URL
- paper: https://arxiv.org/pdf/2010.04159.pdf
- code: https://github.com/fundamentalvision/Deformable-DETR
TL;DR
- 提出了
Deformable DETR:这是一种新的目标检测模型,解决了现有DETR模型的收敛速度慢和特征空间分辨率有限的问题。 - 使用可变形的注意力模块:这些模块只关注参考点周围的一小部分关键采样点,从而在更少的训练周期内提高了性能,尤其是对小对象的检测。
- 结合了可变形卷积的稀疏空间采样和
Transformer的关系建模能力:这使得模型能够在处理大规模数据时保持高效,同时还能捕捉到复杂的上下文关系。 - 引入了一种两阶段的变体:在这个变体中,区域提议由
Deformable DETR生成,然后进行迭代的细化。这使得模型能够更精确地定位和识别目标。
Algorithm
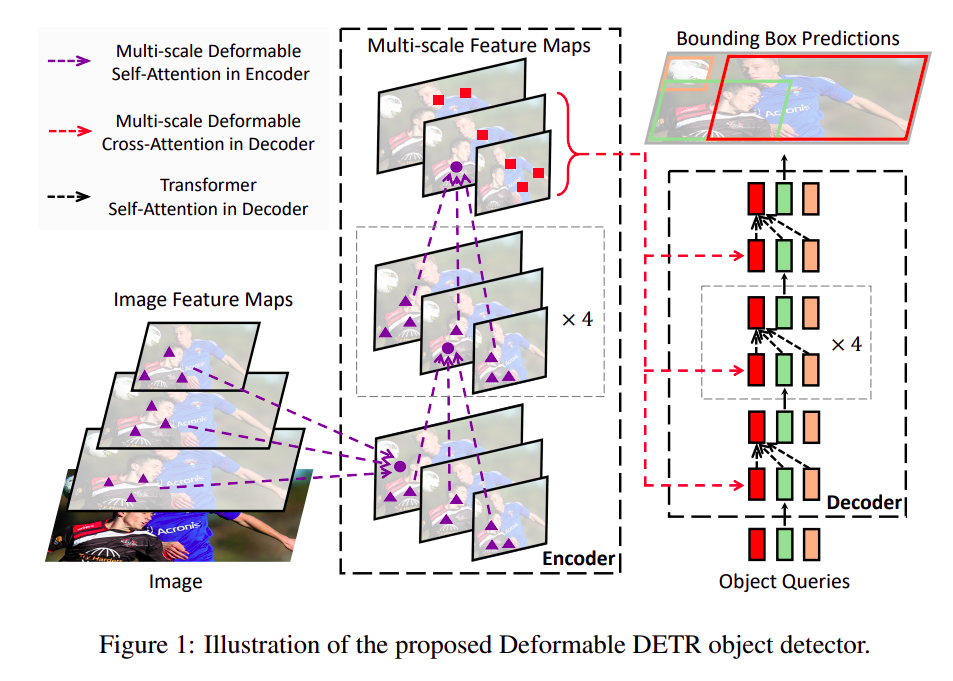
Deformable DETR整体结构图
Deformabel Attention Block
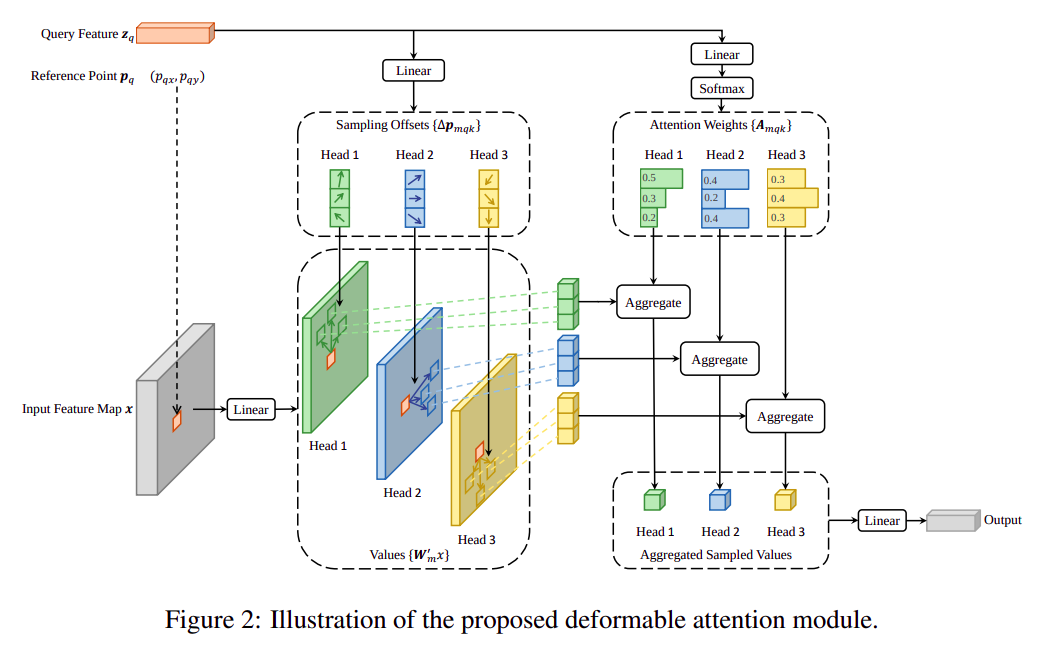
Multi-Head Attention:
-
输入为一个
query的表征 ,以及总特征x,输出为query查询结果向量 -
M表示number of head -
表示
-
实际上就是
self-attention中的
-
Deformable Attention:
- 输入为一个
query的表征 ,总特征x,以及query对应的 预设采样位置,输出为query查询结果向量 - 表示由 计算得到的 基于预设查询位置的横纵偏移
- ,即
point position attention是由query线性映射得到的 ,因此Deformable Attention没有Key的存在,只有Query和Value K表示number of points,即采样点个数
- 输入为一个
Multi-Scale Deformable Attention:
- 与
Deformable Attention不同的是,输入的x变成了多尺度特征(例如backbone不同深度的特征),更贴近实际视觉工程化应用场景 point采样范围是所有level的feature map,即MSDefromableAttention有全局attention信息
- 与
Deformable Attention和Self Attention对比
1 | import torch |
Thought
- 用
query线性映射代替query和key外积做attention数学上可解释性会变差,计算复杂度会降低 Deformable Conv是典型的对NPU不友好,Deformable Attention会更复杂,被代季峰支配的恐惧- 用
Multi-scale做各特征尺度上的信息融合,开创了一个 CNN 做 backbone + Deformable Transformer 做 head 的计算机视觉任务模型新范式,甚至省去了FPN - 总之是用各种便宜的计算来近似复杂的全局
attention,复杂度从H*W-->K,即