URL
TL;DR
- 本文提出一种多模态理解和生成统一的架构,在
Qwen3-VL-8B的基础上加入了generation experts(3B)和DiT(2B),在不牺牲任何多模态理解能力的情况下,实现了生成和理解的统一。 - 可以解决图文输入图文输出的多模态任务,比如:
- 文生图
- 图像编辑
- 多模态理解等
Algorithm
1. 硬路由混合专家(Hard-Routing Mixture-of-Experts)
- 为了增加图像生成能力,
Mammothmoda2在Qwen3-VL-8B的内部加入了随即初始化的generation experts - 为了不牺牲
pretrain多模态理解的能力,pretrain模型的参数和generation experts的参数是通过 硬路由混合专家 的方式选择token的,具体来说就是:多模态理解的token激活原pretrain模型的参数(也被叫做understanding experts),图像生成的token激活新增的随机初始化的generation experts - 这样做的好处是啥?
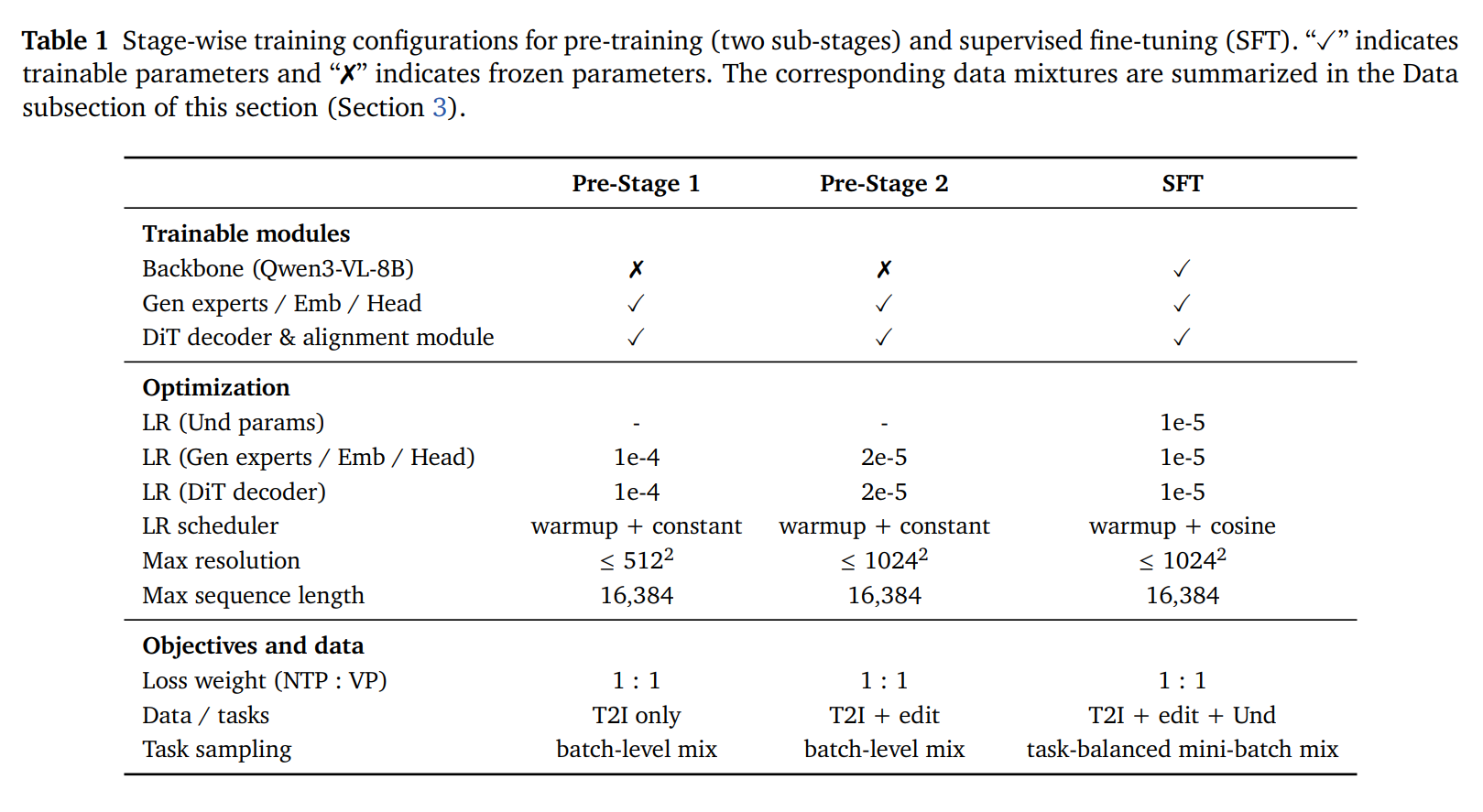
- 从上图可以看出在
pre-stage 1 / 2阶段,模型的backbone参数是冻结的,也就是说在第三列的SFT阶段之前,qwen3-vl-8b的多模态理解能力是不会受到任何影响的 - 硬路由混合专家的具体实现方式:
- 每层
transformer初始化一个新的ffn层,被称为generation experts;原始的ffn层叫做understanding experts - 为
generation任务扩展词表和扩展vocab embedding参数随机初始化 - 根据每一个
token是否属于generation token得到一个gen token mask - 每一层根据
gen token mask来为每一个token选择是激活哪个ffn
- 每层
- 作者通过消融实验对比了
ffn moe/attention moe/ffn-attention moe以及全层使用和仅深层使用,最终发现14层之后用ffn moe效果很好
2. 扩散生成器(Diffusion Generator)
qwen3-vl-8b作为大脑,DiT就是画图的手- 本文使用了一种单流扩散架构
DiT,将处理后的条件信号和噪声潜变量(由VAE编码)作为统一输入(而不是两个输入),通过全序列自注意力机制进行生成
3. AR-Diffusion 特征对齐模块
- 如果说
Qwen3-VL是大脑,DiT是手,那么AR-Diffusion特征对齐模块 就是神经系统 - 总体来说,特征对齐分为三个步骤:
- 多层级特征融合:不仅仅用
qwen3-vl-8b的最后一层输出,而是使用了模型深层的多层特征 - 统一条件编码:将
backbone输出的特征重新按照模态拆分,并分别压缩,再用双向transformer融合,作为condition encoding - 上下文条件注入:将原图通过
vae编码为noise,和condition encoding合并作为单流DiT的输入
- 多层级特征融合:不仅仅用
- 用一个例子说明:图像编辑任务,图像是一只猫,shape = (256, 256, 3),文本是:“给这只猫戴个红色的帽子”
- 假设图像经过
vit压缩之后的token长度L_v = 224,文本token长度L_t = 32,总长度L_seq = 256 - 取
qwen3-vl-8b后6层的特征,每层shape = (256, 4096),4096是qwen3-vl-8b的hidden size - 对
6层特征作平均池化(6, 256, 4096) -> (256, 4096) - 分离图文特征:
(256, 4096) -> (32, 4096) + (224, 4096) - 文本特征压缩:
(32, 4096) -> mlp -> (32, 1024),1024是DiT的hidden size - 图像特征压缩:
(224, 4096) -> QFormer -> (64, 4096),QFormer可以将任意长度的视觉特征编码成固定长度(64)的特征,做法是用64个query去cross attention - 图文特征重新融合得到 条件特征 :文本
(32, 1024)+ 视觉(64, 1024)-> 拼接为(96, 1024)-> 双向Transformer编码 -> 输出 条件特征(96, 1024) - 原图用
vae压缩为 噪声潜变量:(256, 256, 3) -> vae -> (32, 32, 4) -> flatten -> (1024, 4) -> mlp -> (1024, 1024) - 噪声潜变量和条件特征合并作为单流
DiT输入:(96, 1024) + (1024, 1024) -> (1120, 1024) -> DiT -> Target Image
- 假设图像经过
4. 训练策略
4.1 预训练
预训练过程冻结 backbone
- 第一阶段:生成基础(
Pre-Stage 1)- 目标:建立文本到图像(
T2I)的基础映射关系。 - 数据:仅使用
T2I数据,分辨率限制在 。 - 策略:
DiT仅接收来自AR骨干网的文本特征 作为条件。此时,生成专家(Generation Experts)和DiT参数从零开始训练,而理解参数被冻结。 - 逻辑:在低分辨率和单一模态条件下,模型更容易收敛,学会基本的物体形状和构图。
- 目标:建立文本到图像(
- 第二阶段:复杂指令与编辑(
Pre-Stage 2)- 目标:引入图像编辑能力和高分辨率生成。
- 数据:引入图像编辑(
Image Editing)数据,分辨率提升至 。 - 策略:
DiT开始接收文本+视觉的双重特征。此时,模型开始学习如何理解输入图像(例如“把图中的猫变成狗”),并保留原图的背景结构。 - 关键点:这一阶段是
Mammoth2区别于普通T2I模型的关键,它开始具备“看图改图”的能力。
4.2 SFT
- 所有参数都解冻,全部参与更新,通过联合优化,
AR部分学会了生成更适合DiT解码的语义规划,而DiT也学会了更好地适应AR的意图
4.3 RL
Mammoth2引入了DiffusionNFT (Negative-aware Fine-Tuning),这是一种针对流匹配模型的开创性RL算法 。
Thought
- 为了保留
vlm模型的能力作了很大的创新,理论上作生成任务的潜力很大 - 理解和生成统一架构可能是未来发展方向