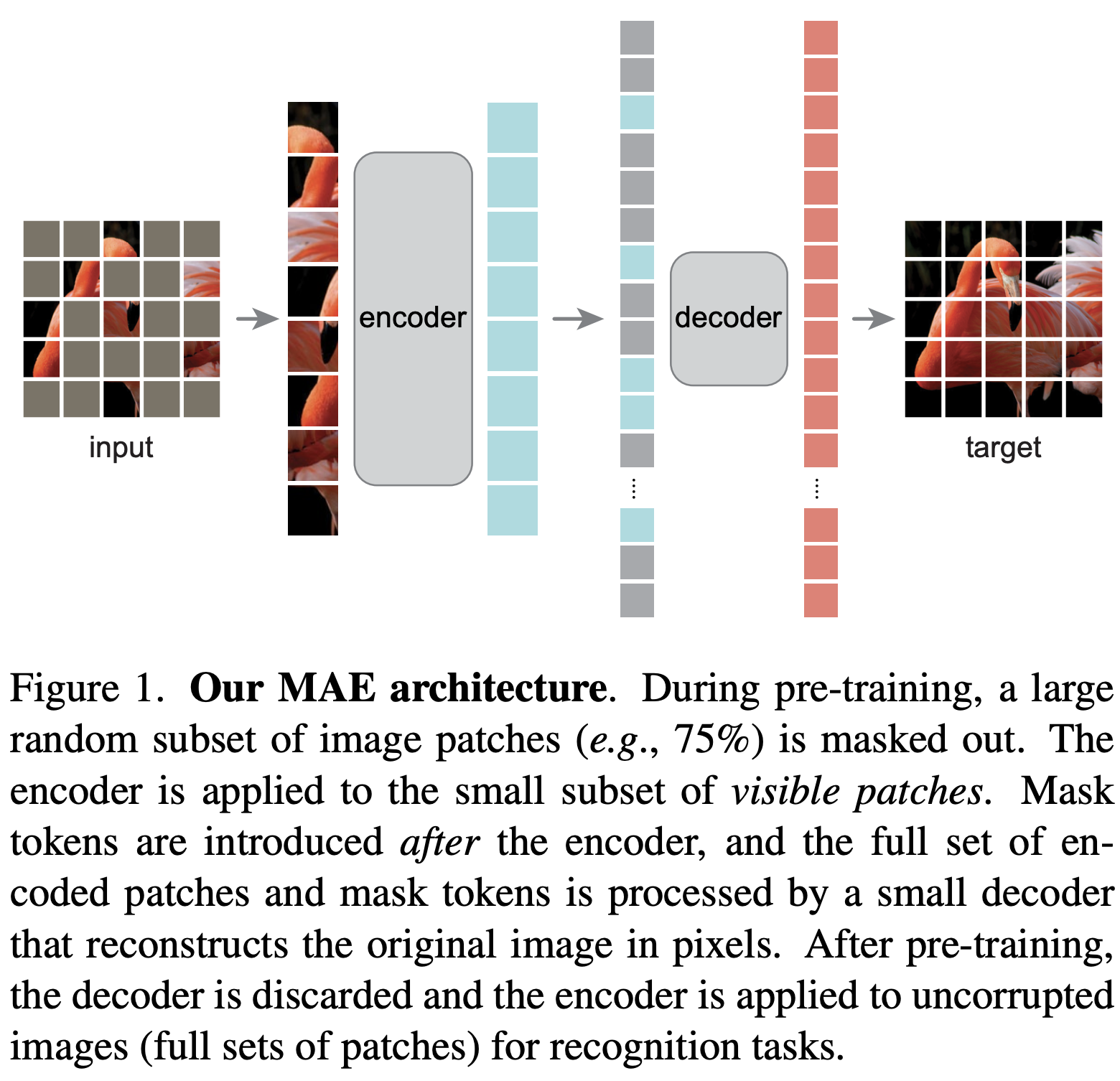
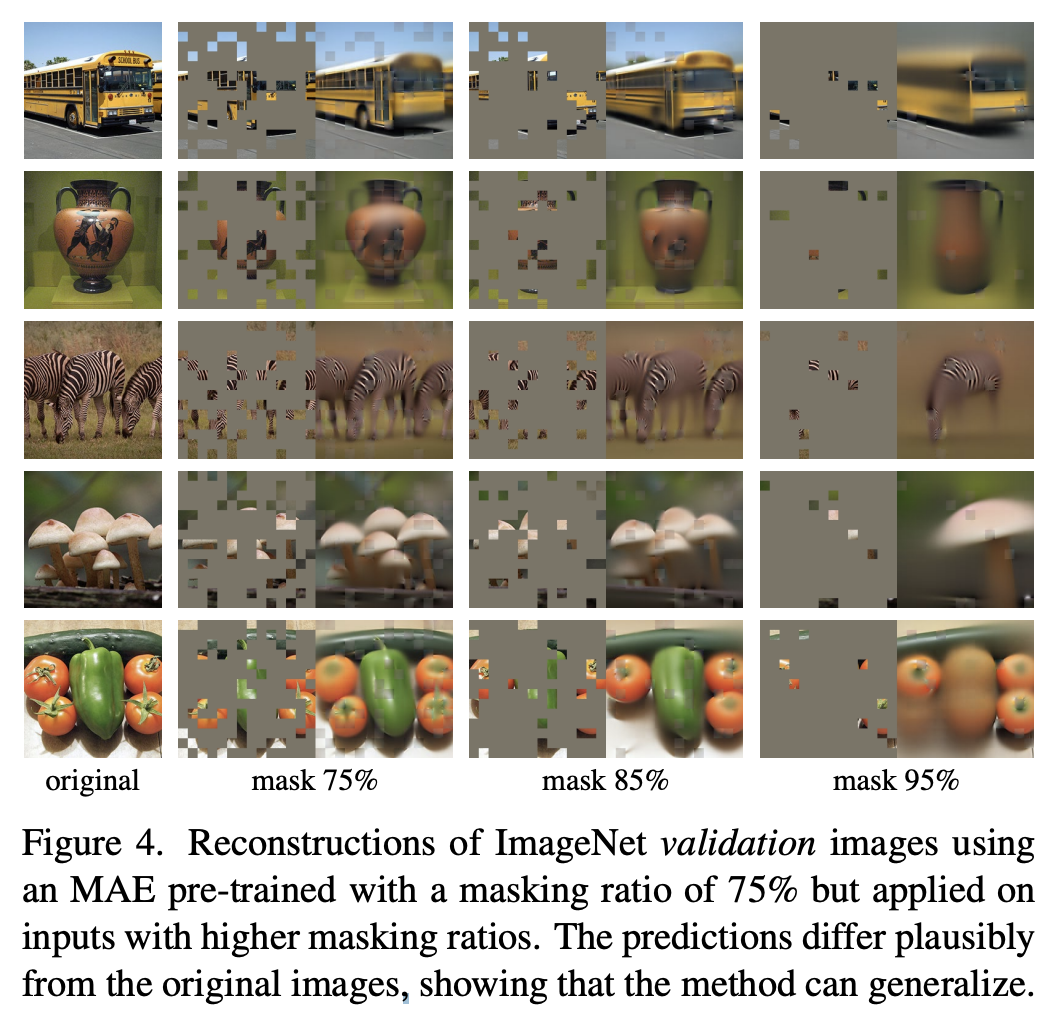
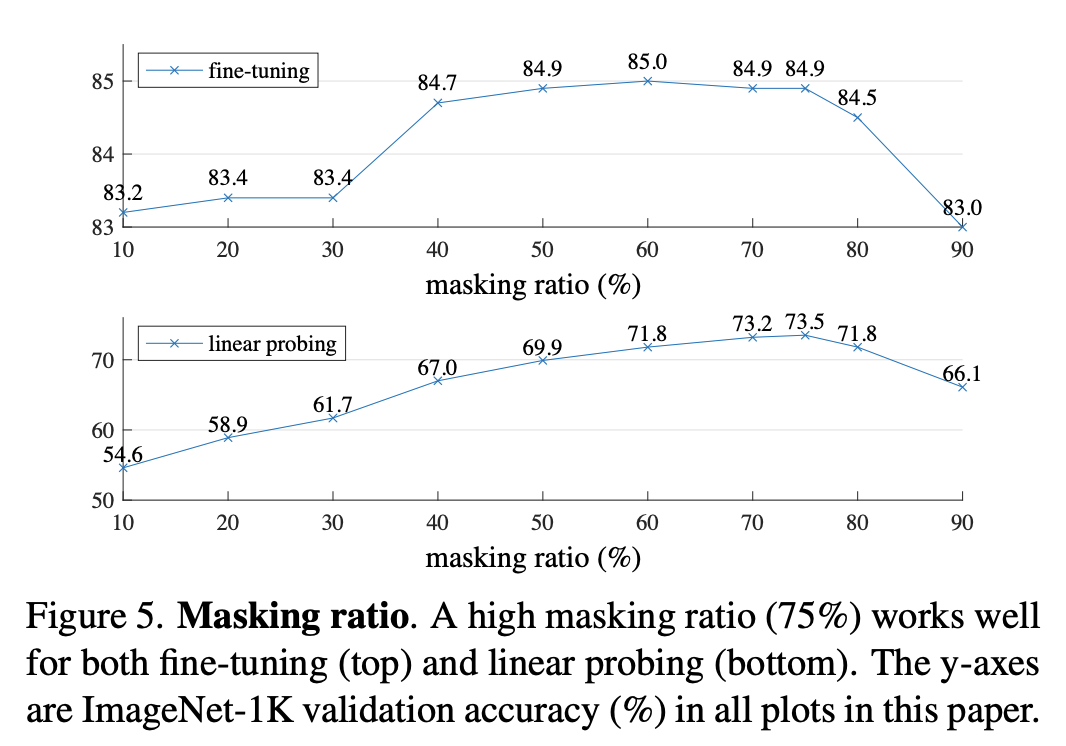
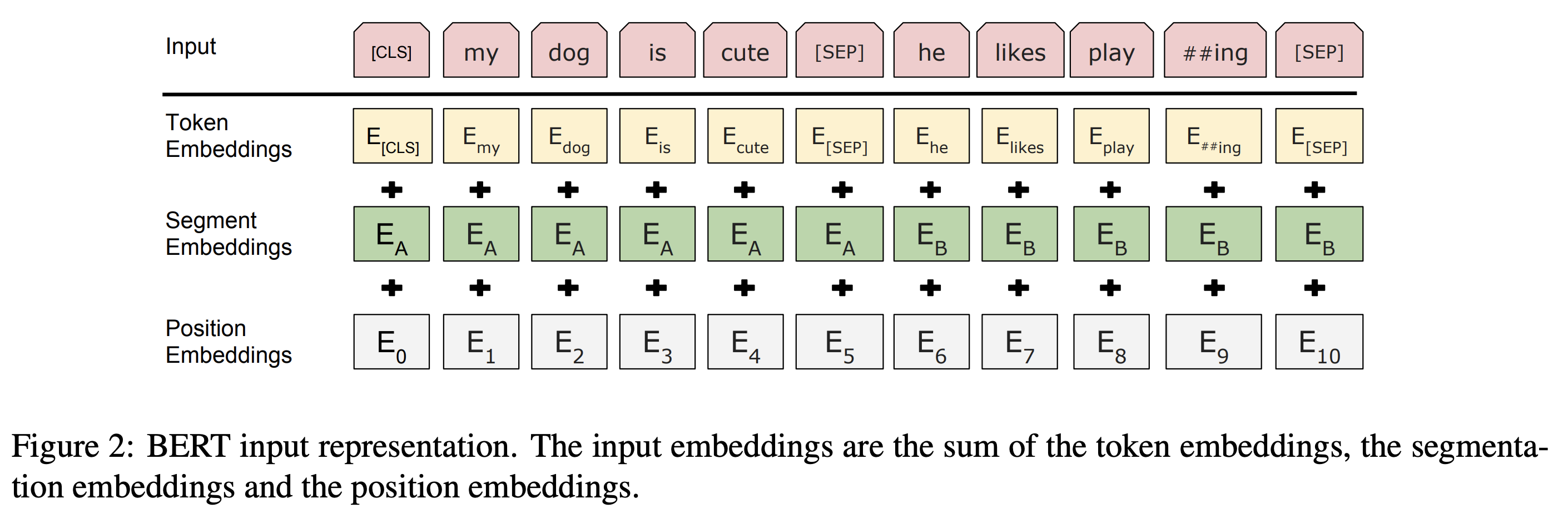
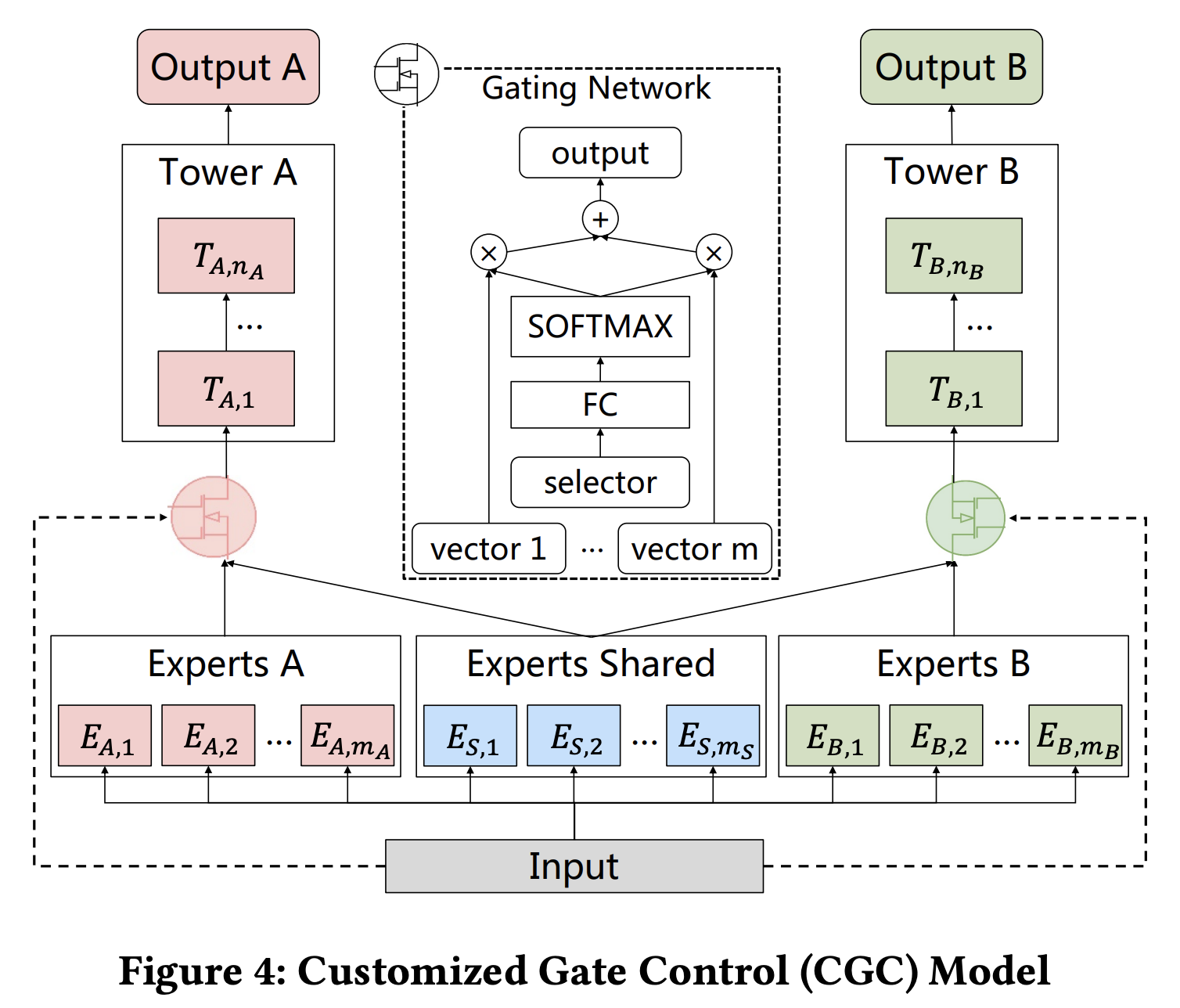
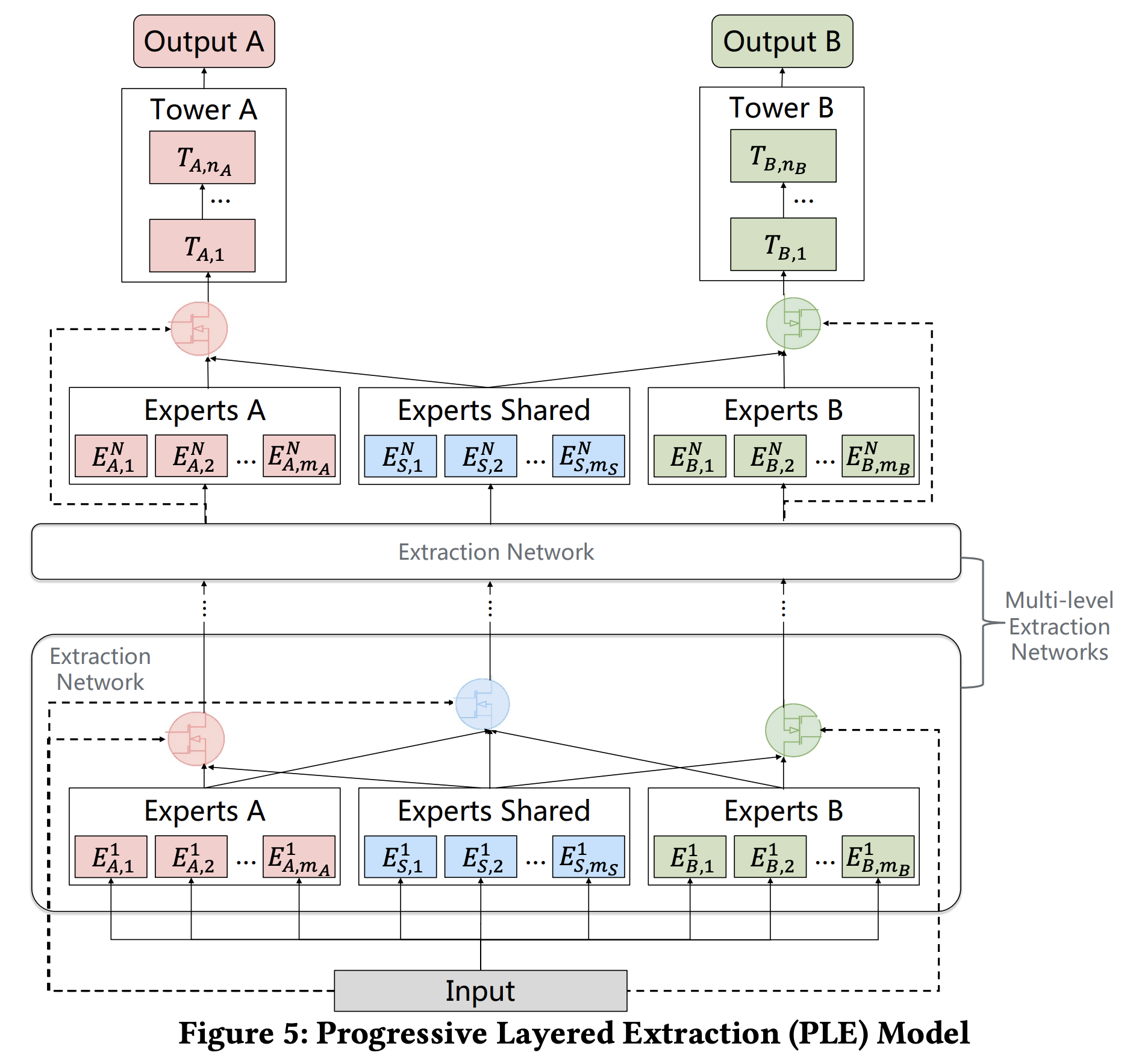
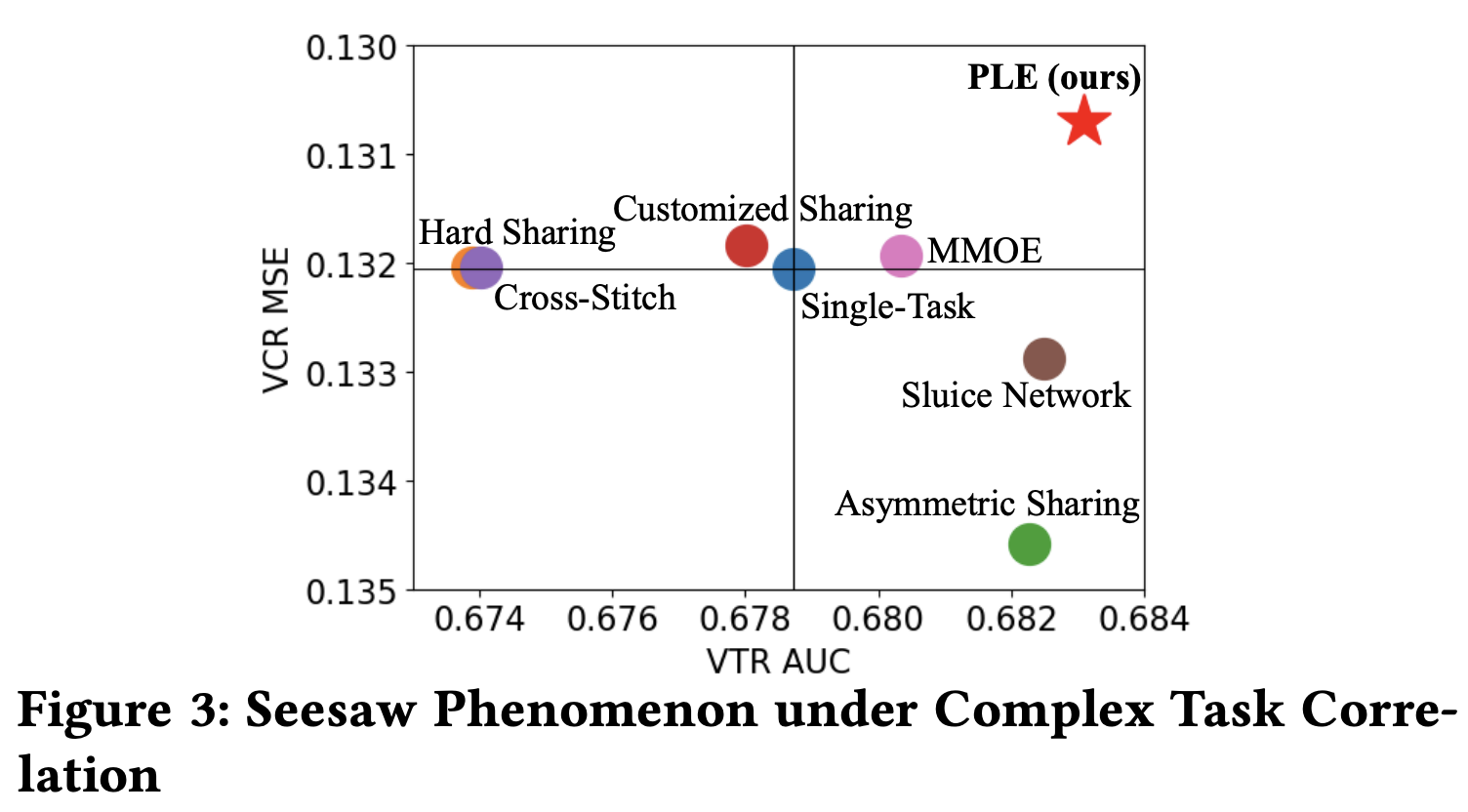
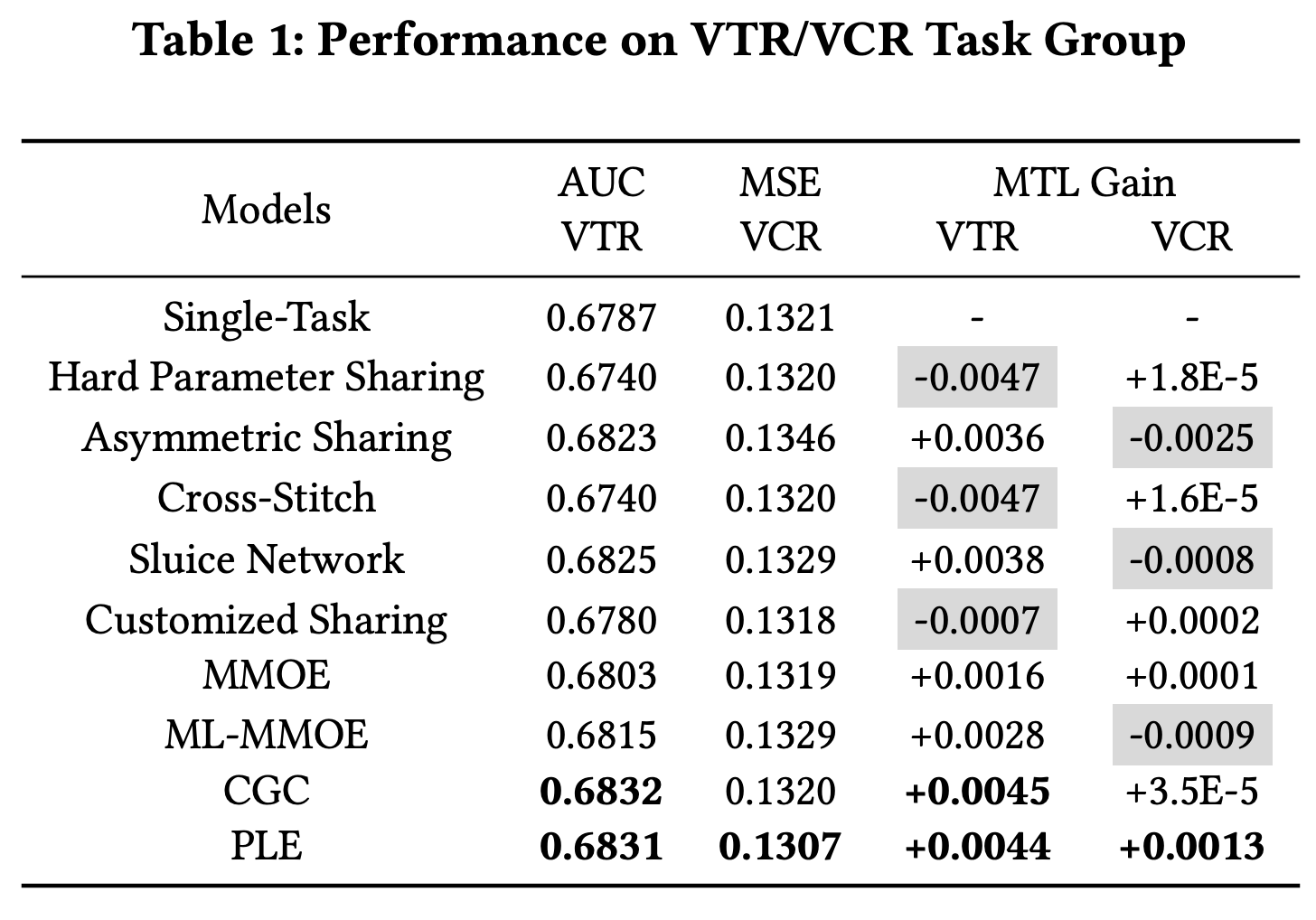
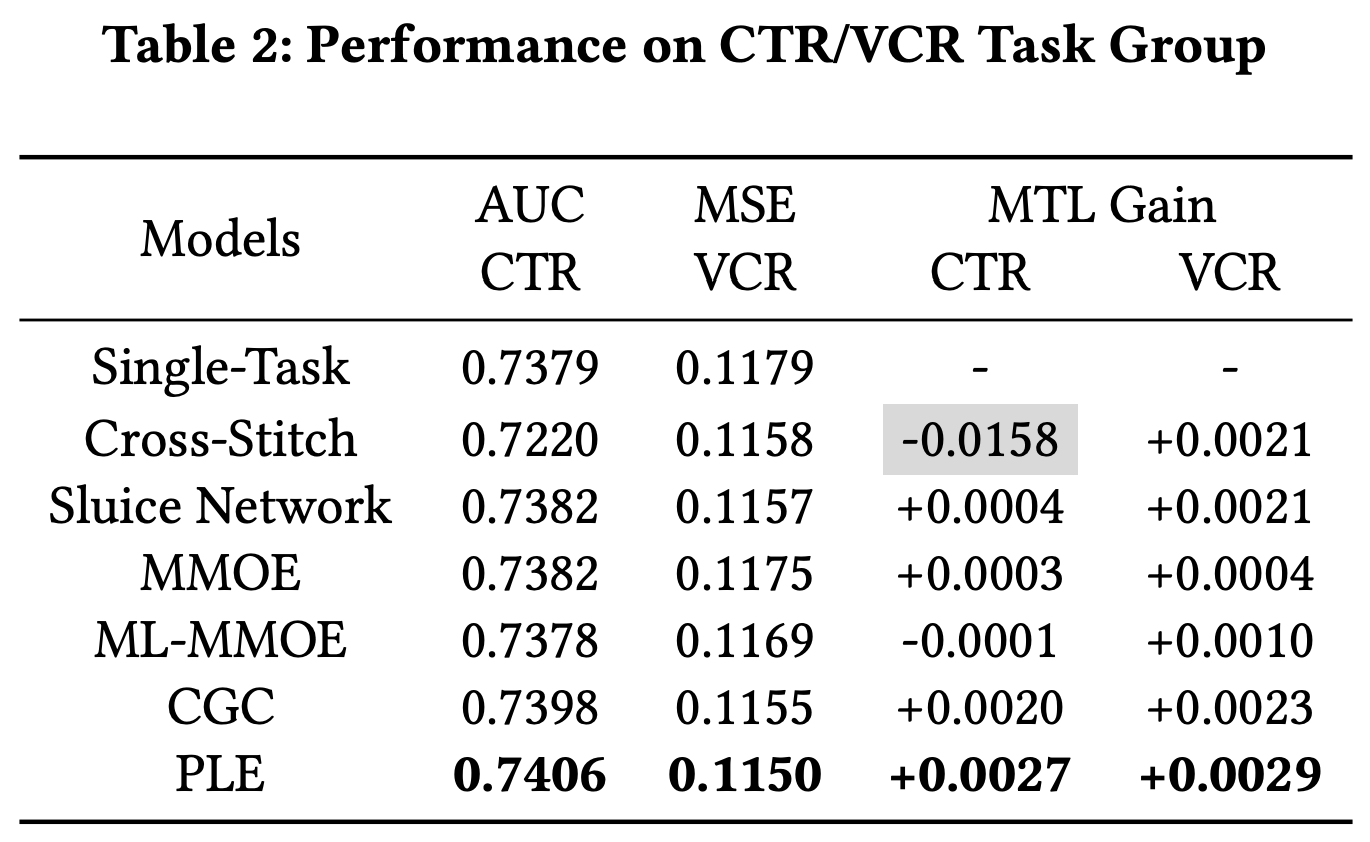
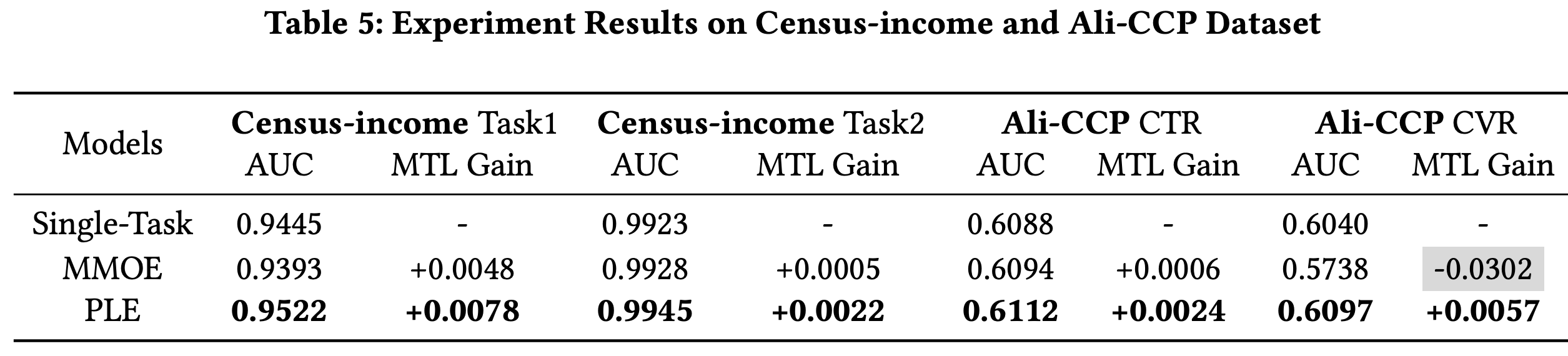
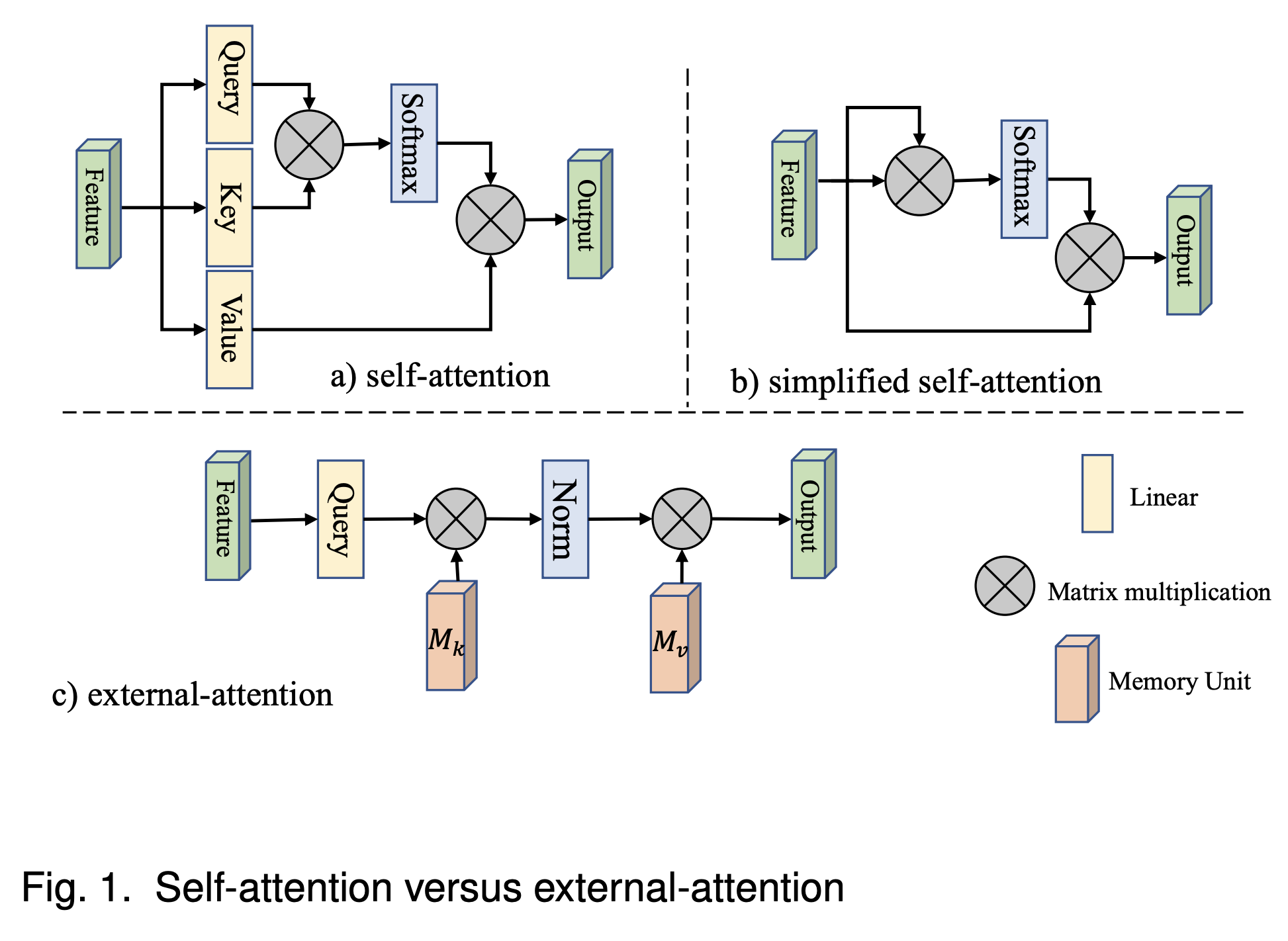
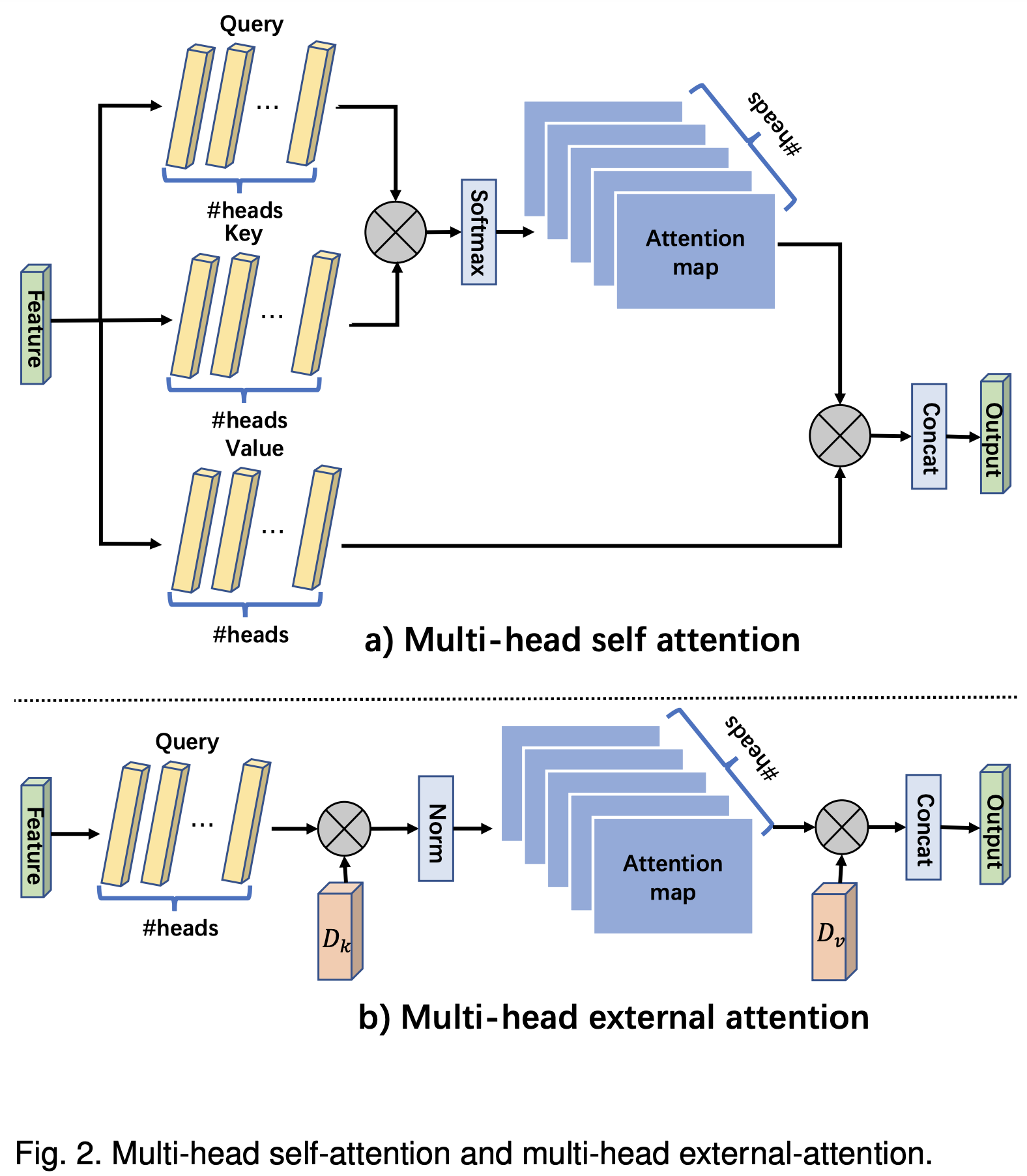
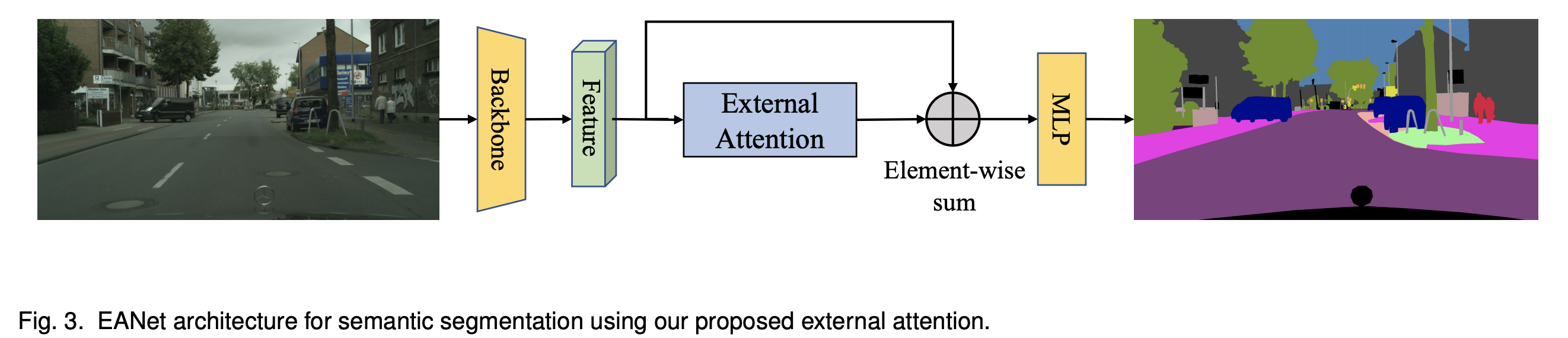
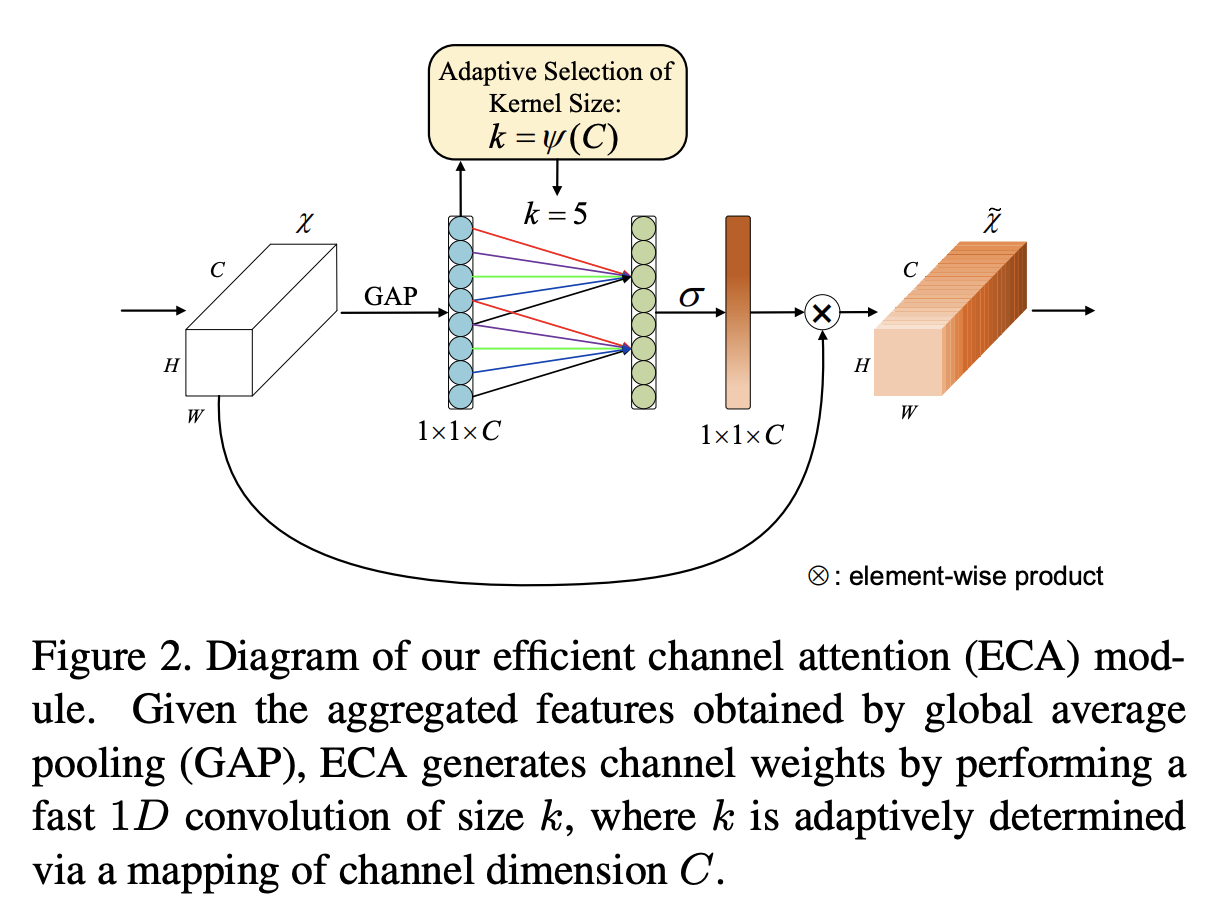
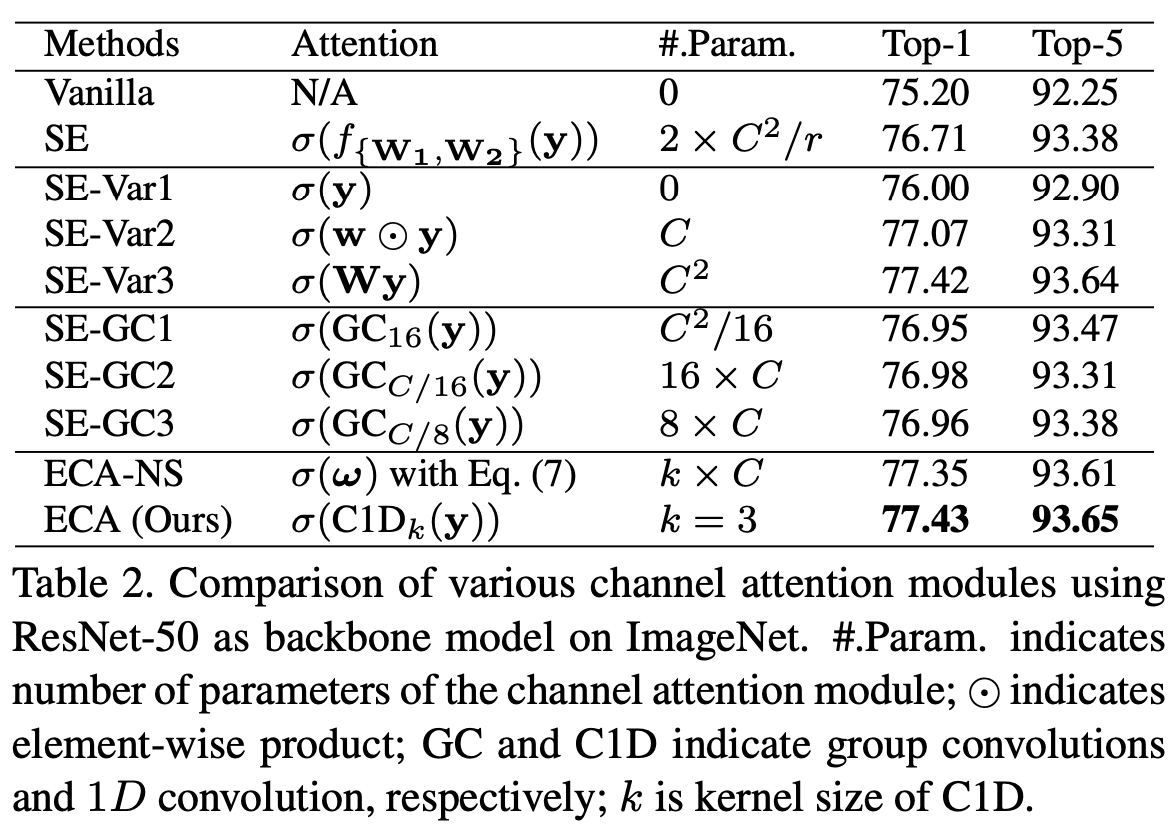
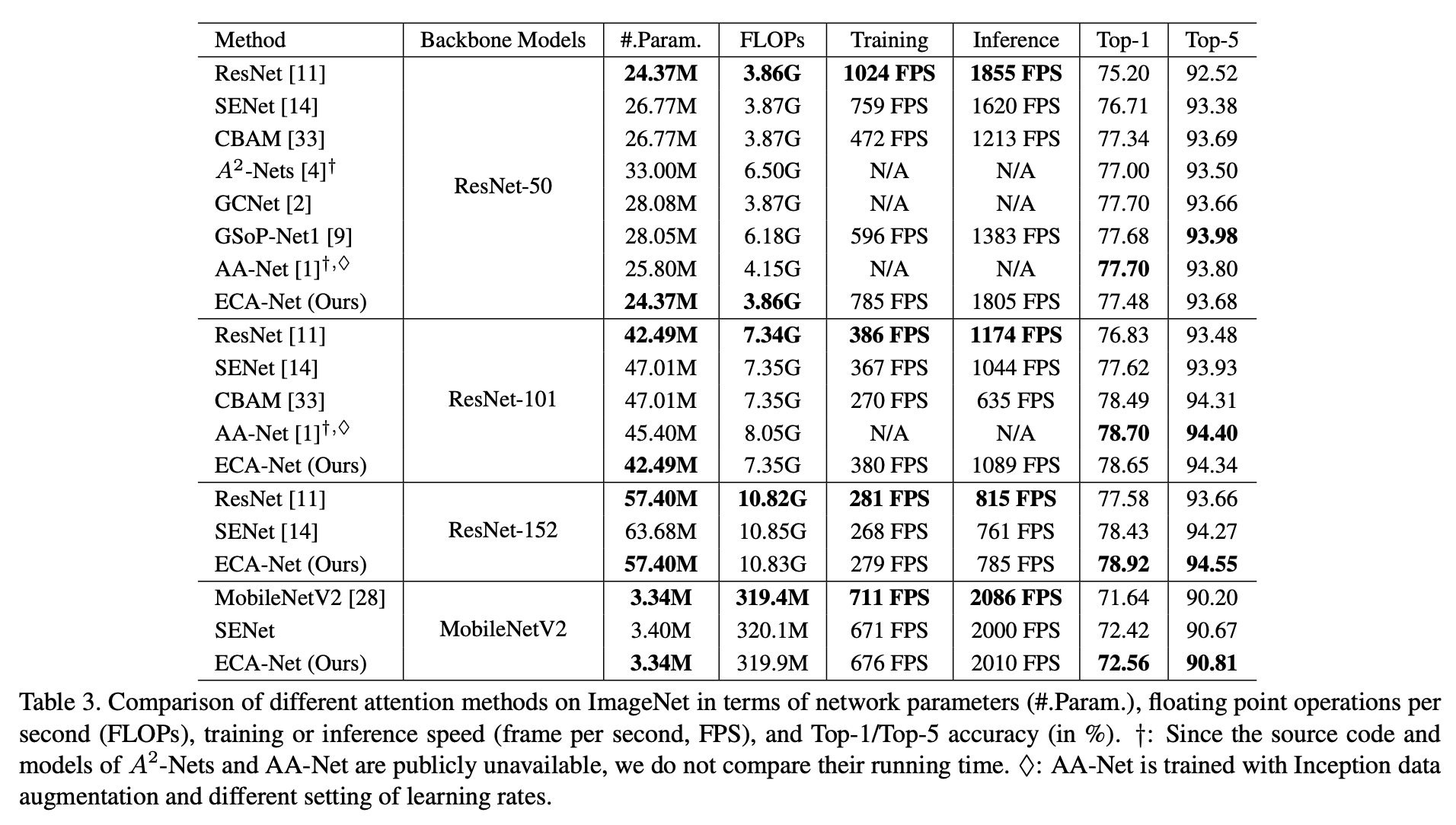
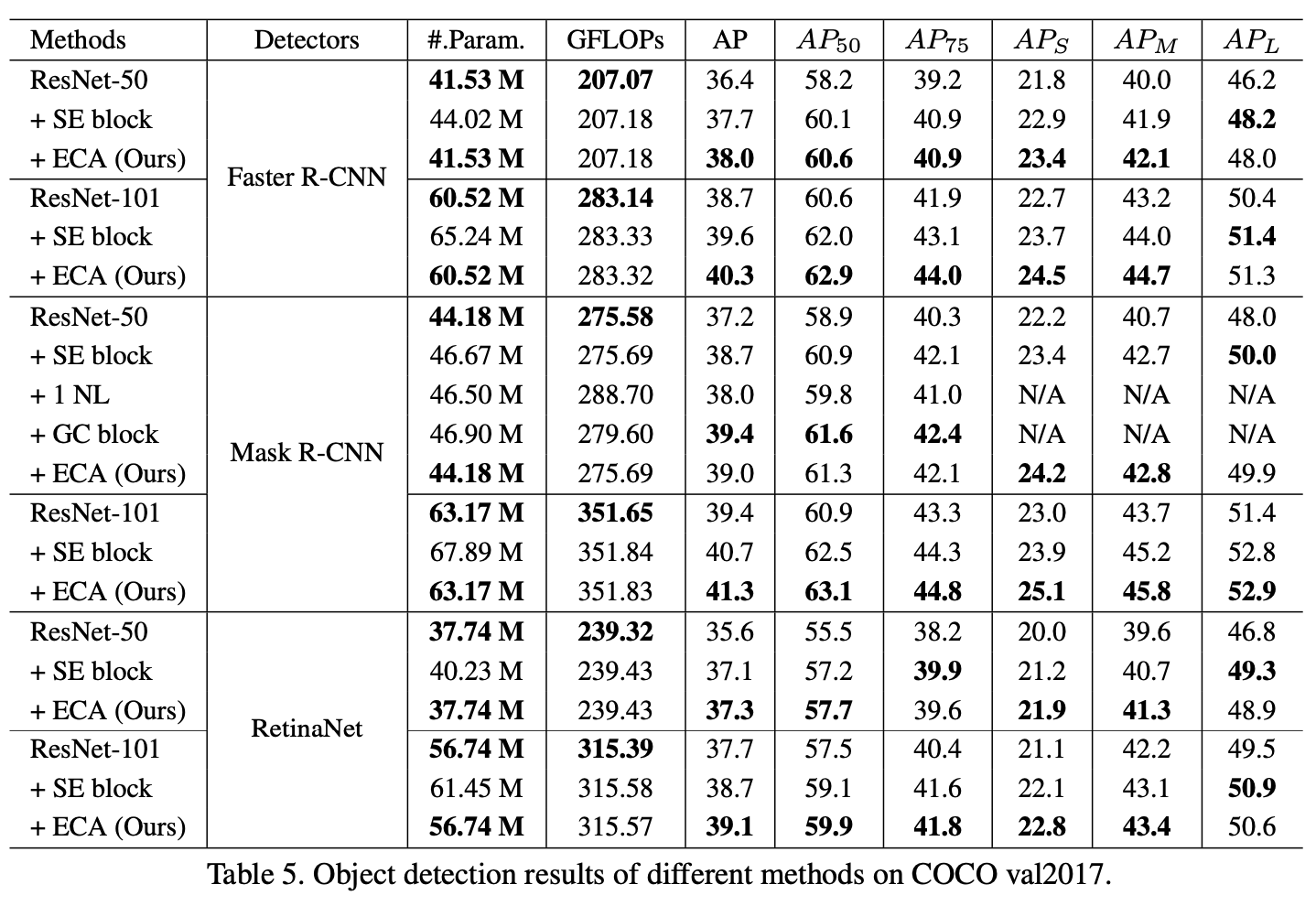
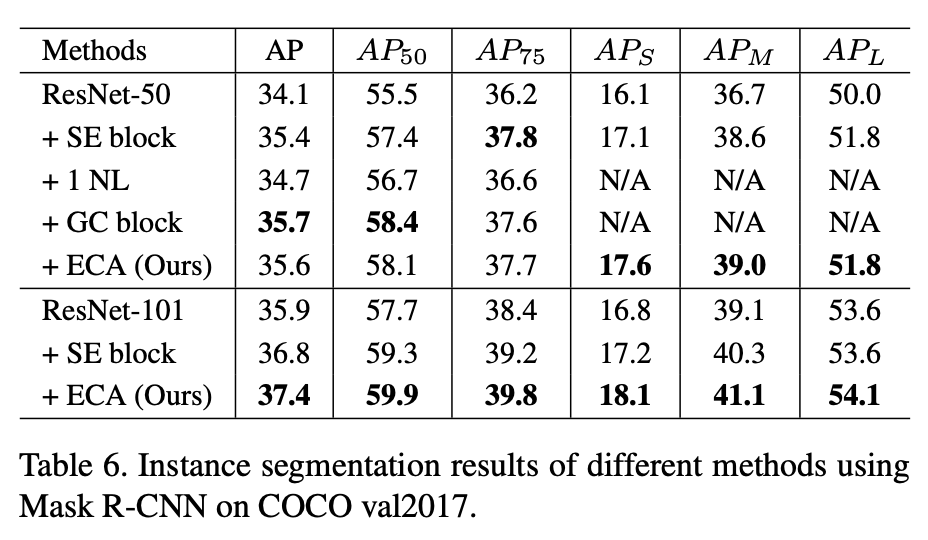
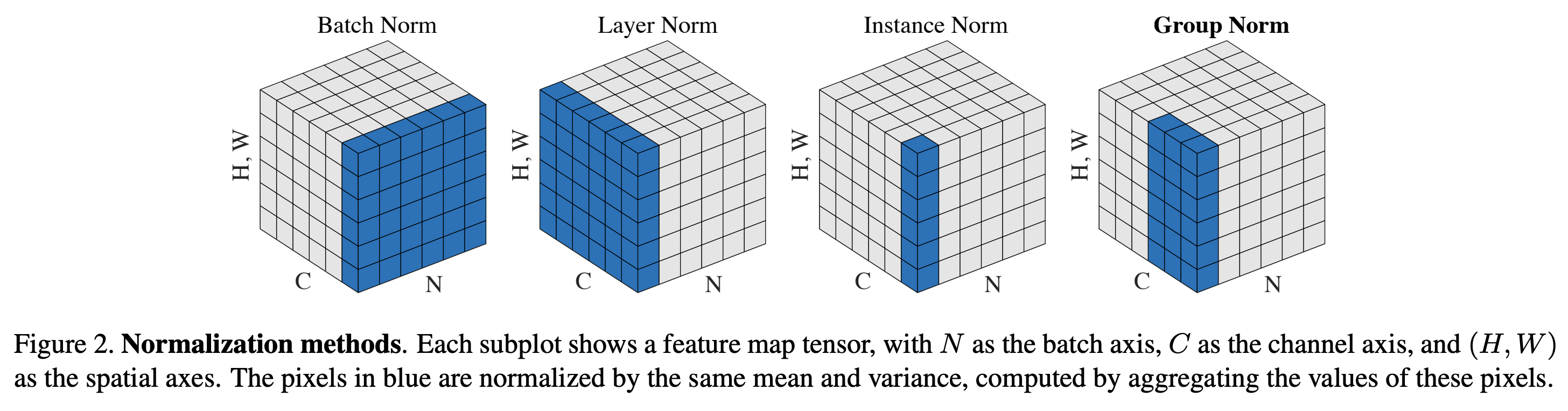
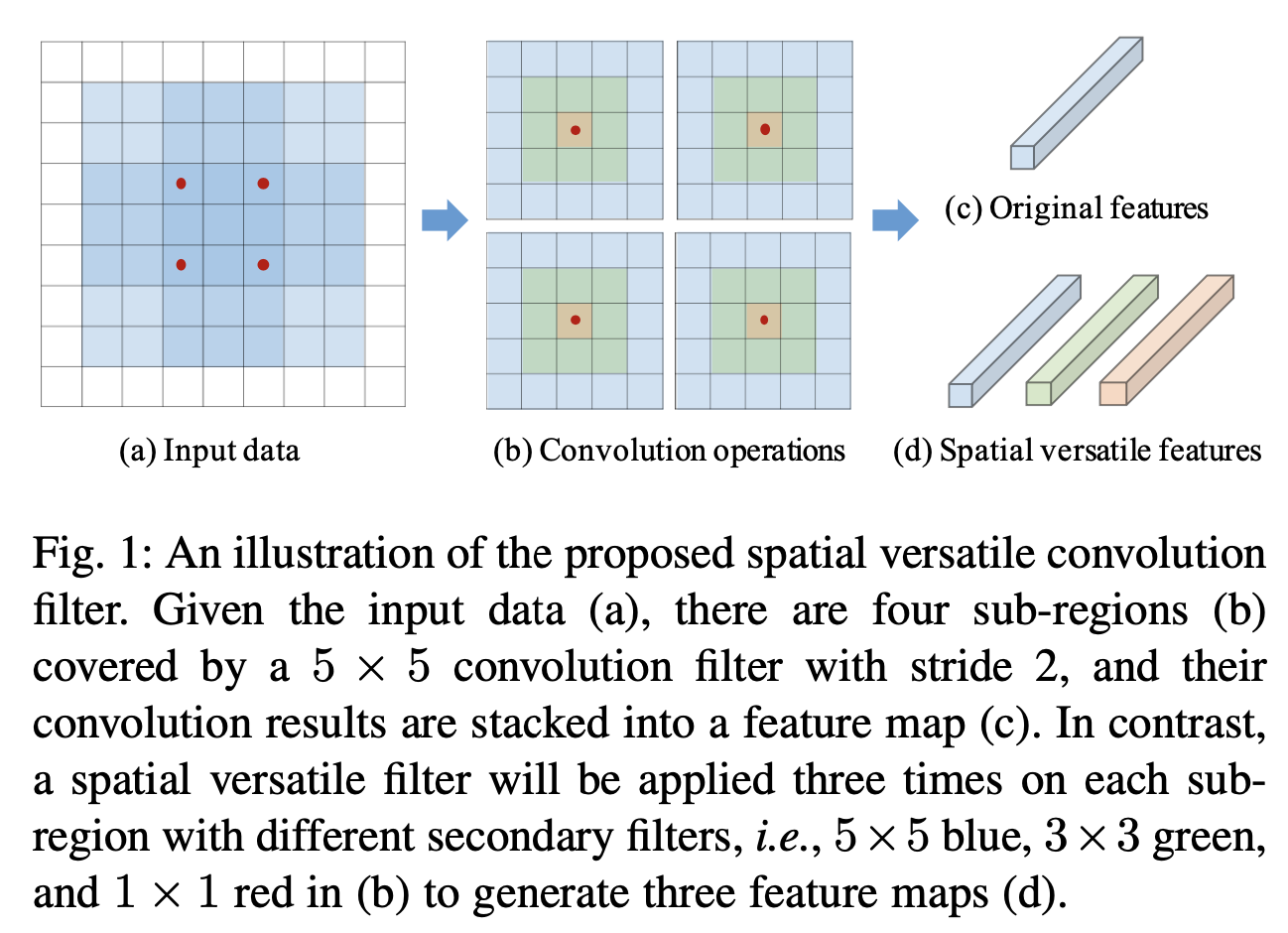
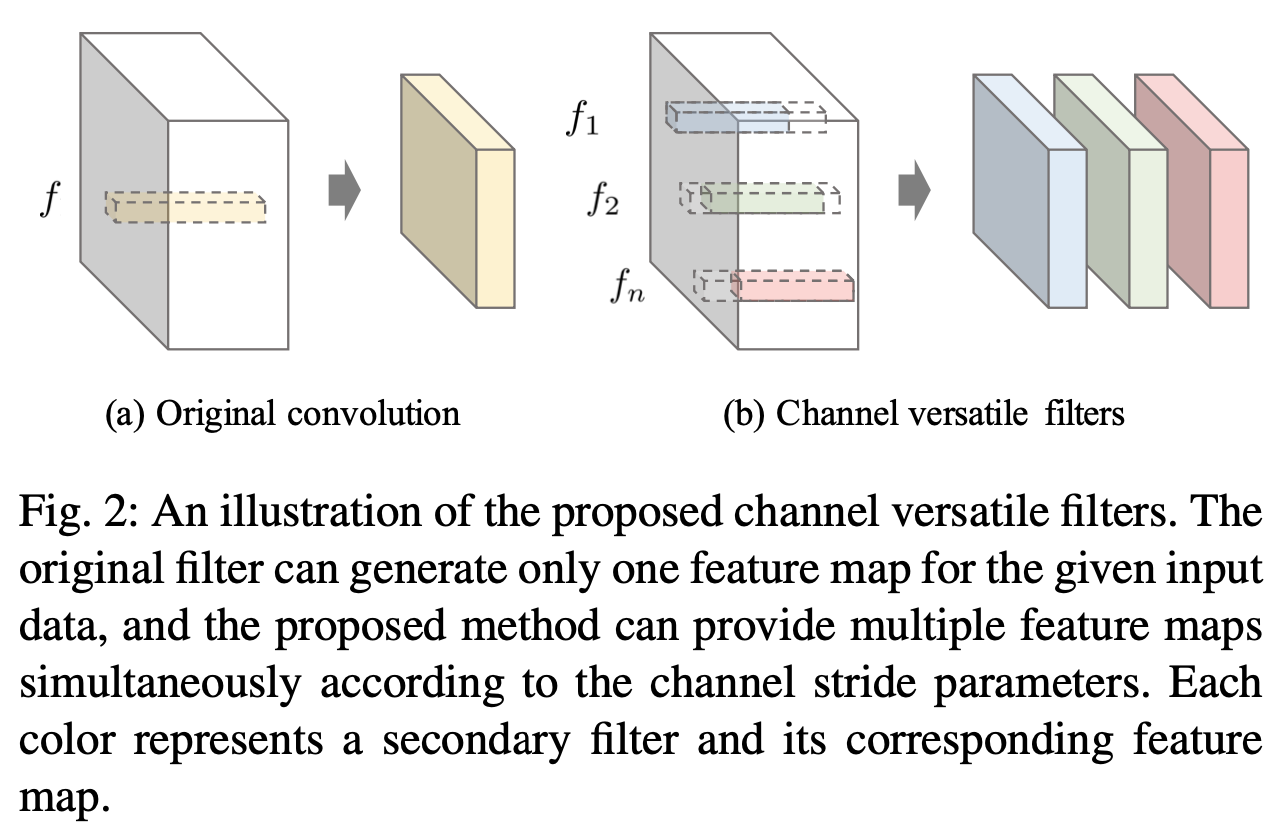
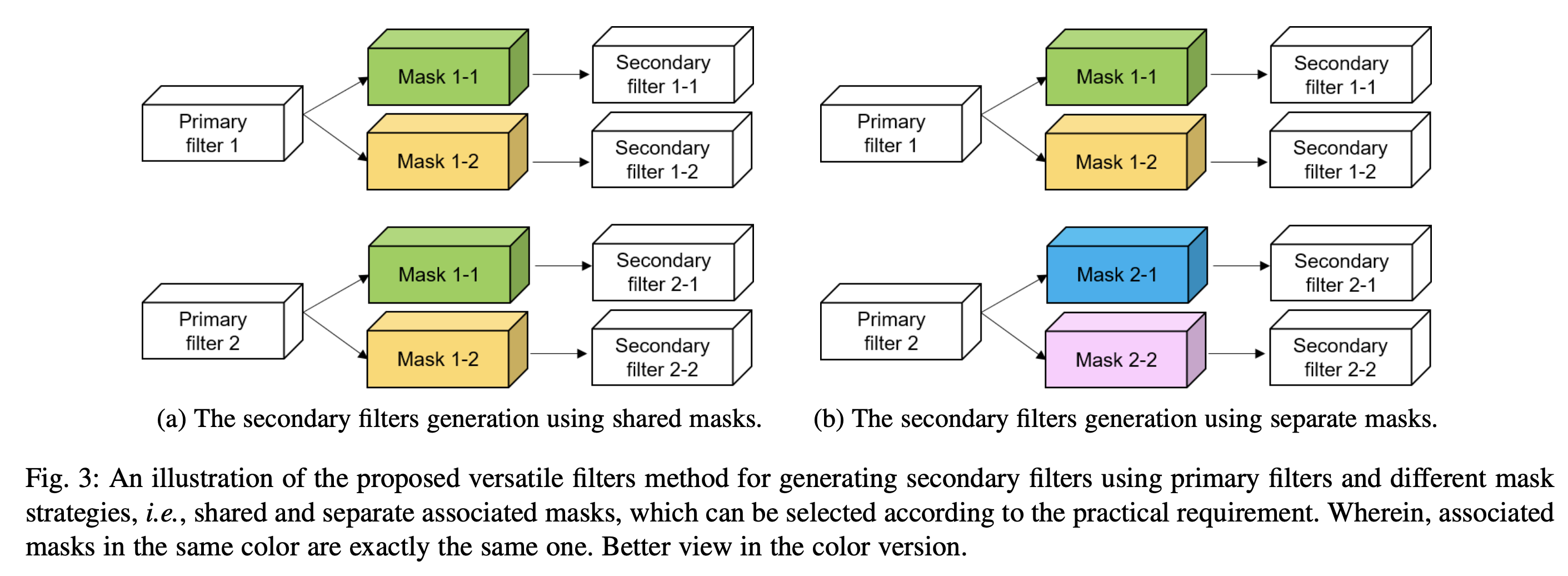
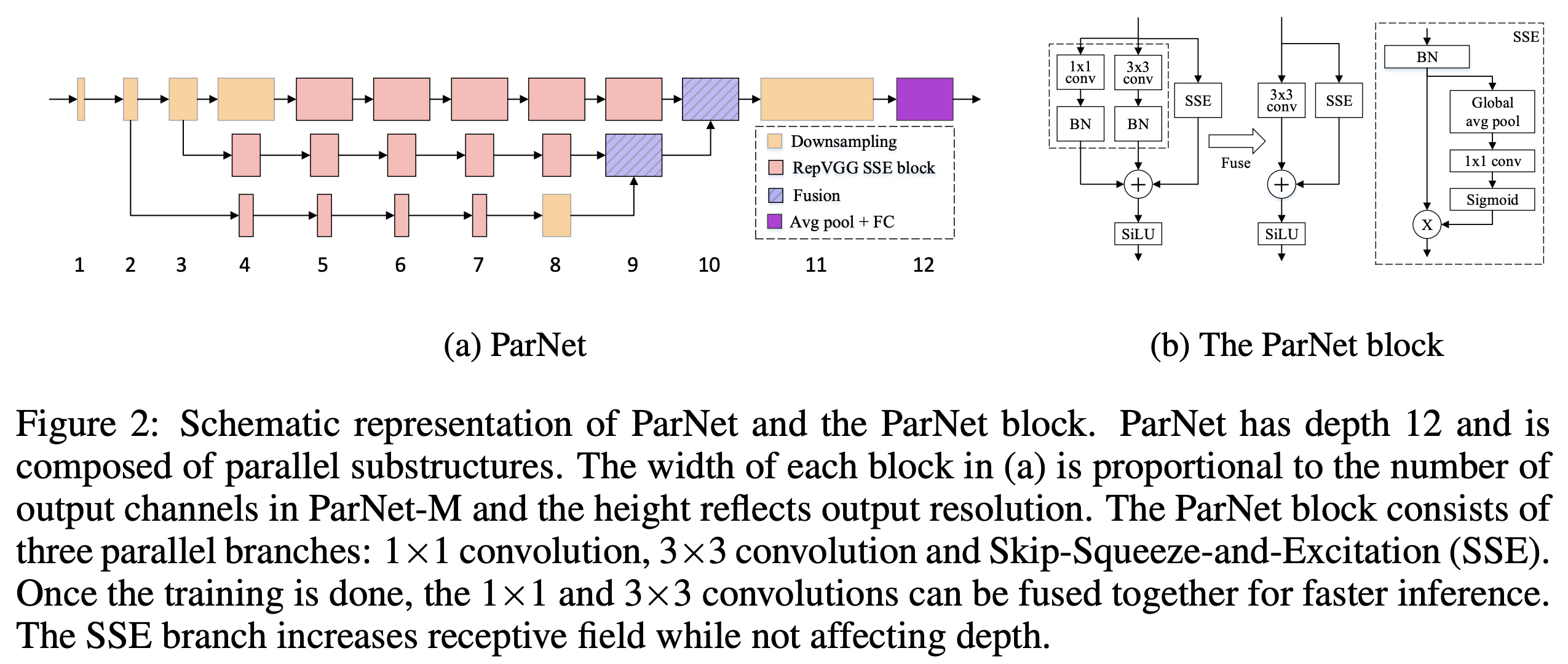
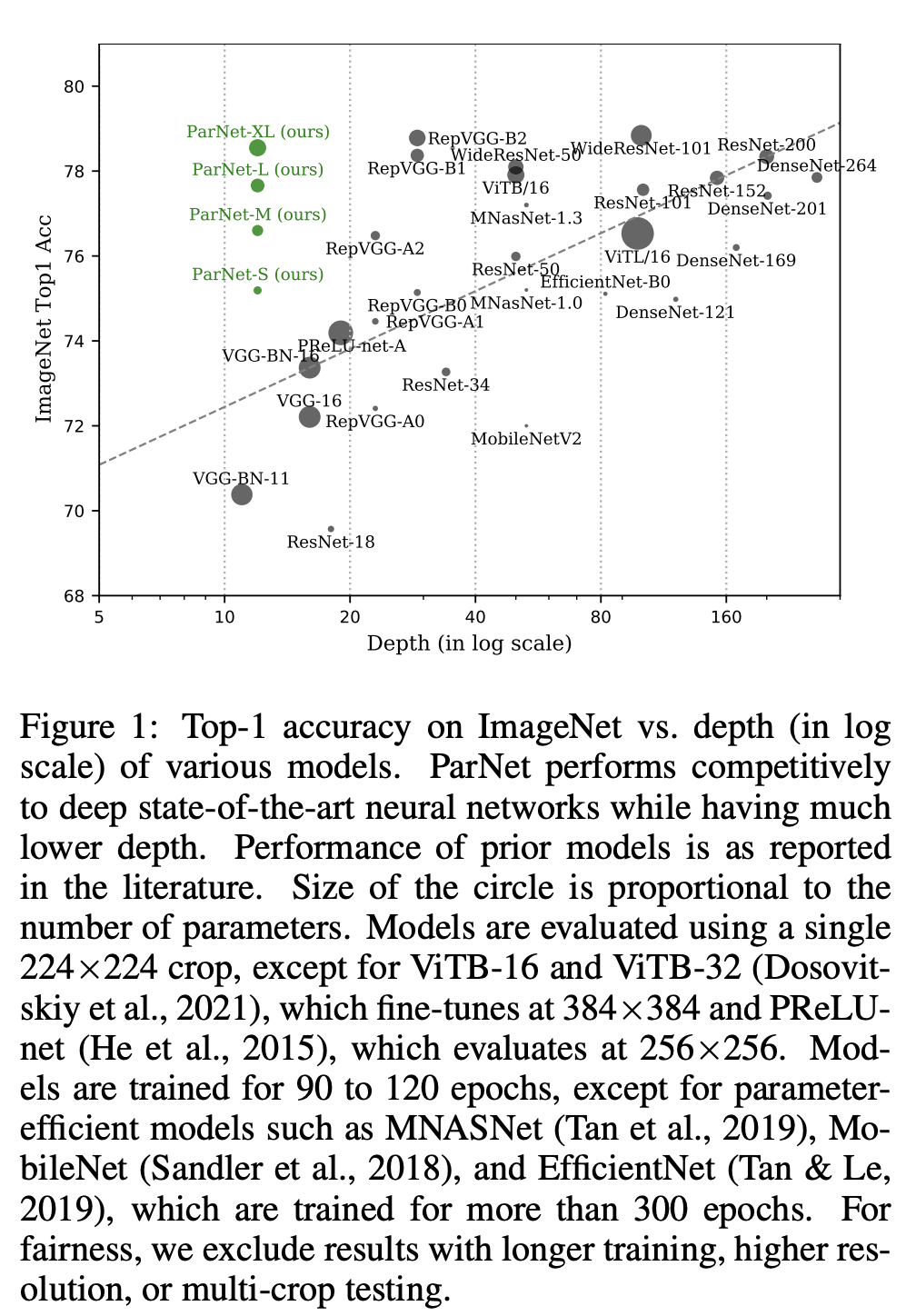
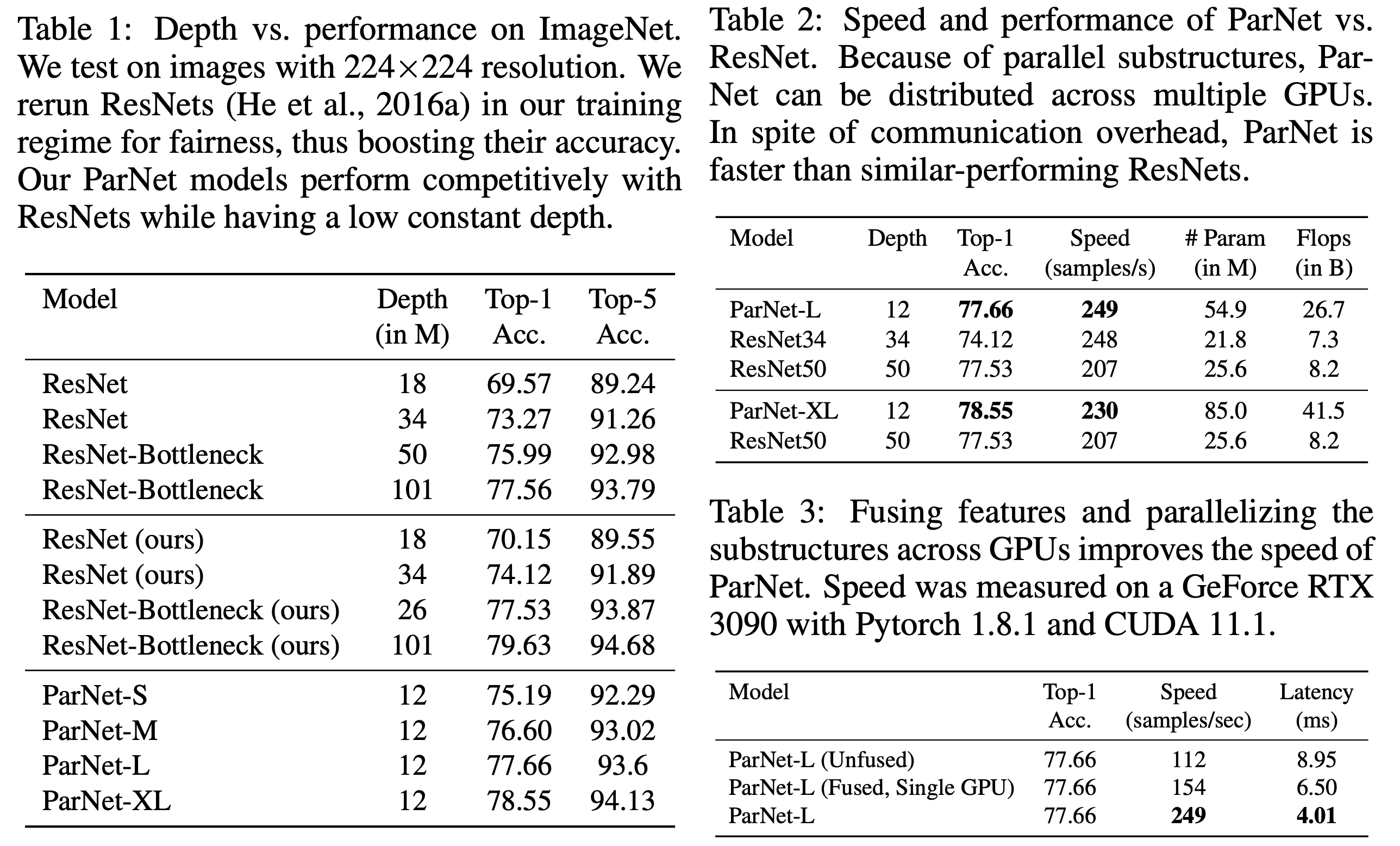
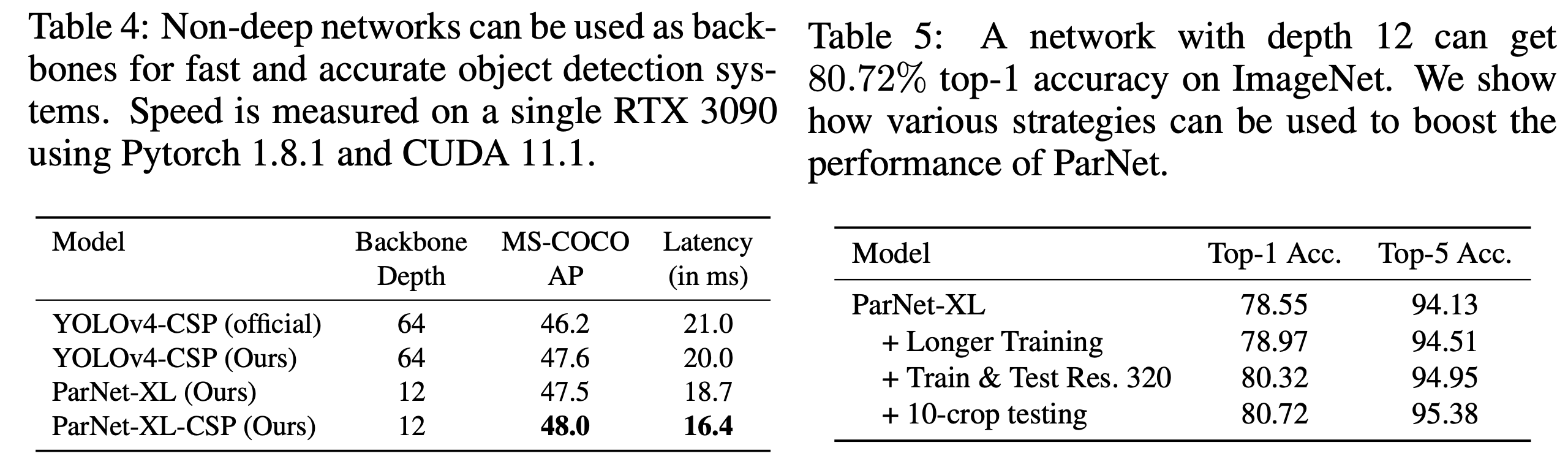
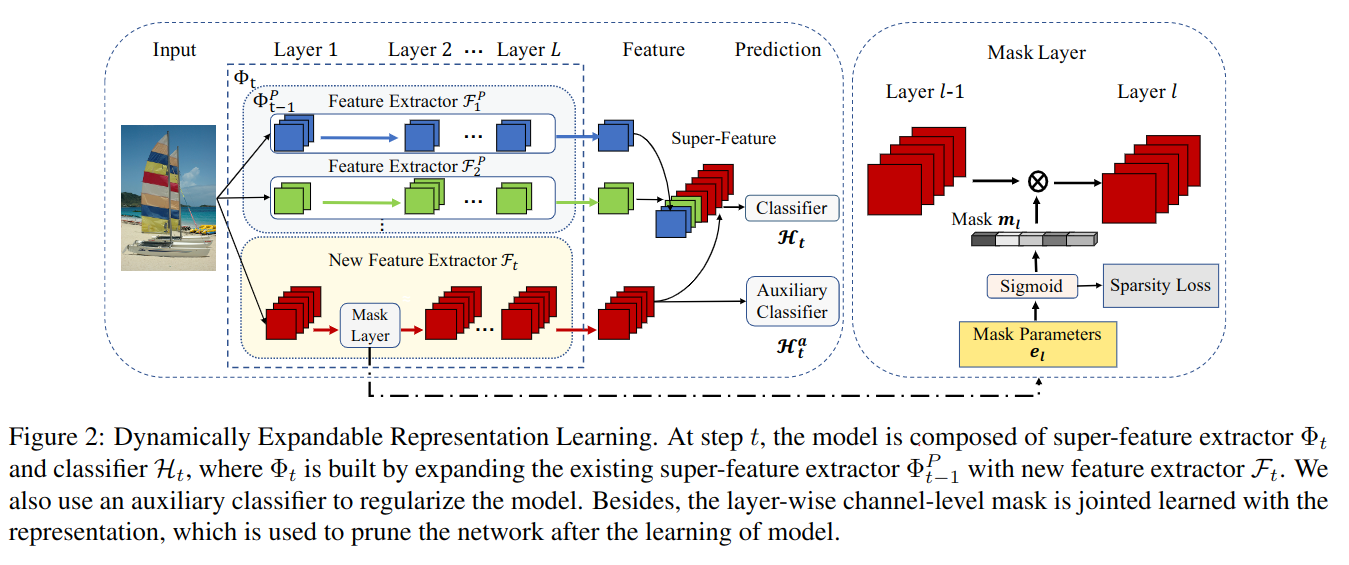
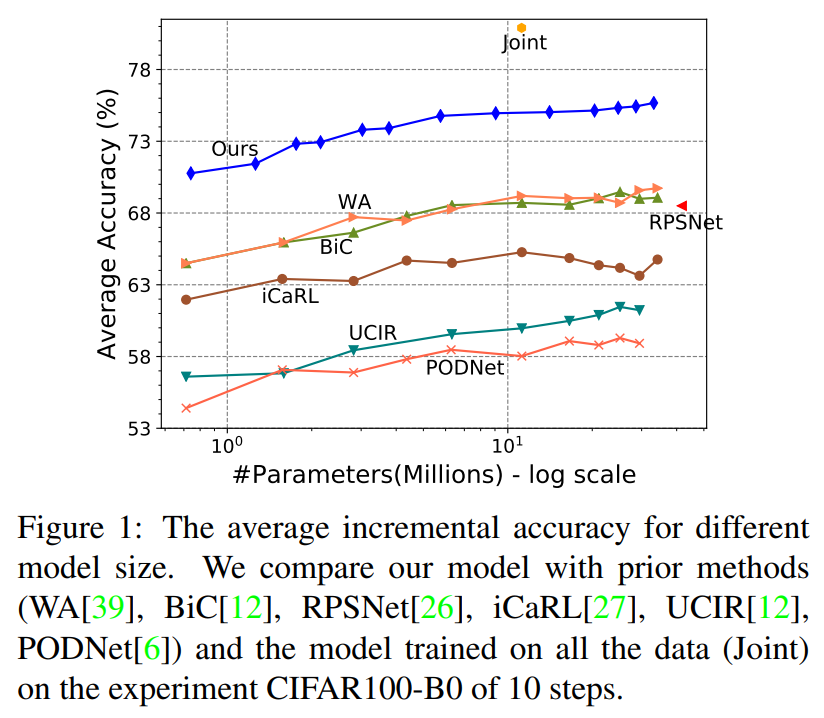
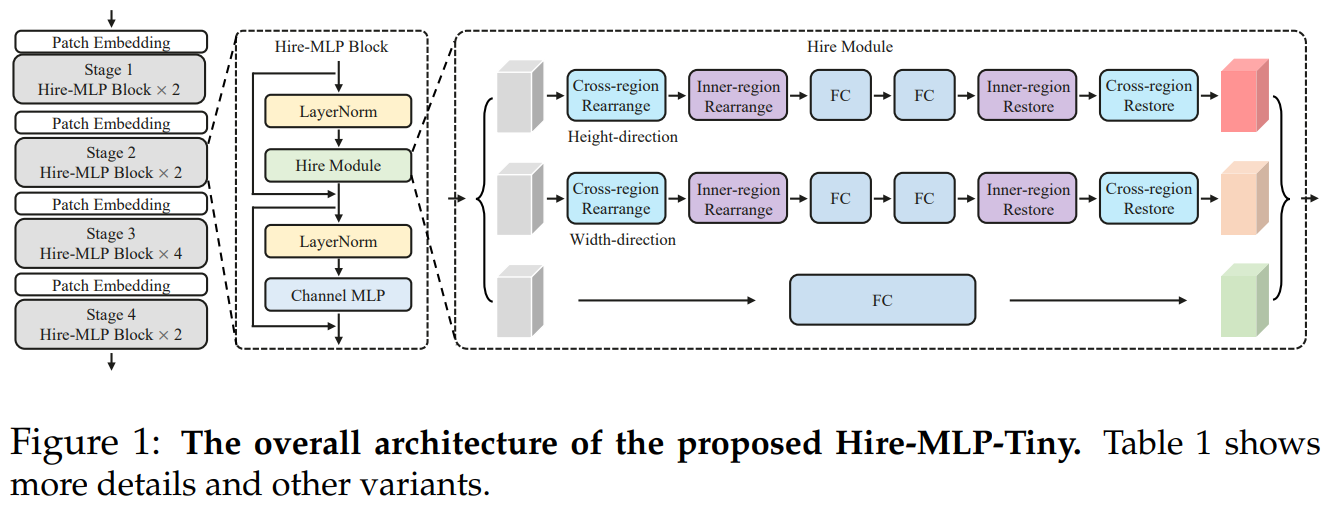
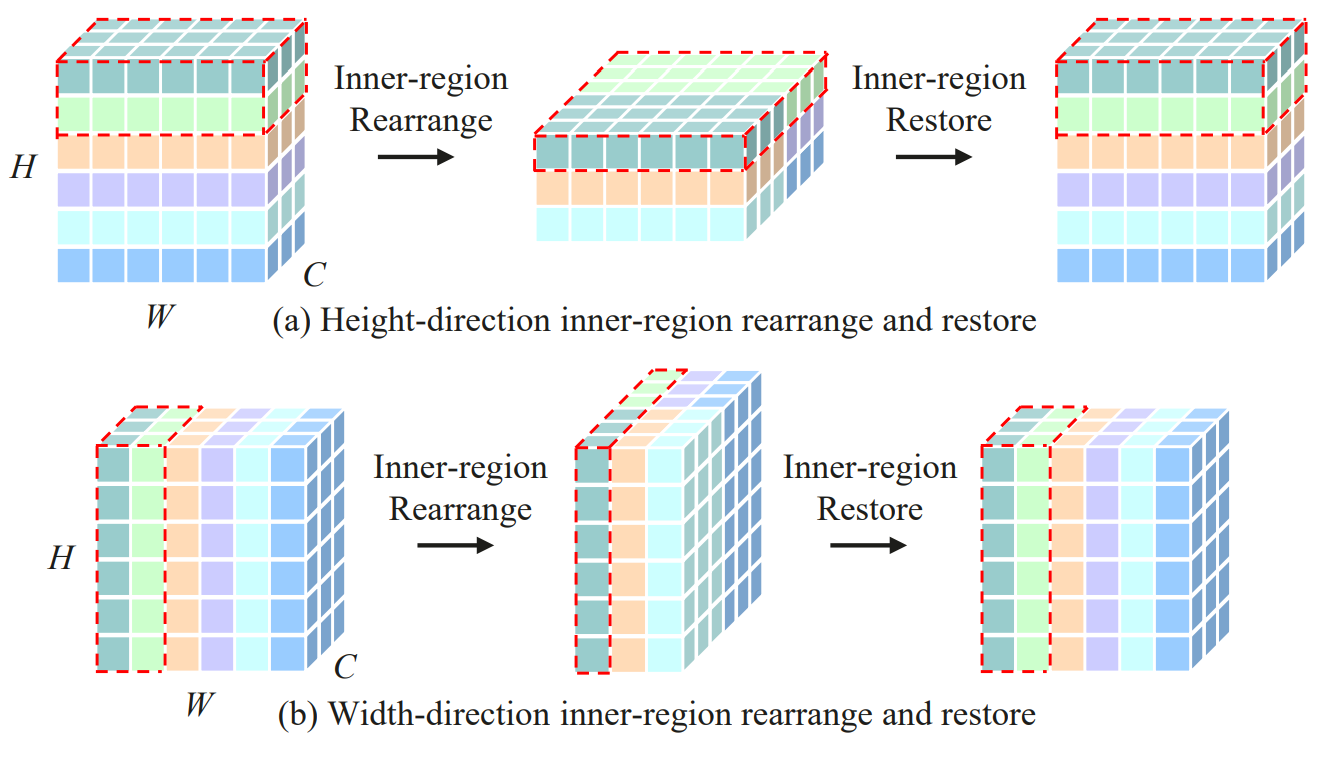
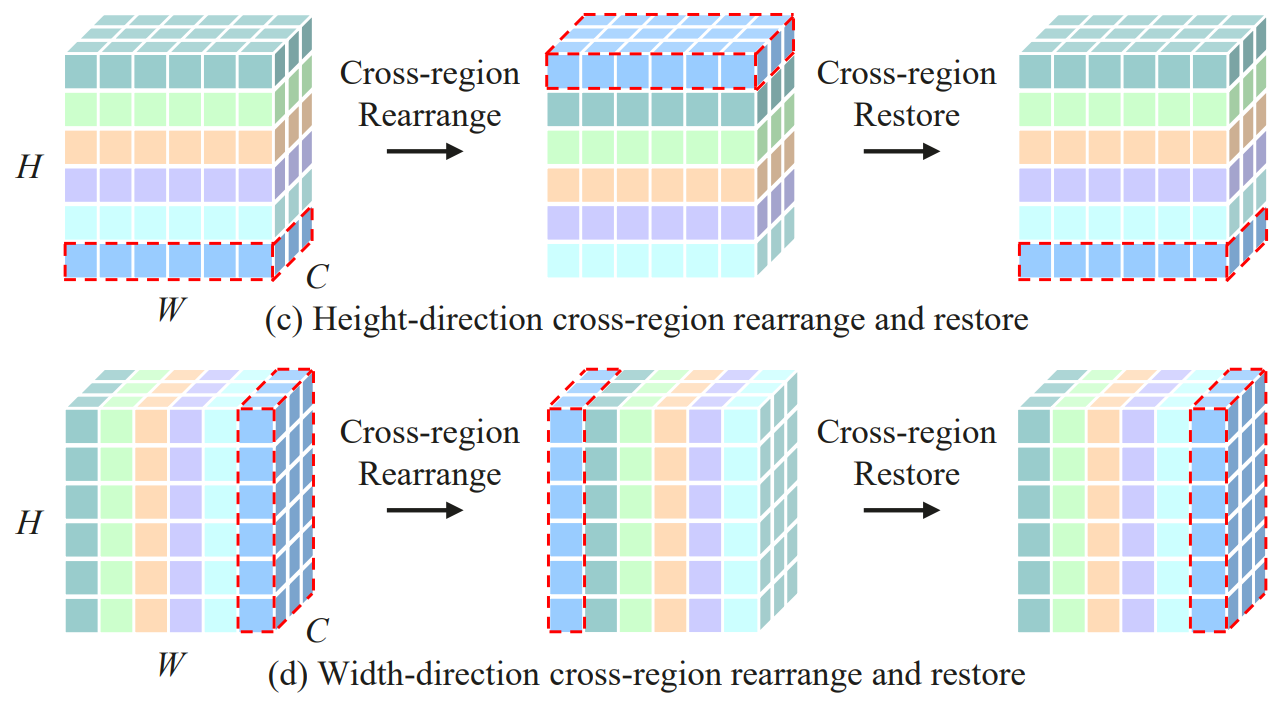
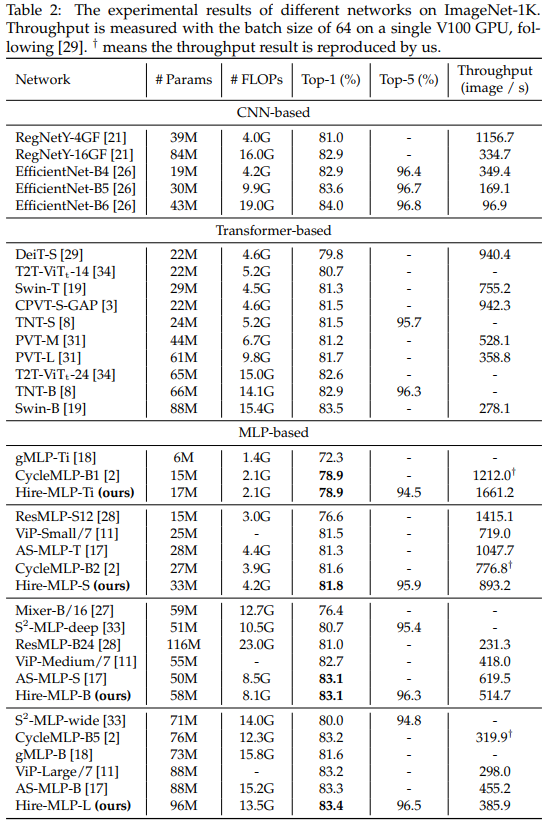
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import torch
inp = torch.randn(3, 4, 5, 6)
batchnorm = torch.nn.BatchNorm2d(num_features=4)
batchnorm.weight.shape
out = batchnorm(inp)
out.shape
out.permute(1,0,2,3).reshape(4, -1).mean(1).data
out.permute(1,0,2,3).reshape(4, -1).std(1).data
layernorm = torch.nn.LayerNorm(normalized_shape=(4, 5, 6))
layernorm.weight.shape
out = layernorm(inp)
out.shape
out.reshape(3, -1).mean(1).data
out.reshape(3, -1).std(1).data
instancenorm = torch.nn.InstanceNorm2d(num_features=4)
out = instancenorm(inp)
out.shape
out.reshape(12, -1).mean(1).data
out.reshape(12, -1).std(1).data
groupnorm = torch.nn.GroupNorm(num_groups=2, num_channels=4)
groupnorm.weight.shape
out = groupnorm(inp)
out.shape
out.reshape(6, -1).mean(1).data
out.reshape(6, -1).std(1).data
|