。
1.1 策略优化(Policy Optimization)
策略优化方法通过直接优化策略函数来找到最优策略。常见的策略优化算法包括:
Policy Gradient: 通过计算策略梯度来更新策略函数,例如REINFORCE算法。Actor-Critic (A2C、A3C): 结合了策略梯度(Policy Gradient)和价值迭代(Value Iteration)的思想。Proximal Policy Optimization (PPO): 一种改进的Actor-Critic策略梯度方法,通过引入信任区域来提高训练的稳定性。Trust Region Policy Optimization (TRPO): 另一种策略梯度方法,通过限制策略的更新范围来提高训练的稳定性。
1.2 Q 学习(Q-Learning)
Q 学习方法通过学习动作值函数(Q 函数)来找到最优策略。常见的 Q 学习算法包括:
Deep Q-Network (DQN): 一种结合了深度学习和Q学习的方法,通过使用神经网络来逼近Q函数。Double Deep Q-Network (DDQN): 一种改进的DQN方法,通过引入双网络结构来减少过估计问题。Twin Delayed Deep Deterministic Policy Gradient (TD3): 一种改进的DDPG方法,通过引入延迟和双网络结构来提高训练的稳定性。Soft Actor-Critic (SAC): 一种基于最大熵强化学习的方法,通过引入熵正则化来提高探索能力。
1.3 其他 Q 学习方法
Categorical DQN (C51): 一种改进的DQN方法,通过将Q函数离散化为多个类别来提高训练的稳定性。Quantile Regression DQN (QR-DQN): 一种改进的DQN方法,通过引入分位数回归来提高训练的稳定性。Hindsight Experience Replay (HER): 一种改进的DQN方法,通过引入后见经验回放来提高探索能力。
2. 基于模型的强化学习(Model-Based RL)
基于模型的强化学习方法 依赖于环境的模型,通过使用模型来预测环境的动态性,从而找到最优策略。它进一步分为学习模型(Learn the Model)和给定模型(Given the Model)。
2.1 学习模型(Learn the Model)
学习模型方法通过与环境的交互来学习环境的模型,然后使用模型来预测环境的动态性。常见的学习模型算法包括:
World Models: 一种基于模型的方法,通过使用神经网络来逼近环境的动态性。Integrated Actionable Beliefs (IA2): 一种基于模型的方法,通过将信念状态和动作空间集成起来来提高训练的稳定性。
2.2 给定模型(Given the Model)
给定模型方法 假设环境的模型是已知的,然后使用模型来预测环境的动态性。常见的给定模型算法包括:
AlphaZero: 一种基于模型的方法,通过使用蒙特卡洛树搜索和神经网络来逼近环境的动态性。Model-Based Policy Optimization (MBPO): 一种基于模型的方法,通过使用模型来预测环境的动态性,然后使用策略优化方法来找到最优策略。Model-Based Value Expansion (MBVE): 一种基于模型的方法,通过使用模型来预测环境的动态性,然后使用价值迭代方法来找到最优策略。