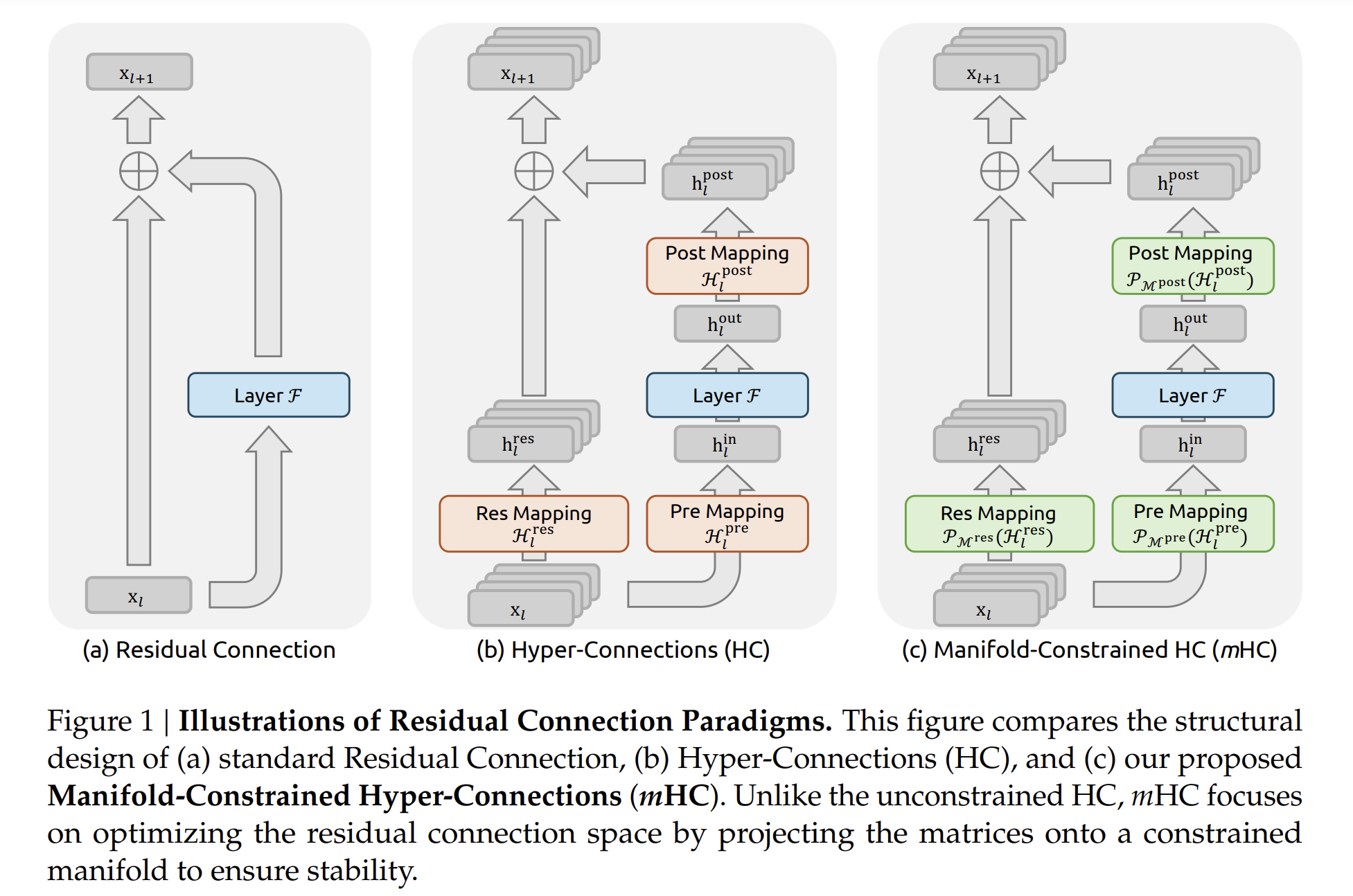
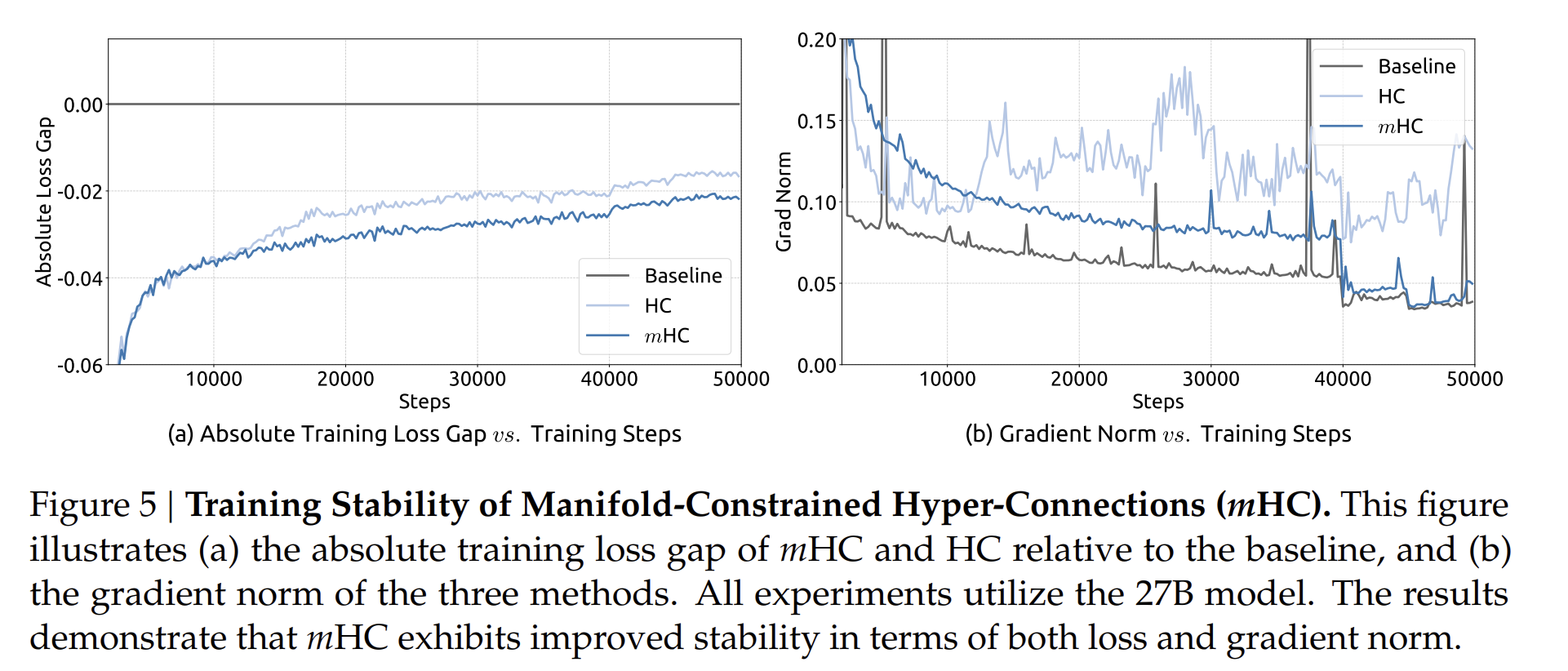
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| class MHCMappings(nn.Module):
def __init__(self, n, C):
super().__init__()
self.n = n
self.C = C
self.nc = n * C
self.phi_pre = nn.Linear(self.nc, n, bias=False)
self.phi_post = nn.Linear(self.nc, n, bias=False)
self.phi_res = nn.Linear(self.nc, n * n, bias=False)
self.b_pre = nn.Parameter(torch.zeros(n))
self.b_post = nn.Parameter(torch.zeros(n))
self.b_res = nn.Parameter(torch.zeros(n, n))
self.alpha_pre = nn.Parameter(torch.tensor(0.01))
self.alpha_post = nn.Parameter(torch.tensor(0.01))
self.alpha_res = nn.Parameter(torch.tensor(0.01))
self.norm = RMSNorm(self.nc)
def forward(self, x):
"""
x: (n, C)
return:
H_pre : (1, n)
H_post : (1, n)
H_res : (n, n)
"""
x_flat = x.reshape(1, self.nc)
x_norm = self.norm(x_flat)
H_pre_tilde = (
self.alpha_pre
* torch.tanh(self.phi_pre(x_norm))
+ self.b_pre
)
H_post_tilde = (
self.alpha_post
* torch.tanh(self.phi_post(x_norm))
+ self.b_post
)
H_res_tilde = (
self.alpha_res
* torch.tanh(self.phi_res(x_norm))
).reshape(self.n, self.n) + self.b_res
H_pre = torch.sigmoid(H_pre_tilde)
H_post = 2.0 * torch.sigmoid(H_post_tilde)
H_res = sinkhorn_knopp(H_res_tilde)
return H_pre, H_post, H_res
|