URL
TL;DR
- 论文题目是:“通过可扩展查找的条件内存:大语言模型的新稀疏轴”,目标是找到一种条件记忆方法,解决目前大语言模型靠大量计算来拟合记忆的问题,换句话说:目前的大模型都是纯计算,没有记忆,但本论文将计算和记忆在某种程度上进行解耦
N-gram是一种在自然语言处理领域非常古老的算法,目的是抽取自然语言局部相关性,类似于卷积之于图像- 提出
Engram架构,通过现代化的N-gram嵌入技术,实现了常数级时间复杂度 的静态知识查找,释放了模型主干的计算压力,可以看成是一种新的稀疏
总体流程
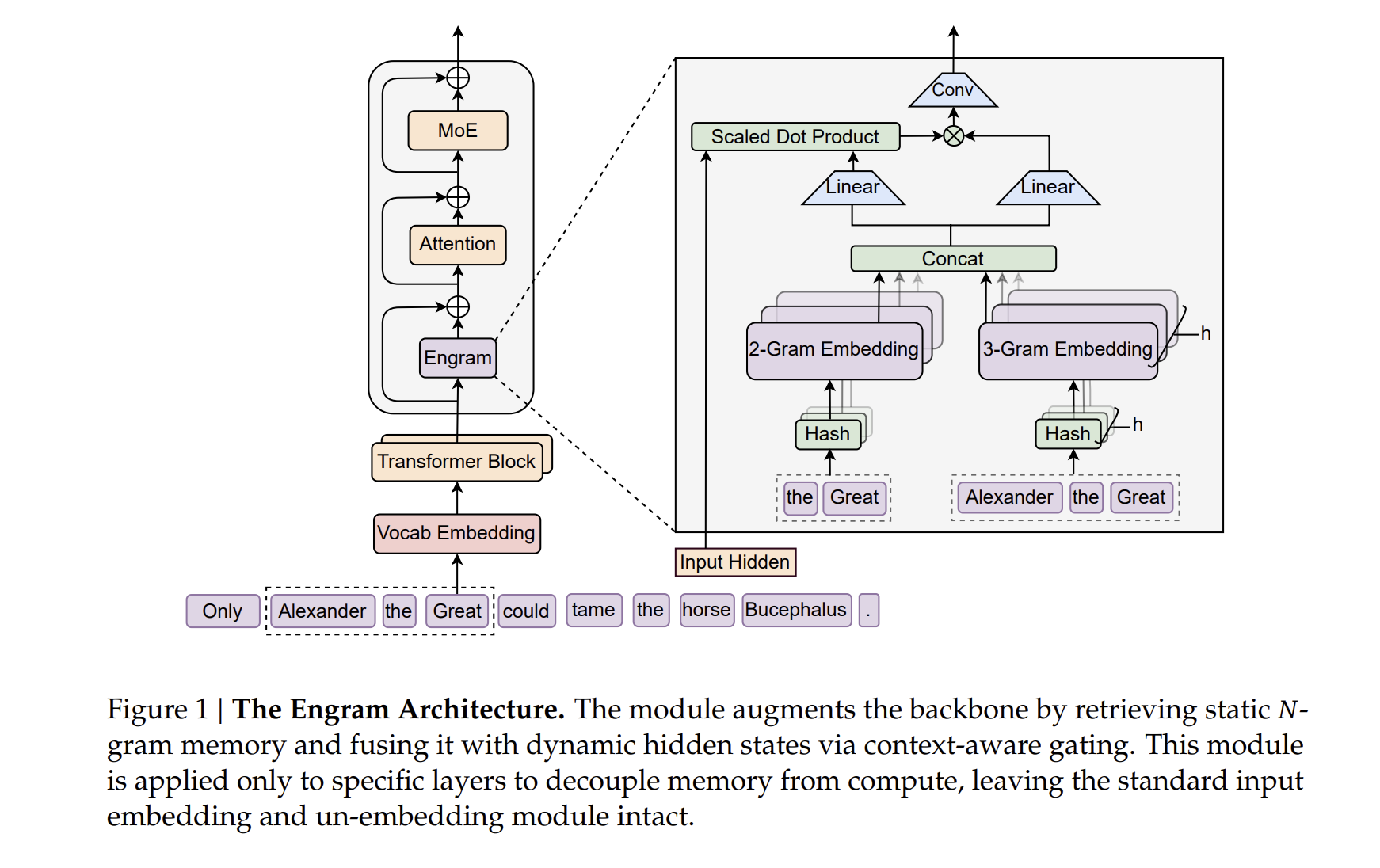
- 标准
Transformer包含Attention+MoE,增强Transformer包含Engram+Attention+MoE
1. 词表压缩
- 具体做法是规范化:
1 | normalizers.Sequence([ |
- 从
128815词表大小降低到98627
2. N-gram 哈希
1. 先做 shift
- 输入:
x = [t0, t1, t2, t3, t4] - 构造:
shift_0: [t0, t1, t2, t3, t4]shift_1: [PAD, t0, t1, t2, t3]shift_2: [PAD, PAD, t0, t1, t2]
2. 做 N-gram 哈希
1 | mix = ( |
其中:
m0, m1, m2:- 奇数
- 与
layer_id相关 - 随机但可复现
- 为什么是
XOR?- 顺序敏感
- 分布均匀
- 比加法抗碰撞
- 比
MurmurHash便宜
3. 多 Head:同一个 n-gram,多种 hash 视角
- 一个
n-gram对应多个embedding lookup,这和Multi-Head Attention的思想是完全一致的 - 对素数词表取余数
1 | # n_head_per_ngram = 8 |
3. 根据 hash 后的 index lookup embedding
1 |
|
- 对模型的第
1层和第15层使用engram模块 - 每个
engram模块用2-gram / 3-gram - 每个
n-gram有8个头 - 每个头对应一个约等于
129280 * 5的embedding table,且完全不共享
| 维度 | 是否共享 |
|---|---|
| 不同 layer(1 vs 15) | ❌ 不共享 |
| 不同 n-gram(2 vs 3) | ❌ 不共享 |
| 同一 n-gram 的不同 head | ❌ 不共享 |
| embedding 表 | 全部独立 |
4. 查到 embedding 之后,计算得到输出
embedding用来生成一个gate factor,去调制原始input hidden- 换句话说:
Engram不是“提供新特征”,而是“决定哪些原始hidden值值得被放大 / 抑制”
1 | embeddings = embedding_lookup(hash_ids) # (B, T, E) |
推理优化
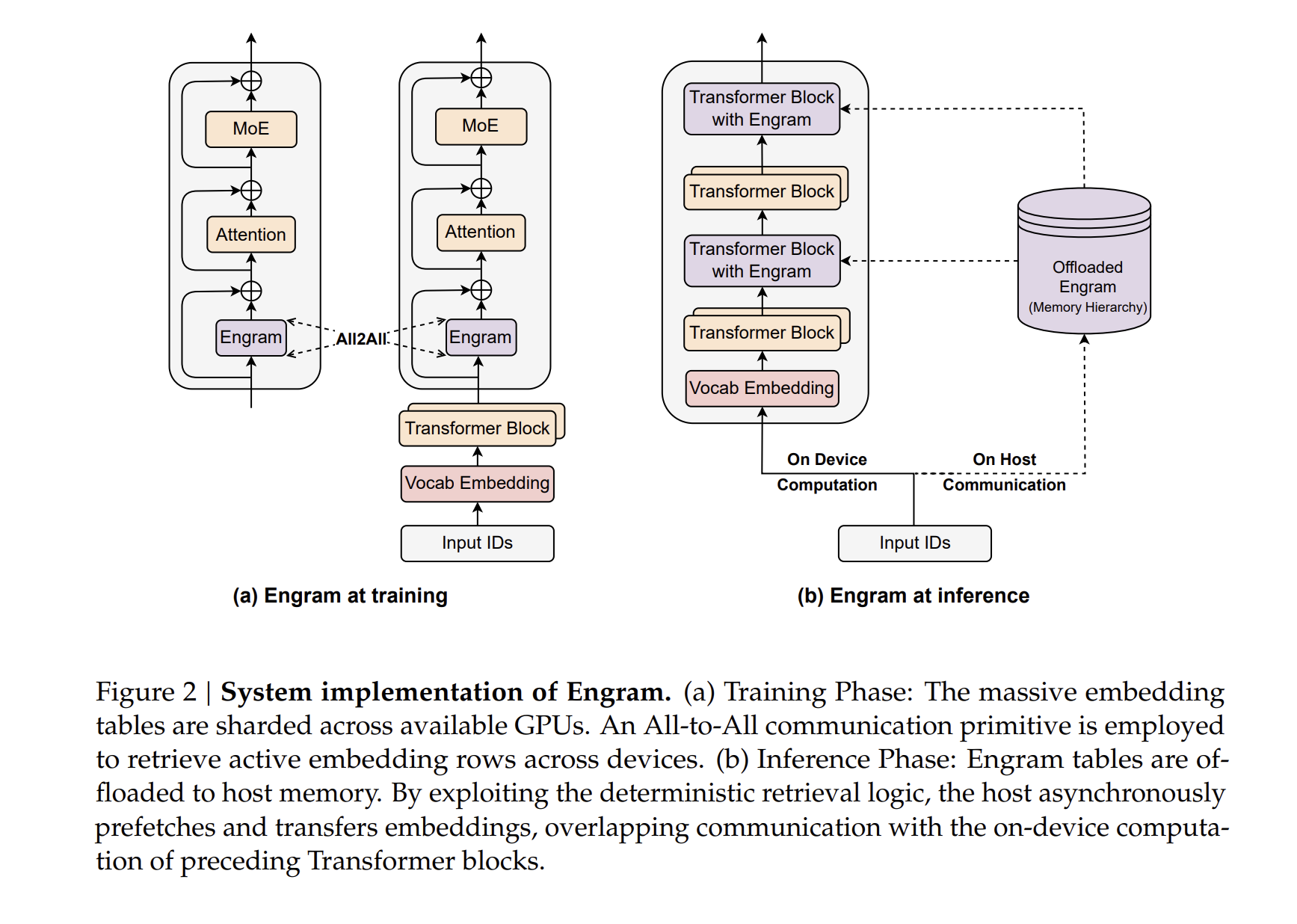
- 由于哈希索引仅依赖于输入
token,Engram的查找操作具有确定性。 - 在推理过程中,系统可以异步地从主机内存(
CPU RAM)通过PCIe总线预取所需的嵌入向量- 通信隐藏:通过将 Engram 模块放置在主干网络的较深层(如第
15层),可以利用前续层的计算时间来掩盖内存读取的延迟 - 吞吐量损耗极低:实测显示,在将
100B参数的嵌入表卸载到主机内存的情况下,推理吞吐量的下降幅度小于3%
- 通信隐藏:通过将 Engram 模块放置在主干网络的较深层(如第
- 多级缓存层次结构:
- 基于
N-gram的Zipfian分布规律(长尾效应),研究者提出了一种多级缓存设计GPU HBM:存放访问频率最高的N-gram嵌入- 主机
DRAM:存放大部分中等频次的嵌入 NVMe SSD:存放长尾的、极其罕见的模式
- 这种层次结构使得模型可以支持近乎无限的参数扩展,而不会触及
GPU显存的硬上限
- 基于
Thought
- 这种对
transformer layer的改动确实很牛,O(1)复杂度太强了 - 还考虑了推理存储的
memory hierarchy,不得不说DeepSeek确实不讲故事,真挑不出毛病